With the introduction of SQL Server 2016, Microsoft introduced many new features which had taken SQL Server another step forward and they made sure that it stands in front among many major Relational Database Systems.
One such feature which has been lacking but desperately required was the native support towards JSON.
Before SQL Server 2016, there were many other databases which already had the support for JSON.
PostgreSQL, Oracle, and MongoDB are few to be mentioned among many other databases which support JSON natively.
What’s JSON?
JSON is an acronym which stands for JavaScript Object Notation. It has been a very popular among web developers due to many of its features. Being lightweight and easily readable (since it’s text based) had made JSON extremely popular in web development.
What are the functions introduced to support JSON in SQL 2016 ?
A few functions have been introduced with SQL 2016 in order to support JSON natively in SQL Server 2016. These functions are:
- ISJSON
- JSON_VALUE
- JSON_QUERY
- JSON_MODIFY
- OPENJSON
- FOR JSON
**Note: Unlike XML, in SQL Server there’s no specific data type to accommodate JSON. Hence we need to use NVARCHAR.
We will go bit deep into the functions individually.
First we will see how we should declare a variable and assign a JSON string to it.
|
1 2 3 4 5 6 7 8 |
DECLARE @vJson AS NVARCHAR(4000) = N'{"EmployeeInfo": { "FirstName": "John", "LastName": "Doe", "Dob": "12-Jan-1970", "AnnualSalary": 85000 }}’ |
It’s simple as assigning a string value to a NVARCHAR type variable.
Now we will look more closely into each of the functions which mentioned previously. We will see what it does and how we can use them in our T-SQL statements.
ISJSON Function
This is the simplest of the functions for JSON support in SQL Server. It takes one string argument as the input, validate it and returns a BIT; 1 if the provided JSON is a valid one or returns 0 if it doesn’t.
If the provided input argument is NULL then the return value will also be NULL.
Syntax:
|
1 2 3 |
ISJSON(@input) |
Example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DECLARE @vJson AS NVARCHAR(4000) = N'{"EmployeeInfo": { "FirstName": "John", "LastName": "Doe", "Dob": "12-Jan-1970", "AnnualSalary": 85000 } }’ IF (ISJSON(@vJson)) PRINT ‘Valid JSON’ ELSE PRINT ‘Invalid JSON’ |
When this statement is executed you can see that it returns 1, since the provided JSON string is a valid one.
However there’s a concern when it comes to validate using ISJSON. That is ISJSON will not validate whether the key is unique or not.
Example:
We will use the same JSON string but this time we will duplicate the key ‘FirstName’.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
DECLARE @vJson AS NVARCHAR(4000) = N'{"EmployeeInfo": { "FirstName": "John", "FirstName": "John", "LastName": "Doe", "Dob": "12-Jan-1970", "AnnualSalary": 85000 } }’ IF (ISJSON(@vJson)) PRINT ‘Valid JSON’ ELSE PRINT ‘Invalid JSON’ |
If you execute the above code, you will still get the return value as 1, even the JSON string is containing a duplicate key. Most of the JSON validators will find these kind of JSON strings as invalid. (E.g: http://jsonlint.com/)
Further reading can be done on ISJSON (Transact-SQL)
JSON_VALUE Function
JSON_VALUE will return a scalar value from a JSON string for a requested key. To illustrate this we will use a different JSON string which contains an array.
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE @vJson AS NVARCHAR(4000) = N'{ "EmployeeInfo": {"FirstName": "John", "LastName": "Doe", "Dob": "12-Jan-1970", "AnnualSalary": 85000 }, "Dependants": [ {"DepType":"Wife","DepName":"Jane","DepAge":30}, {"DepType": "Son","DepName": "James","DepAge": 12} ]}' |
Using the above details will fetch the employee’s first name and the name of employee’s son. We can do this using the below shown syntax.
|
1 2 3 4 |
SELECT JSON_VALUE(@vJson,'$.EmployeeInfo.FirstName') AS EmployeeName SELECT JSON_VALUE(@vJson,'$.Dependants[1].DepName') AS EmployeeSonName |
This will return ‘John’ and ‘James’ respectively. There are few things to be noted here.
