
Introduction
There is a lot of talk about how bad triggers are, how you should never use them, etc. I wanted to spend some time reviewing fact vs fiction and do an objective analysis of SQL Server database triggers (both DDL and DML), warts and all. We will review alternatives and compare them with triggers to determine advantages vs disadvantages of each approach.
The following experiments will be conducted:
- Triggers vs constraints will compare the performance of both solutions
- Historical records/auditing using triggers (trigger vs OUTPUT clause)
- SQL Profiler vs triggers
- DDL Triggers vs Extended events
Getting started
1. Trigger vs constraints
The first example is the simplest one. We will compare a check constraint with a trigger to verify which one is faster.
We will first create a table named testconstraint that will check if the amount column has values below 1000:
|
1 2 3 4 5 6 |
create table testconstraint (id int PRIMARY KEY CLUSTERED, amount int CONSTRAINT chkamount CHECK (amount <1000) ) |
We will also create another table named testrigger, which will be similar to testconstraint, but it will use a trigger instead of a check constraint:
|
1 2 3 4 5 |
create table testrigger (id int PRIMARY KEY CLUSTERED, amount int ) |
We will also create a trigger for the table to verify that the values inserted are lower than 1000:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE TRIGGER amountchecker ON dbo.testrigger AFTER INSERT AS DECLARE @value int= (select TOP 1 inserted.amount from inserted) IF @value >1000 BEGIN RAISERROR ('The value cannot be higher than 1000', 16, 10); ROLLBACK END GO |
To compare the performance, we will set the STATISTICS IO and TIME:
|
1 2 3 4 5 6 7 |
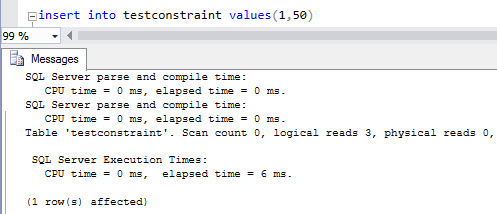
SET STATISTICS io ON SET STATISTICS time ON GO insert into testconstraint values(1,50) |
This insert values, will have an execution time of 6 ms:
Let’s try to insert a value above 1000:
|
1 2 3 |
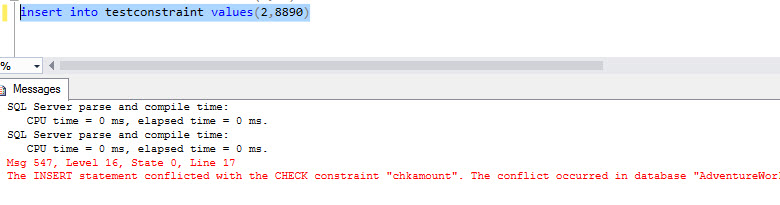
insert into testconstraint values(2,8890) |
The execution time is 0 ms:
Now, let’s test the trigger:
|
1 2 3 |
