
In this article, we are going to learn some best practices that help to write more efficient SQL queries.
Introduction
Queries are used to communicate with the databases and perform the database operations. Such as, we use the queries to update data on a database or retrieve data from the database. Because of these functions of queries, they are used extensively by people who also interact with databases. In addition to performing accurate database operations, a query also needs to be performance, fast and readable. At least knowing some practices when we write a query will help fulfill these criteria and improve the writing of more efficient queries.
Pre-requisites
In this article’s examples, we will use the Adventureworks2019 sample database.
Deciding the appropriate SQL editor to write queries
Whatever our experience in writing queries, deciding on an appropriate editor is one of the key points that will affect our productivity because, during the development of SQL queries, we mostly consume our time in the SQL editors. Preference of the SQL editor can be changed from person to person but before to decide an editor checking the features of the editor and looking at the feature comparison with its competitors will help to decide on the proper editors. In this context, Microsoft offers two different tools to develop queries:
These two tools have some advantages and disadvantages, but the main advantage of the Azure Data Studio is to can work on different platforms (Linux and macOS) and it offers a more user-friendly user interface for professionals who commonly develop queries. At the same time, the extensions allow us to add new features to it. Despite this, SQL Server Management Studio helps to manage and maintain the database administrators’ operation more easily and offers a more advanced SQL query development environment. So, if we mostly consume our time developing SQL queries, using the Azure Data Studio can be more reasonable. Except then these two tools, we can also use other editors which are developed by lots of vendors.
Best Practice: As much as possible as a preference to use the proper editor for your requirements and you can consider using either 3rd party add-ins or extensions that improve the capabilities of the editors.
Avoid using the asterisk sign (SELECT *) in the select SQL queries
Using the SELECT * statements in the queries may cause unexpected results and issues in the queries’ performance. Using an asterisk sign in a query causes redundant consumption of the database engine’s resources because it will retrieve all columns of the table. In particular, using SELECT * provokes consuming more network and disk resources. Another problem with using the SELECT * sign is to be facing unexpected result sets because:
- Column names can be changed
- New columns can be added
- The columns’ order can be changed
To prevent these types of problems, we need to explicitly write the column names in our SQL queries. For example, the following query will retrieve all column data of the Employee table.
|
1 2 3 |
SELECT * FROM HumanResources.Employee |

However, we can transform this query correctly by explicitly defining the column names as follows and including only the columns which we needed.
|
1 2 3 4 5 6 7 8 9 |
SELECT BusinessEntityID , NationalIDNumber , JobTitle , BirthDate , MaritalStatus , SickLeaveHours FROM HumanResources.Employee |
Using the SELECT * statement will cause performance problems.
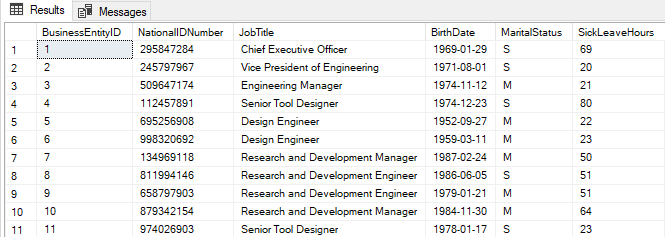
Best Practice: Besides getting rid of SELECT * statements and using the column names explicitly in the SQL queries, we can use the alias names for the tables and column names. This usage type makes our queries more readable and easily understandable.
|
1 2 3 4 5 6 7 8 9 |
SELECT Emp.BusinessEntityID AS [Bussines Entity Id] , Emp.NationalIDNumber AS [National Number] , Emp.JobTitle AS [Job Title] , Emp.BirthDate AS [Birth Date] , Emp.MaritalStatus AS [Martial Status] , Emp.SickLeaveHours AS [Sick Leave Hours] FROM HumanResources.Employee Emp |
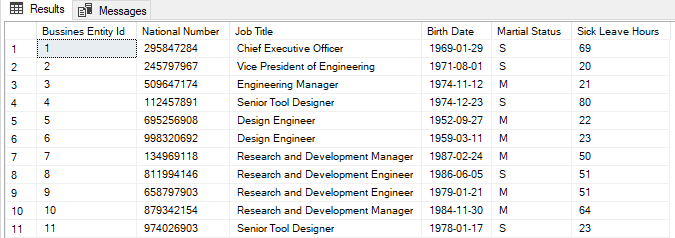
Add the requisite comments to the SQL queries
SQL comments are the plain text that can be added to the queries, and they are not parsed and executed by the query engine. Mostly, we use the comments either to add some description or disable some code blocks of the queries. However, adding brief and understandable explanations to our SQL queries is one best practice because, over time, the purpose of the query and its use by the which application can be forgettable. In this case, the process of maintaining and refactoring the query will be a bit painful.