- The array index starts with zero. Hence we need to say we want the 1st index in order to get son’s name which is the second element. If the index is out of the range it will return a NULL
- The JSON path is case sensitive. Therefore it should match exactly with what you have on the JSON string. If the path is not found it will return NULL.
As an example both these will return NULL.
|
1 2 3 4 |
SELECT JSON_VALUE(@vJson,'$.EmployeeInfo.firstName') AS EmployeeName SELECT JSON_VALUE(@vJson,'$.Dependants[0].DepName') AS EmployeeSonName |
But at times we require knowing why it is returning NULL. It could be a possibility where the underlying value for that JSON path is having a NULL value. So in order to distinguish between these, we need to include ‘strict’ keyword before the JSON path.
|
1 2 3 |
SELECT JSON_VALUE(@vJson,'strict $.EmployeeInfo.firstName') AS EmployeeName |
Executing this will result with the following error message:

JSON_QUERY Function
JSON_QUERY function will extract and return details as an array string from a given JSON string. In order to illustrate this we will use the same JSON string which we used in the previous example.
|
1 2 3 4 5 |
SELECT JSON_QUERY(@vJson,'$.EmployeeInfo') SELECT JSON_QUERY(@vJson,'$.Dependants') SELECT JSON_QUERY(@vJson,'$.Dependants[0]') |
The first query will return details which is under EmployeeInfo path.
|
1 2 3 4 5 |
{"FirstName": "John", "LastName": "Doe", "Dob": "12-Jan-1970", "AnnualSalary": 85000 } |
The second query will return details which is under Dependents path.
|
1 2 3 4 5 6 |
[ {"DepType":"Wife","DepName":"Jane","DepAge":30}, {"DepType": "Son","DepName": "James","DepAge": 12} ] |
The third query will return details related to the first element under Dependants path. Hence it will return only the first detail set unlike the one above.
|
1 2 3 |
{"DepType":"Wife","DepName":"Jane","DepAge":30} |
JSON_MODIFY Function
This is very similar to the xml.modify() functionality available in SQL Server. JSON_MODIFY function will be used to append an existing value on a property in a JSON string. Even though the name reflects an idea of modifying an existing value, it can be used in three ways.
- To update a value
- To delete a value
- To insert a value
Update a property value on JSON string using JSON_MODIFY function
First, we will see how we can update an existing JSON property value using JSON_MODIFY function. You need to provide two things when updating.
- Exact path of the property
- The value which should be updated.
Example:
We will consider the same JSON details which we used above and update the first name and the last name to ‘James Williams’ respectively.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DECLARE @vJson AS NVARCHAR(4000) = N'{ "EmployeeInfo": {"FirstName": "John", "LastName": "Doe", "Dob": "12-Jan-1970", "AnnualSalary": 85000 }, "Dependants": [ {"DepType":"Wife","DepName":"Jane","DepAge":30}, {"DepType": "Son","DepName": "James","DepAge": 12} ]}' SELECT @vJson = JSON_MODIFY(@vJson,'$.EmployeeInfo.FirstName','James') ,@vJson = JSON_MODIFY(@vJson,'$.EmployeeInfo.LastName','Williams') SELECT JSON_QUERY(@vJson,'$.EmployeeInfo') |
When the aforementioned query is executed you will see the following in the results pane.