insert into testrigger values(1,50) |
As you can see, the execution time is higher than a constraint:

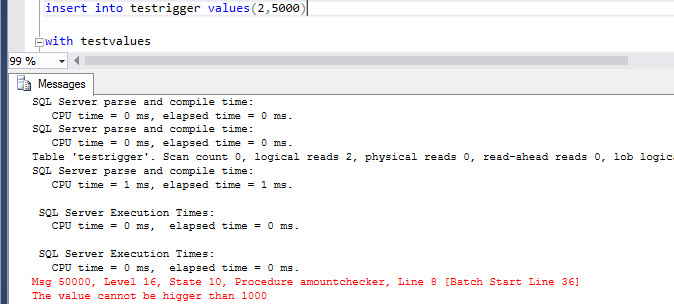
If we try a value higher than 1000, the execution time is slightly higher (1 ms):
|
1 2 3 |
insert into testrigger values(2,5000) |
To compare, we will insert one million rows in the table with constraints:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
with testvalues as( select 1 id, CAST(RAND(CHECKSUM(NEWID()))*1000 as int) prices union all select id + 1, CAST(RAND(CHECKSUM(NEWID()))*999 as int) prices from testvalues where id <= 1000000 ) insert into testconstraint select * from testvalues OPTION(MAXRECURSION 0) |
After inserting a million rows, you can check the execution time:
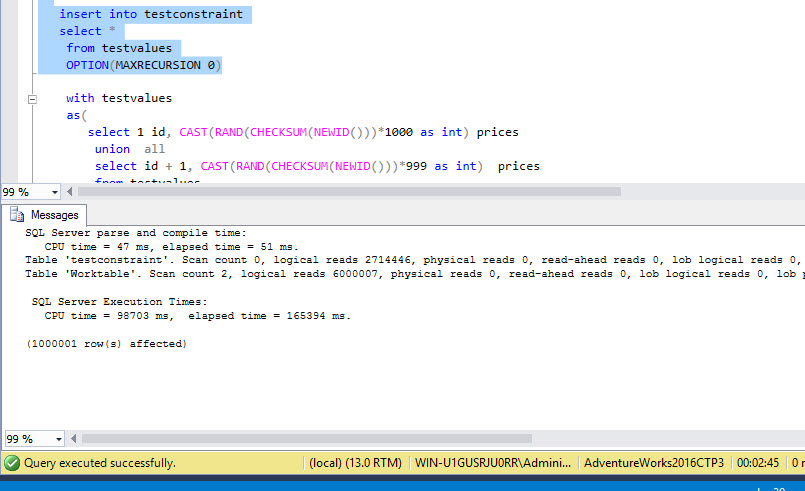
Then, we will do the same with the table with triggers:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
with testvalues as( select 1 id, CAST(RAND(CHECKSUM(NEWID()))*1000 as int) prices union all select id + 1, CAST(RAND(CHECKSUM(NEWID()))*999 as int) prices from testvalues where id <= 1000000 ) insert into testrigger select * from testvalues OPTION(MAXRECURSION 0) |
And check the execution time:
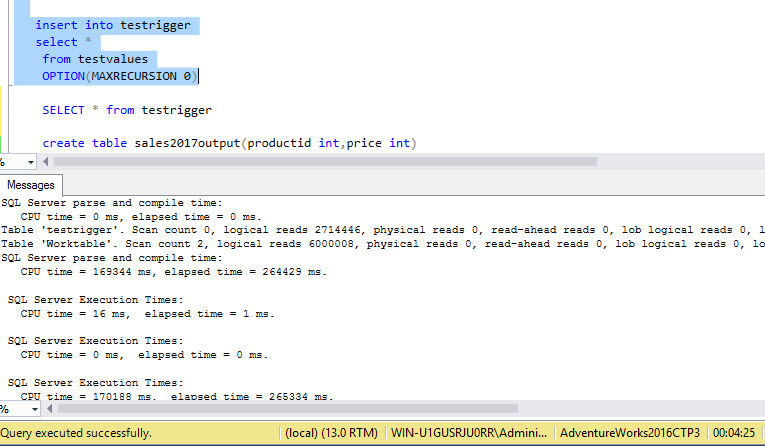
The following table shows the results after running and truncating both tables 5 times each:
| Execution time constraint (minutes:seconds) | Execution time trigger (minutes:seconds) | Difference in % |
| 2:59 | 2:55 | -2 |
| 2:37 | 3:14 | 19 |
| 2:37 | 2:45 | 5 |
| 2:45 | 2:45 | 0 |
| 2:35 | 2:58 | 13 |
| Average 2 minutes :44 seconds | Average: 2 minutes :55 seconds | 7 |
As you can see, the constraint is faster. In this example constraints are 7% faster in average than triggers.
In general, try to use primary keys and unique constraints to verify uniqueness, Default values to specify default values by default, foreign keys to verify the integrity between two tables and check constraints to check specific values. If none of these options works for your needs, maybe the computed columns can be an alternative. Computed columns are virtual columns not stored in a database based on expressions.