Single-line comment:
To change a line as a comment, we can add the two dashes (–) at the beginning of the query line, thus this line color will be changed, and these lines will not be considered by the query engine.
|
1 2 3 4 5 6 7 8 9 10 11 |
-- This query returns the whole employee data SELECT Emp.BusinessEntityID , Emp.NationalIDNumber , Emp.JobTitle , Emp.BirthDate , Emp.MaritalStatus , Emp.SickLeaveHours FROM HumanResources.Employee Emp |
Multiple line comment:
By placing multiple lines inside this sign () block, we can convert them into multiple comment lines.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
/* This query returns the whole employee data. Created by Esat Erkec The human resource portal uses this query */ SELECT p.FirstName AS [First Name] , p.LastName AS [Last Name] , e.BirthDate AS [Birth Date] FROM [HumanResources].[Employee] e INNER JOIN [Person].[Person] AS p ON p.[BusinessEntityID] = e.[BusinessEntityID] |
Best Practice: As possible as standardize your SQL comments and add all short information that you required according to your development process. For example, you can use the following template:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
/* ------------------------------------------------------------------------------- ############################################################################## ------------------------------------------------------------------------------- Author: Name Create Date: Date Purpose: Description of the business/technical details. You can use multiple lines if needed ------------------------------------------------------------------------------- -- Summary of Changes -- Jira or another number -- 01/01/0000 Developer Name full name -- A comprehensive description of the changes. The description may use as -- many lines as needed. */ ------------------------------------------------------------------------------- ############################################################################## ------------------------------------------------------------------------------- |
Consider NULLable columns in SQL queries
A NULL value in a row specifies an unknown value and this value does not point to a zero or empty value. Because of this particular characteristic of the NULL value, we need to take into account nullable columns in the queries.
Comparing the NULL values:
When we either filter out the NULL or exclude NULL rows in a query, we cannot use the use equality operator (=) in the WHERE clause. The proper way to compare the NULL values is to use IS NULL and IS NOT NULL operators. For example, if we want to return only NULL values from the Address table, we can use the following query:
|
1 2 3 4 5 6 7 |
SELECT Address.AddressLine1 AS [Adress 1] , Address.AddressLine2 AS [Adress 2] , City AS [City] FROM Person.Address Address WHERE Address.AddressLine2 IS NULL |
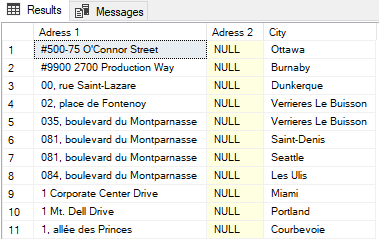
When we use the equality operator (=) in the WHERE clause, we do not get the appropriate result set.
|
1 2 3 4 5 6 7 |
SELECT Address.AddressLine1 AS [Adress 1] , Address.AddressLine2 AS [Adress 2] , City AS [City] FROM Person.Address Address WHERE Address.AddressLine2 = NULL |
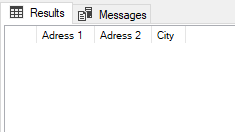
COUNT() function and NULLable columns:
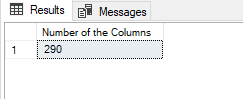
The COUNT() function counts and returns the number of columns from the query result set. However, the COUNT(*) function counts all rows of the query resultset but if we replace the column name with the asterisk sign COUNT(column_name), the function counts only the non-null values. For example when we use the asterisk (*) for the COUNT function to count the Employee table rows, we will obtain 290.
|
1 2 3 4 |
SELECT COUNT(*) AS [Number of the Columns] FROM HumanResources.Employee |
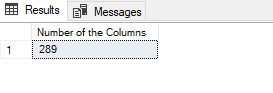
However, if we use the column name instead of the asterisk sign the COUNT function returns a different value.
|
1 2 3 4 |
SELECT COUNT(OrganizationLevel) AS [Number of the Columns] FROM HumanResources.Employee |
Beautify SQL Queries
The queries which we write will never remain a secret and will need to be reviewed and modified by us or by other developers because they might need to test, fix or add a new feature. Because of this case, the queries we write should be as understandable and easy to read as possible. Following the suggestions below for writing more readable code will help us write more readable code.