|
1 2 3 4 5 |
{"FirstName": "James", "LastName": "Williams", "Dob": "12-Jan-1970", "AnnualSalary": 85000 } |
Delete a property value on JSON string using JSON_MODIFY function
Now we will see how we can remove a property from an existing JSON string. Compared to the above update example, the only difference you could see is that the second parameter needs to be passed as NULL. We will take the same example above and will remove the property ‘AnnualSalary’
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DECLARE @vJson AS NVARCHAR(4000) = N'{ "EmployeeInfo": {"FirstName": "John", "LastName": "Doe", "Dob": "12-Jan-1970", "AnnualSalary": 85000 }, "Dependants": [ {"DepType":"Wife","DepName":"Jane","DepAge":30}, {"DepType": "Son","DepName": "James","DepAge": 12} ]}' SELECT @vJson = JSON_MODIFY(@vJson,'$.EmployeeInfo.AnnualSalary',NULL) PRINT @vJson |
Printing the value stored in @vJson variable will show that the property ‘AnnualSalary’ has been completely removed.
|
1 2 3 4 5 6 7 8 9 10 |
{ "EmployeeInfo": {"FirstName": "John", "LastName": "Doe", "Dob": "12-Jan-1970" }, "Dependants": [ {"DepType":"Wife","DepName":"Jane","DepAge":30}, {"DepType": "Son","DepName": "James","DepAge": 12} ]} |
Insert a property into a JSON string using JSON_MODIFY function
Now we will see an example on how we can insert a property into an existing JSON string. When inserting a property the syntax is similar as updating a JSON string, but the path provided should not exist in the JSON. Otherwise, the function will behave as the JSON_MODIFY has been used for modifying the existing an existing property. Hence it will replace the value under the provided path instead of inserting a new property.
When it comes for insertion, there are two ways where a value can be inserted into a JSON string.
- Can be inserted as a Property/Value
- Can be inserted as a new array element
We will see how we can use both these methods.
Inserting a new Property/Value to a JSON.
We will use the same example JSON which we have been using in the previous examples and will insert a property called, ‘Doj’. (‘Doj’ denotes Date of Join)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DECLARE @vJson AS NVARCHAR(4000) = N'{ "EmployeeInfo": {"FirstName": "John", "LastName": "Doe", "Dob": "12-Jan-1970", "AnnualSalary": 85000 }, "Dependants": [ {"DepType":"Wife","DepName":"Jane","DepAge":30}, {"DepType": "Son","DepName": "James","DepAge": 12} ]}' SELECT @vJson = JSON_MODIFY(@vJson,'$.EmployeeInfo.Doj','12-Jun-2012') PRINT @vJson |
Once you execute the aforementioned code snippet you can see that a new property has been added.
|
1 2 3 4 5 6 7 8 9 10 |
{ "EmployeeInfo": {"FirstName": "John", "LastName": "Doe", "Dob": "12-Jan-1970", "AnnualSalary": 85000 ,"Doj":"12-Jun-2012"}, "Dependants": [ {"DepType":"Wife","DepName":"Jane","DepAge":30}, {"DepType": "Son","DepName": "James","DepAge": 12} ]} |
Inserting a new value to a JSON as a new element.
The other way of inserting a new value to an existing JSON is to add it as a new element. This can be done using the following syntax. We will use the same example and will add a new dependent.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DECLARE @vJson AS NVARCHAR(4000) = N'{ "EmployeeInfo": {"FirstName": "John", "LastName": "Doe", "Dob": "12-Jan-1970", "AnnualSalary": 85000 }, "Dependants": [ {"DepType":"Wife","DepName":"Jane","DepAge":30}, {"DepType": "Son","DepName": "James","DepAge": 12} ]}' SELECT @vJson = JSON_MODIFY(@vJson,'append $.Dependants',JSON_QUERY('{"DepType": "Daughter","DepName": "Jenny","DepAge": 9}')) PRINT @vJson |
But if you execute the above syntax, you will see that a new element will be added to the JSON string, but with lots of escape characters along with the double quotation character.
|
1 2 3 4 5 6 7 8 9 10 |
{ "EmployeeInfo": {"FirstName": "John", "LastName": "Doe", "Dob": "12-Jan-1970", "AnnualSalary": 85000 }, "Dependants": [ {"DepType":"Wife","DepName":"Jane","DepAge":30}, {"DepType": "Son","DepName": "James","DepAge": 12} ,"{\"DepType\": \"Daughter\",\"DepName\": \"Jenny\",\"DepAge\": 9}"]} |
This is normal as it’s explained in MSDN regarding this automatic escape characters. In order to add new elements without the automatic escape characters, wrap the value with the JSON_QUERY function like shown below.