2. Historical record tracking (aka auditing) using triggers (trigger vs OUTPUT clause)
It is a common practice to use triggers to record changes in tables as a form of auditing. I saw some companies that are removing triggers and replacing it with stored procedures. They are using the OUTPUT clause. The output clause allows to capture inserted, deleted from INSERT, UPDATE, DELETE and MERGE operations.
We will create 2 tables. One to test the OUTPUT clause and another to test the trigger:
|
1 2 3 4 |
create table sales2017output(productid int,price int) create table sales2017trigger(productid int,price int) |
In addition, we will create 2 historical tables to record the insert changes in the tables created above:
|
1 2 3 4 |
create table historicproductsalesoutput(productid int,price int, currentdate datetime default getdate()) create table historicproductsalestrigger(productid int,price int, currentdate datetime default getdate()) |
We will create a trigger to insert the inserted value and the date of insertion in the historicproductsalestrigger table:
|
1 2 3 4 5 6 7 8 9 10 |
create trigger historicinsert on dbo.sales2017trigger for insert as insert into historicproductsalestrigger select inserted.productid, inserted.price, getdate() from inserted go |
The trigger named historicinsert inserts data in the table historicproductsalestrigger when an insert occurs in the dbo.sales2017trigger.
Here it is how to store the historical records using the output clause (option 1):
|
1 2 3 4 5 6 7 |
--Option 1 insert into sales2017output OUTPUT inserted.productid, inserted.price, getdate() into historicproductsalesoutput values(1,22) |
OUTPUT used the table inserted, which is a temporal table that stores the rows inserted.
The second option uses triggers. When we do an insert, the historical records are created automatically by the trigger created before:
|
1 2 3 4 5 |
--Option 2 insert into sales2017trigger values(1,22) |
Let’s compare the performance. We will run insert one million rows using triggers:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
with testvalues as( select 1 id, CAST(RAND(CHECKSUM(NEWID()))*1000 as int) prices union all select id + 1, CAST(RAND(CHECKSUM(NEWID()))*999 as int) prices from testvalues where id <= 1000000 ) insert into sales2017trigger select * from testvalues OPTION(MAXRECURSION 0) |
To compare, we will insert one million rows using the OUTPUT Clause:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
with testvalues as( select 1 id, CAST(RAND(CHECKSUM(NEWID()))*1000 as int) prices union all select id + 1, CAST(RAND(CHECKSUM(NEWID()))*999 as int) prices from testvalues where id <= 1000000 ) INSERT into sales2017output OUTPUT inserted.productid, inserted.price, getdate() into historicproductsalesoutput SELECT * From testvalues OPTION(MAXRECURSION 0) |
The following table shows the results after running several times:
| Execution time OUTPUT clause (minutes:seconds) | Execution time trigger (minutes:seconds) | Difference in % |
| 5:56 | 3:52 | 34 |
| 6:05 | 3:42 | 39 |
| 5:58 | 3:56 | 34 |
| 5:46 | 3:48 | 34 |
| 6:01 | 3:51 | 36 |
| Average 5 minutes and 57 seconds | Average 3 minutes and 49 seconds | Triggers are 35% faster |
As you can see, OUTPUT clause is slower than a trigger in some cases. If you need to created historical records of your table changes, be aware that replacing triggers with OUTPUT clause will not improve the performance. In the table, you can see that triggers are 35% faster than the OUTPUT clause.
With OUTPUT, you have more control on the code, because you can extract the inserted and deleted rows in a specific stored procedure whenever you want. The problem with triggers is that they are executed even if you do not want them to. You can of course disable a trigger, but it is very common to activate triggers by accident.
Triggers can be a good choice if there is an external tool that access and inserts data to your database and you cannot access to code, but you need to add some functionality on insert, delete and update clauses.
3. SQL Profiler vs trigger
With SQL Profiler, you can store in a file or a table some SQL events like insert, update, create, drop and many other SQL Server events. Is SQL Profiler an alternative to triggers to track SQL Server events?