1-Format SQL Queries: Formatting the queries is one of the important points to improve the readability of a query. A well-formatted query always significantly improves code readability. To make our queries more readable, we can take advantage of online query formatting tools or add-ins (extensions). For example, we can see the mess and complexity of the following query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
DECLAre @NewValue as varchar(100)declare @I AS INT=0 if OBJECT_ID( N'tempdb..#NewTempTable')is nOT NULL BEgin dROP TABLE #NewTempTable END CREATe table #NewTempTable(Id inT,Column1 INT) IF @NewValue<=0WHILE @I<=10 BEgiN INSErt inTO #NewTempTable valUEs( @NewValue,@NewValue*100)seT @I=@I+1 END IF @NewValue>0 begin select p.ProductID,p. ProductNumber,p.Name,s. CarrierTrackingNumber,h.AccountNumber,h. CreditCardApprovalCode,dbo.[ufnGetStock](p.ProductID)as Stock,case when AccountNumber likE'10%' THEN'Account New'ELSE'Account Old'END As 'AccountRename' ,concat(Substring( CarrierTrackingNumber ,1,4),Substring(p.Class,1,4))froM Sales.SalesOrderDetailEnlarged s Inner jOIN Production.Product p On s.ProductID=p.ProductID inNER JOin Sales. SalesOrderHeaderEnlarged h on h.SalesOrderID=s.SalesOrderID where s.OrderQty>2aND LEN( CreditCardApprovalCode)>10ORDer by conCAT(Substring(CarrierTrackingNumber,1, 4),Substring(p.Class,1,4)),ProductID desc end SELECT Id AS [Product Id] FROM #NewTempTable |
Now, we will format this code through the Poor SQL format and we can see the stunning change in the query, or you can choose the formatter that suits your needs.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
DECLARE @NewValue AS VARCHAR(100) DECLARE @I AS INT = 0 IF OBJECT_ID(N'tempdb..#NewTempTable') IS NOT NULL BEGIN DROP TABLE #NewTempTable END CREATE TABLE #NewTempTable ( Id INT , Column1 INT ) IF @NewValue <= 0 WHILE @I <= 10 BEGIN INSERT INTO #NewTempTable VALUES ( @NewValue , @NewValue * 100 ) SET @I = @I + 1 END IF @NewValue > 0 BEGIN SELECT p.ProductID , p.ProductNumber , p.Name , s.CarrierTrackingNumber , h.AccountNumber , h.CreditCardApprovalCode , dbo.[ufnGetStock](p.ProductID) AS Stock , CASE WHEN AccountNumber LIKE '10%' THEN 'Account New' ELSE 'Account Old' END AS 'AccountRename' , CONCAT ( Substring(CarrierTrackingNumber, 1, 4) , Substring(p.Class, 1, 4) ) FROM Sales.SalesOrderDetailEnlarged s INNER JOIN Production.Product p ON s.ProductID = p.ProductID INNER JOIN Sales.SalesOrderHeaderEnlarged h ON h.SalesOrderID = s.SalesOrderID WHERE s.OrderQty > 2 AND LEN(CreditCardApprovalCode) > 10 ORDER BY CONCAT ( Substring(CarrierTrackingNumber, 1, 4) , Substring(p.Class, 1, 4) ) , ProductID DESC END SELECT Id AS [Product Id] FROM #NewTempTable |
2-Use aliases for the column and table names: We can use the alias to rename the column and table names so that we can make them more readable. For example, in the following example, the query does not use table and column allies for this reason it seems messy and difficult to read.
|
1 2 3 4 5 6 7 8 |
SELECT Product.ProductID, Product.Name , WorkOrder.WorkOrderID ,WorkOrderRouting.ActualCost,WorkOrder.StockedQty from Production.WorkOrder INNER JOIN Production.WorkOrderRouting on Production.WorkOrder.WorkOrderID = Production.WorkOrderRouting.WorkOrderID INNER JOIN Production.Product ON Production.Product.ProductID = Production.WorkOrder.ProductID |
Now, we will use aliases for the column names and table names to further format it.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT Product.ProductID AS [Product Id] , Product.Name AS [Product Name] , WorkOrder.WorkOrderID AS [WorkOrder Id] , Routing.ActualCost AS [Actual Cost] , WorkOrder.StockedQty AS [Stocked Quantity] FROM Production.WorkOrder WorkOrder INNER JOIN Production.WorkOrderRouting Routing ON WorkOrder.WorkOrderID = Routing.WorkOrderID INNER JOIN Production.Product Product ON Product.ProductID = WorkOrder.ProductID |
As we can see there is a noticeable readability improvement after using and formatting the query.
Best Practice: If you want to write more readable and understandable queries:
- Use understandable aliases for the table names
- Add brief comments to queries
- Consider using Common Table Expressions (CTE) in your complex queries
- Variable names should be clear and concise
- Format the queries before deploying
Summary
In this article, we learned some best practices that help to improve the quality of SQL queries. Well-formatted, more readable, and performant queries will always help us or another person who needs to review or modify the queries.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023