|
1 2 3 4 5 |
SELECT @vJson = JSON_MODIFY(@vJson,'append $.Dependants',JSON_QUERY('{"DepType": "Daughter","DepName": "Jenny","DepAge": 9}')) PRINT @vJson |
You can find more details regarding this here – JSON_MODIFY (Transact-SQL)
OPENJSON Function
Unlike the functions explained previously OPENJSON is a table valued function. Which means it will return a table or a collection of rows, rather than single value. This will iterate through JSON object arrays and populate a row for each element.
This function will return the details as a result set containing the following information.
- Key → Key name of the attribute
- Value → Value underlying the above key
- Type → Data type of the value
This can be used in two ways.
- Without a pre-defined schema
- With a well-defined schema
Usage of the OPENJSON without a pre-defined schema
In order to illustrate this, we will use a different JSON string than the one we have been using in our previous examples.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
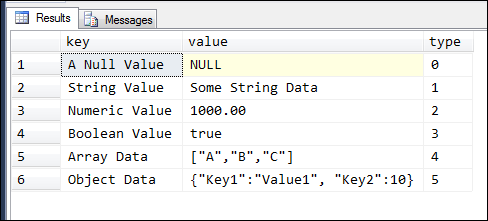
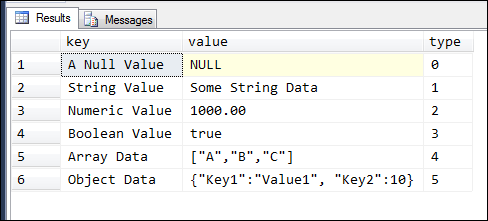
DECLARE @vJson AS NVARCHAR(1000) = ' { "A Null Value":null, "String Value":"Some String Data", "Numeric Value": 1000.00, "Boolean Value": true, "Array Data":["A","B","C"], "Object Data":{"Key1":"Value1", "Key2":10} }' SELECT * FROM OPENJSON(@vJson) |
Executing this will return the following result set
Usage of the OPENJSON with a defined schema
When we use this method, it’s mandatory to provide a list of column names along with the respective data types. One advantage we have using a well-defined schema over the previous method is the ability to generate a resultset containing different columns for each attribute value, and for column names can be customized as per our requirement.
We will use a more realistic JSON string and see how we could achieve this and first we will see how we can fetch the details without changing the column names. We have to pass the schema details as shown below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
DECLARE @vJson AS NVARCHAR(1000) = N' { "OrdNo":"XQ2379", "OrdDate":"20161228", "CustNo": "CQ1298", "OrdVal": 12755.89 } '; SELECT * FROM OPENJSON(@vJson) WITH ( OrdNo VARCHAR(6) ,OrdDate SMALLDATETIME ,CustNo VARCHAR(6) ,OrdVal MONEY ) |
Executing the aforementioned code will give the following result set
|
1 2 3 4 5 |
OrdNo OrdDate CustNo OrdVal ------ ----------------------- ------ -------- XQ2379 2016-12-28 00:00:00 CQ1298 12755.89 |
Now we will see how we can change the column names when we fetch the details using the OPENJSON function. It’s similar to the example shown previously. The difference here is that the column name should be the one which we require to be shown and after the respective data type, it should be followed by the exact JSON path. (**Note that the path is case sensitive) If you don’t provide the correct path, the result set will return a NULL under the respective column.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
DECLARE @vJson AS NVARCHAR(1000) = N' { "OrdNo":"XQ2379", "OrdDate":"20161228", "CustNo": "CQ1298", "OrdVal": 12755.89 } '; SELECT * FROM OPENJSON(@vJson) WITH ( [ORD_NO] VARCHAR(6) N'$.OrdNo' ,[ORD_DATE] SMALLDATETIME N'$.OrdDate' ,[CUST_NO] VARCHAR(6) N'$.CustNo' ,[ORD_VALUE] MONEY N'$.OrdVal' ) |
Executing the aforementioned code will give the following result set
|
1 2 3 4 5 |
OrdNo OrdDate CustNo OrdVal ------ ----------------------- ------ -------- XQ2379 2016-12-28 00:00:00 CQ1298 12755.89 |
See the example below, which the path for the Order No is provided incorrectly.