In this example, we will track a table insert and store the result in a table.
Let’s take a look to SQL Profiler:
In the start menu, start the SQL Server Profiler:
We will create a new template to store the T-SQL Statements completed. Go to File>Trace>New Trace:
Specify a name for the new template:
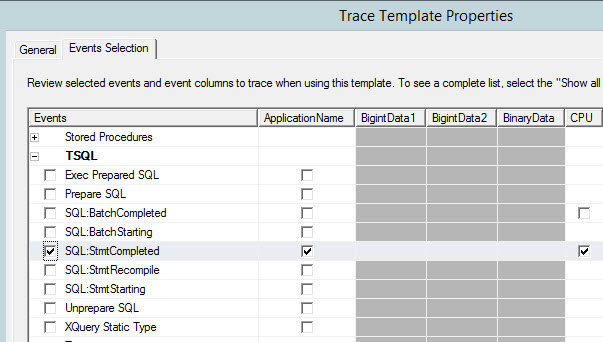
SQL:StmtCompleted will track the T-SQL Statements completed. Select this event:
You can specify filters by pressing the Column Filters button:
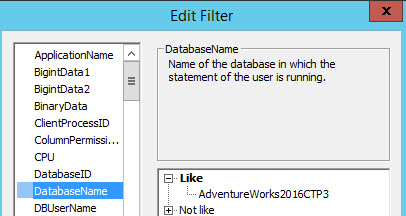
In DatabaseName, we will only trace the SQL Statements of the AdventureWorks2016TCP3 database. You can use another database of your preference. Save the trace once that the database name is specified:
In the Profiler menu, go to New trace:
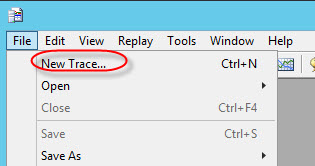
Select the template just created above:
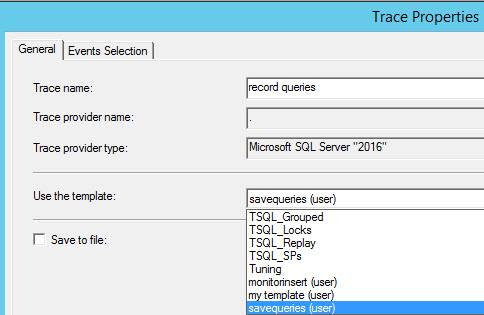
In General tab, check the save to table option:

Specify your Login and password.
Specify the database, schema and table name where you want to store the trace information. If the table does not exist, it will be created:
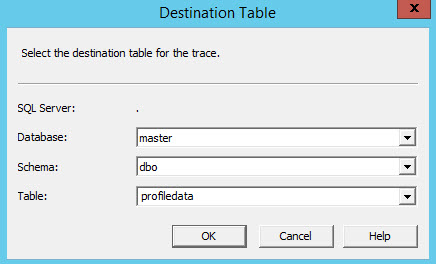
Run the trace, and to test in profiler, and in SSMS, go to Adventureworks2016CT3 Database or the database that you selected in the filter and run this statements:
|
1 2 3 4 5 6 7 |
create table sales2017profiler(productid int,price int) GO insert into sales2017profiler values (1,22) GO |
In SQL Server Profiler, you will be able to see the statement run including the application name where the statements run, the CPU time, duration, etc.:

The problem with SQL Profiler is that it will be deprecated soon (for the database engine, but not for Analysis Services). According to Microsoft, SQL Profiler will be removed in a later version. Why?
Because it consumes too many resources. SQL Profiler is recommended to run in another Server.
In other words, it is not recommended to replace triggers with SQL Profiler. The best alternative to Profiler is extended events.
4. DDL Triggers vs Extended events
DDL triggers are used to execute an action for events like creating a new database, altering a table, granting permissions.
In this example, we will create a table in the master database to store the execution time, SQL User, Event and query executed. This table will store that information when a database is created using triggers.
