
Decision trees, one of the very popular data mining algorithm which is the next topic in our Data Mining series. In the previous article Introduction to SQL Server Data Mining, we discussed what data mining is and how to set up the data mining environment in SQL Server. Then in the next article, Microsoft Naïve Bayes algorithm was discussed. In this Article, Microsoft Decision Trees are discussed with examples. The Microsoft Decision Trees algorithm is a classification and regression algorithm that works well for predictive modeling. The algorithm supports the prediction of both discrete and continuous attributes.
What is Decision Trees
Decision Trees are one of the most common data mining algorithm. When you make a decision, you always tend to divide your problem. Let us say you want to go to one place from another place. To decide what time you should leave, you will have a lot of parameters in your mind. Depending on the day (weekend or weekday), type of mode of transport, time of traveling, and if there any special events, type of weather will decide the time. So when you decide on the time, there can combinations. For example, if it is raining, on a weekday, at a peak time, traveling time would be different for different combinations. All these combinations can be visualized into a tree format.
Following is an example of a Decision Tree, which discusses the mode of transport depending on another requirement.

Source: https://www.displayr.com/what-is-a-decision-tree/
As you can see from the above figure, decision trees are extremely easy to understand. That is the most common reason why the decision trees are popular among most of the users.
Microsoft Decision Trees in SSAS
In SQL Server, using data sets model can be built with Decision Tree algorithms and then predictions can be done from the built decision tree.
We will be using the same dataset vTargetMail view in the AdventureWorksDW database. As we discussed in the previous article, create a SSAS project in the Visual Studio. Then create a data source which will point to the AdventureworksDW database and DataSourceView in which vTargetMail is selected.
Next, create a mining structure and select the Microsoft Decision Trees as shown in the below figure.

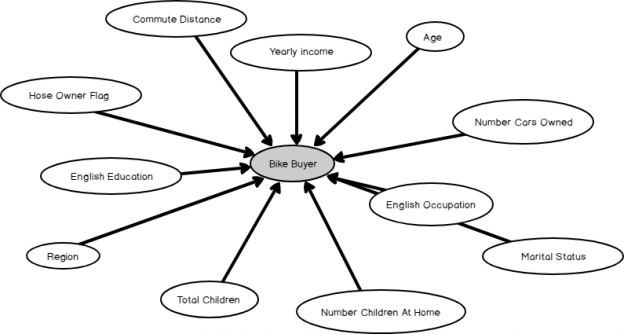
In the wizard, vMailTarget was selected as the case table. Next, is to select input and predicted columns. Since we are looking at predicting the bike buyer, BikeBuyer attribute is the predicted attribute.
Age, Commute Distance, Education, Occupation, Gender, House Owner Flag, Marital Status, Number Cars Owned, Number Children At Home, Region, Total Children, and Yearly Income are selected as input attributes as shown in the below figure.

It should be noted that attributes such as AddressLine1, AddressLine2, BirthDate, DateFirstPurchase attribute are not selected as it is obvious that those attributes will not make any impact on a customer becoming a bike buyer.
If you are not sure about what input attributes to be selected, by clicking From the Suggest button, you can get what are most impacted attributes as shown in the below figure. This has to be done after choosing the predictable attribute. Also, you can choose those attributes from this screen itself so that it will be reflected in the previous screen.

You will observe that there are a few attributes that cannot be selected from the suggested dialog. Still, you can choose those from the previous screen.
Next is to select content type as shown in the following image.

Apart from the Yearly income, all the other continuous data types were changed to Discrete. Especially, the predictable attribute was changed to Discrete Content-Type. When this is Discrete, this will become a classification problem and when the prediction attribute is continued it will become a Regression problem.
Decision Trees for Classification Problem
After choosing the correct content types, next is to provide the train and test data set parameters. After naming the model, next is to process and view the results.
Following is the Full graph view of the decision. Though the graph is not fully readable in this article, this is to understand how different attributes are contributed to the tree view.