|
1 2 3 4 5 6 7 8 9 |
DECLARE @vJson AS NVARCHAR(1000) = N' {"OrdNo":"XQ2379","OrdVal": 12755.89}'; SELECT * FROM OPENJSON(@vJson) WITH ( [ORD_NO] VARCHAR(6) N'$.OrdNO' ,[ORD_VALUE] MONEY N'$.OrdVal' ) |
|
1 2 3 4 5 |
ORD_NO ORD_VALUE ------ --------------------- NULL 12755.89 |
FOR JSON Function
FOR JSON functionality is pretty much similar to the FOR XML functionality available in SQL Server. It’s used to export tabular data to JSON format.
Each row is converted to a JSON object and data on cells will be converted to values on those respective JSON objects. Column names/aliases will be used as key names.
There are two ways which FOR JSON functionality can be used.
- FOR JSON AUTO
- FOR JSON PATH
FOR JSON AUTO
The functionality is similar to FOR XML AUTO. FOR JSON AUTO will export the tabular data by automatically creating the nested JSON sub-arrays based on the table hierarchy used in the query.
In order to illustrate the aforementioned, we will use a simple data structure consisting of some Order Details.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
CREATE TABLE OrderHeader( OrderId INT ,OrderDate SMALLDATETIME ,CustNo VARCHAR(6) ) CREATE TABLE OrderDetails( OrderId INT ,ProdNo VARCHAR(6) ,Qty INT ,Price MONEY ,LineTotal MONEY ) INSERT INTO dbo.OrderHeader (OrderId, OrderDate, CustNo) VALUES (1,'27-Dec-2016','CQ1234') INSERT INTO dbo.OrderDetails( OrderId ,ProdNo ,Qty ,Price ,LineTotal ) VALUES(1,'101010',2,150,300),(1,'202020',1,147.50,147.50) |
Execute the following query
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT OH.OrderId ,OH.OrderDate ,OH.CustNo ,OD.ProdNo ,OD.Qty ,OD.Price ,OD.LineTotal FROM dbo.OrderHeader AS OH JOIN dbo.OrderDetails AS OD ON OD.OrderId = OH.OrderId FOR JSON AUTO |
Executing the aforementioned query will produce the following result.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[{ "OrderId": 1, "OrderDate": "2016-12-27T00:00:00", "CustNo": "CQ1234", "OD": [{ "ProdNo": "101010", "Qty": 2, "Price": 150.0000, "LineTotal": 300.0000 }, { "ProdNo": "202020", "Qty": 1, "Price": 147.5000, "LineTotal": 147.5000 }] }] |
Since we haven’t used any column aliases, the exact column names have been used as keys. If we use columns aliases the aliases will be used as attribute keys. Please refer to the below example:
|
1 2 3 4 5 6 7 8 9 |
SELECT OH.OrderId AS OrdId ,OH.OrderDate AS OrdDate ,OH.CustNo AS CustomerNo, OD.ProdNo AS PrdNo ,OD.Qty AS PrdQty ,OD.Price AS PrdPrice, OD.LineTotal AS PrdTotal FROM dbo.OrderHeader AS OH JOIN dbo.OrderDetails AS OD ON OD.OrderId = OH.OrderId FOR JSON AUTO |
Executing the aforementioned query will give the following results.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[{ "OrdId": 1, "OrdDate": "2016-12-27T00:00:00", "CustomerNo": "CQ1234", "OD": [{ "PrdNo": "101010", "PrdQty": 2, "PrdPrice": 150.0000, "PrdTotal": 300.0000 }, { "PrdNo": "202020", "PrdQty": 1, "PrdPrice": 147.5000, "PrdTotal": 147.5000 }] }] |
Please observe how the column aliases have been used as attribute keys.