The table name will be trigger_event and it will store the information of the new databases created:
|
1 2 3 4 5 6 |
USE master GO CREATE TABLE trigger_event (ExecutionTime datetime, [User] nvarchar(80), EventType nvarchar(30), Query nvarchar(3000)); GO |
The following trigger stores the user, query, execution date and event when a database is created in the trigger_event table created above:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TRIGGER DATABASECREATED ON ALL SERVER FOR CREATE_DATABASE AS DECLARE @data XML SET @data = EVENTDATA() INSERT trigger_event VALUES (GETDATE(), CONVERT(nvarchar(80), CURRENT_USER), @data.value('(/EVENT_INSTANCE/EventType)[1]', 'nvarchar(30)'), @data.value('(/EVENT_INSTANCE/TSQLCommand)[1]', 'nvarchar(3000)') ) ; GO |
EVENTDATA() is a function complementary to triggers that stores the trigger event information using a XML file.
To test the trigger we will create a database named test9:
|
1 2 3 |
create database test9 |
If we do a select in the trigger_event table, we notice that all the information was stored after the create database statement:
|
1 2 3 |
select * from trigger_event |
The values displayed are the following:

An alternative to triggers is Extended Events. As we said before, SQL Profiler will be removed in the future and the Extended Events will replace them.
In this example, we will create an extended event to detect if a new database was created.
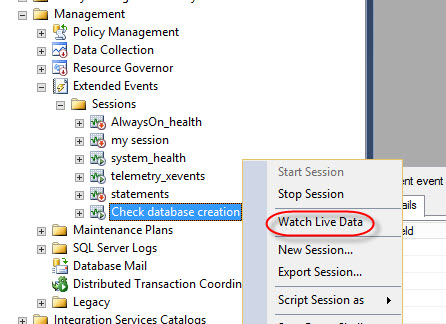
In the SSMS, go to Management>Session and right click and select new session:
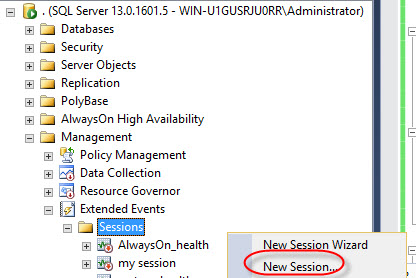
Specify a session name and check the Start the event session immediately after session created and Watch live data on screen as it is captured option:
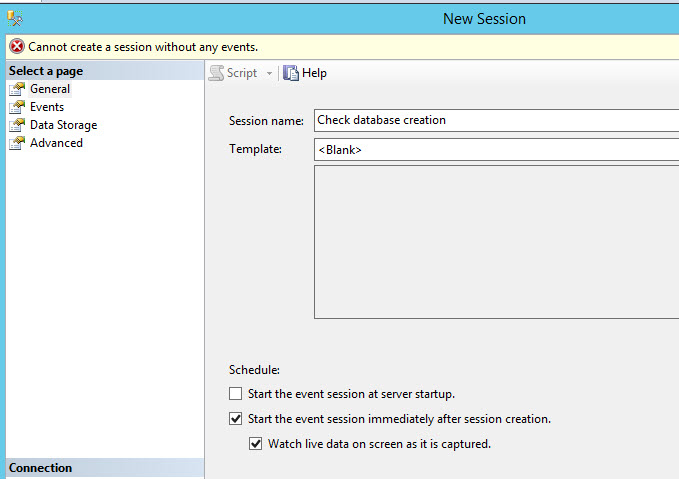
In event library, select the database_created event:
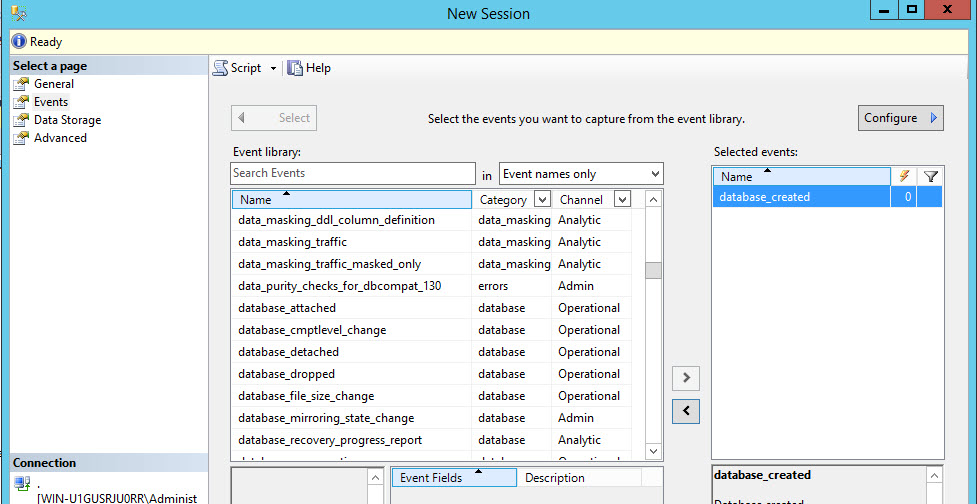
On the Session created, right click and select Watch Live Data:
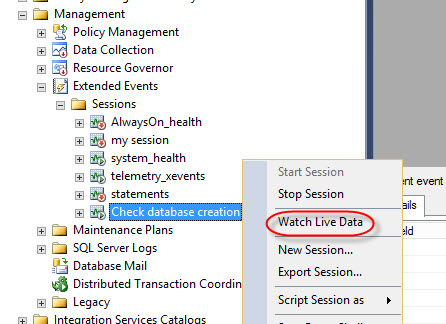
To generate an event, create a database:
|
1 2 3 |