Let us analyze the graph in more detail.

Data set is divided from the Number Cars Owned attribute. If a person owned 4 cars, the next parameter is Commute Distance, Yearly Income, and Total Children, etc.
Let us look at another tree node.

In this node, the second split is by the year income and split will be different depending on the year income.
Also, different nodes have different level. In the node of Year Income > 106,000 and what only matters are the Commute Distance and other parameters can be ignored.
Next look at one node.
The selected node is Number Cars Owned = 4 and Commute Distance = ‘0-1 Miles’ and the legend of the node is also shown below.

In this node, it is more probable that customers will not buy a bike as it has a probability of more than 83%. By looking at the node, from the colors you can get an idea of the distribution of the dataset with the predictable attribute.
Since there are many input attributes, it is important to understand the most weightage attributes. This can viewed from the Dependency Network.

By adjusting the Strongest Links, you can find out what are the most dependent attribute. You will find that the Number Cars Owned is the most important attribute which is why it is used as the first split in the decision tree.
Advantage of decision trees over the Naïve Bayes for classification is that Decision Trees can incorporate continuous attributes such as yearly income.
Decision Trees for Regression Problem
Let us see how Decision Trees can be used as a solution to a regression problem. There is no need to add another data mining structure whereas you can add another mining model from the Mining Model tab and change the input and prediction attributes as shown in the below image.

Next is to process the newly created model.
Following is the part of the decision tree for the regression problem.

Let us look at one node and its legend.

During the Classification problem, by looking at the node, you can get an idea about that node. In the regression problem also, by looking at the node, you can get an idea about the properties of that node. If the width of the diamond is high, this means that there is a high deviation in the predictable variable in the node.
If there are continuous attributes in the input, this yearly income will be a formula. Since in the selected example, all the attributes are discrete, the only value is assigned for the node. In this node the value is 66,837.607. This means a client with English Occupation = ‘Professional’ and Number Children At Home = 1 and Total Children not = 5 and Region = ‘North America’ and Number Cars Owned = 1 and Age not = 65 will have an annual income of 66,837.607.
Model Parameters
As discussed in the previous article, model parameters can be changed so that the model can be further improved to better results.
Model attributes, default value, range are shown in the Model Parameter dialog box.

Complexity Penalty
Decreasing the value increases the likelihood of a split while increasing the value decreases the likelihood. The default value is based on the number of attributes for a given model. If there is 1 to 9 attributes default is 0.5 and it will be 0.9 if there are 10 to 99 attributes, and the default is 0.99 if there are 100 or more attributes.
Force Regressor
This parameter forces the algorithm to use the indicated columns as regressors in the regression formula regardless of their importance as calculated by the algorithm. This parameter is only used for regression trees. This parameter is only available in the Enterprise Edition of the SQL Server.
Maximum Input Attributes
This parameter specifies the maximum number of input attributes that the algorithm can handle before invoking feature selection. Setting this value to 0 disables feature selection for input attributes. This parameter is only available in the Enterprise Edition of the SQL Server.
Maximum Output Attributes
This parameter the maximum number of output attributes that the algorithm can handle before invoking feature selection. Setting this value to 0 disables feature selection for output attributes. This parameter is only available in the Enterprise Edition of the SQL Server.
Minimum Support
This parameter specifies the minimum number of cases that a leaf node must contain. Setting this value to less than 1 specifies the minimum number of cases as a percentage of the total cases. Setting this value to a whole number greater than 1 specifies the minimum number of cases as the absolute number of cases.
Score Method
This Specifies the method used to calculate the split score. The available methods are Entropy (1), Bayesian with K2 Prior (3), or Bayesian Dirichlet Equivalent with Uniform prior (4).
Split Method
Specifies the method used to split the node. The available methods are Binary (1), Complete (2), or Both (3).
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021