In both examples which have been illustrated for FOR JSON AUTO, you can see that the produced JSON doesn’t contain a root element. This is due to the fact that we haven’t given instruction to FOR JSON to export the result with a root element. We can export the details with a root element as follows:
|
1 2 3 4 5 6 7 8 9 |
SELECT OH.OrderId AS OrdId ,OH.OrderDate AS OrdDate ,OH.CustNo AS CustomerNo, OD.ProdNo AS PrdNo ,OD.Qty AS PrdQty ,OD.Price AS PrdPrice, OD.LineTotal AS PrdTotal FROM dbo.OrderHeader AS OH JOIN dbo.OrderDetails AS OD ON OD.OrderId = OH.OrderId FOR JSON AUTO, ROOT ('OrderInfo') |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "OrderInfo": [{ "OrdId": 1, "OrdDate": "2016-12-27T00:00:00", "CustomerNo": "CQ1234", "OD": [{"PrdNo": "101010","PrdQty": 2,"PrdPrice": 150.0000, "PrdTotal": 300.0000 }, {"PrdNo": "202020","PrdQty": 1,"PrdPrice": 147.5000, "PrdTotal": 147.5000 }]}] } |
FOR JSON PATH
In the previous example, you could see how the order line details were exported as a separated JSON object when combined with AUTO option.
But using PATH option will extract the details in a way how the SELECT statement will fetch. That’s instead of fetching order line information as a separate object, it will return as two different elements, along with the Order Header information.
|
1 2 3 4 5 6 7 8 9 |
SELECT OH.OrderId ,OH.OrderDate ,OH.CustNo, OD.ProdNo ,OD.Qty, OD.Price, OD.LineTotal FROM dbo.OrderHeader AS OH JOIN dbo.OrderDetails AS OD ON OD.OrderId = OH.OrderId FOR JSON PATH, ROOT ('OrderInfo') |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ "OrderInfo": [{ "OrderId": 1, "OrderDate": "2016-12-27T00:00:00", "CustNo": "CQ1234", "ProdNo": "101010", "Qty": 2, "Price": 150.0000, "LineTotal": 300.0000 }, { "OrderId": 1, "OrderDate": "2016-12-27T00:00:00", "CustNo": "CQ1234", "ProdNo": "202020", "Qty": 1, "Price": 147.5000, "LineTotal": 147.5000 }] } |
However, there is one important thing, which you should be aware of when exporting details using FOR JSON PATH option. That is, if you happened to have the same column name on multiple tables you can only fetch one such column. If you include both these columns it will result in an error.
For example, if we try to export OrderId from both Header and Detail tables it will throw an error.
|
1 2 3 4 5 6 7 8 9 |
SELECT OH.OrderId ,OH.OrderDate ,OH.CustNo, OD.OrderId, OD.ProdNo ,OD.Qty, OD.Price, OD.LineTotal FROM dbo.OrderHeader AS OH JOIN dbo.OrderDetails AS OD ON OD.OrderId = OH.OrderId FOR JSON PATH, ROOT ('OrderInfo') |

Related Links
- JSON Data (SQL Server)
- Convert JSON Data to Rows and Columns with OPENJSON (SQL Server)
- Format Query Results as JSON with FOR JSON (SQL Server)
However working as a Senior Database Developer for the past 5 years had allowed me to work more closely with SQL Server Development & Administration and gave me the opportunity to dive deep into the SQL Server and its features.
My current role involves architecture and building a variety of data solutions, providing database maintenance and administration support, building the organization’s data practice, and training and mentoring peers while allowing me to pursue my passion which is to write about things I work with and talking about it.
View all posts by Manjuke Fernando
- Native JSON Support in SQL Server 2016 - January 6, 2017