create database test3 |
For some reason, the event appears after a second event:
|
1 2 3 |
Create database test4 |
You will now be able to see the first event:
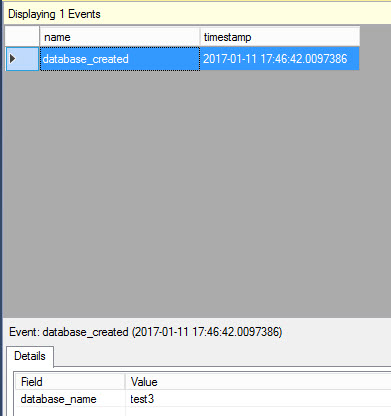
Extended Events is a great alternative to triggers. It is simple and it does not consume as much resources like SQL Profiler.
Conclusions
We learned the following:
- Constraints should be used whenever is possible instead of triggers because they are faster, they are easier to maintain and require less code.
- OUTPUT parameters in SQL stored procedures do not have better performance than the triggers, based on the tests I conducted. Therefore, it is not a good choice to replace triggers for performance reasons.
- SQL Profiler should not be used to replace triggers, because it is a feature that will be removed soon.
- Extended events can be a good choice to replace DDL triggers in some scenarios.
There are some DBAs that say that we should never use triggers, but if it does not affect the performance of your code, if they are not used all the time, it is not bad to use it in your code. Make sure to disable for massive bulks and be careful with recursive triggers. Triggers are not evil, but they must be used wisely.
Always remember:
“With great triggers comes great responsibility”.
References
For more information, refer to these links:
- Extended Events Catalog Views (Transact-SQL)
- Using Extended Events to review SQL Server failed logins
- CREATE TRIGGER (Transact-SQL)
- SQL Server Profiler

He has worked for the government, oil companies, web sites, magazines and universities around the world. Daniel also regularly speaks at SQL Servers conferences and blogs. He writes SQL Server training materials for certification exams.
He also helps with translating SQLShack articles to Spanish
View all posts by Daniel Calbimonte
- PostgreSQL tutorial to create a user - November 12, 2023
- PostgreSQL Tutorial for beginners - April 6, 2023
- PSQL stored procedures overview and examples - February 14, 2023