

Description
In SQL Server, internal latch architecture protects memory during SQL operations. It ensures the consistency of memory structures with read and write operation on pages. Rudimentarily, it has two classes, buffer latches, and non-buffer latches which perform lightweight synchronization in the SQL Engine.
The latch ensures memory consistency while Locks ensures logical transaction consistency. When multiple users or applications access the same data at the same time, locking prevents them from making simultaneous changes to the data. Locks are managed internally by the Microsoft SQL Server Compact Database Engine. While a user performs DML operations, locks are automatically acquired and released on resources. The latch ensures memory consistency on memory structures including indexes and data pages. Generally, SQL server uses buffer pool and IO latches to deal with synchronizing primitive manner in-memory structures. When there is a multiple thread concurrency load on the server then a latch result from an attempt to acquire an incompatible memory structure and in doing so, a latch contention issue can arise.
There are many types of SQL Server latches including buffer, non-buffer, and IO latches. For more clarification about the latch, kindly check out the article All about Latches in SQL Server by Nikola Dimitrijevic. Moreover, I will discuss in detail more about Hot latches, how to identify and resolve them.
Latch modes and compatibility
Basically, as we know, latches are acquired in 5 different modes KP (Keep latch), SH (Shared latch), UP (Update latch), EX (Exclusive latch), DT (Destroy latch). I have summarized the latch modes and their compatibility.
KP (Keep latch)
Keep latches ensure that the referenced structure cannot be destroyed.
SH (Shared latch)
A Shared latch is required to read a page data structure. A Shared latch (SH) is compatible with an update (UP) or keep (KP) latch, but incompatible with a destroy latch (DT).
UP (Update latch)
Update latch is compatible with Keep latch and shared latch but no one can allow to write to its reference structure.
EX (Exclusive latch)
This latch blocks other threads from waiting or reading from a reference area.
DT (Destroy latch)
This latch assigned to the content of the referenced structure before destroying the content.
All of these latch modes are not compatible with each other. For example, when a thread attempts to acquire a possible latch and the mode is not compatible, then it is placed into the queue to wait for resource availability. For more clarification, kindly review latch mode compatibility chart below.
| KP | SH | UP | EX | DT | |
| KP | Y | Y | Y | Y | N |
| SH | Y | Y | Y | N | N |
| UP | Y | Y | N | N | N |
| EX | Y | N | N | N | N |
| DT | N | N | N | N | N |
Latch wait types
With a concurrency load, due to latch mode incompatibilities, page contention can arise. We can figure out these contention issues with the help of wait types which is reported from different SQL Server DMVs; sys.dm_os_wait_stats, sys.dm_os_latch_stats, sys.dm_exec_query_stats, etc.
- Buffer latches (BUF) are reported in the DMV with prefix PAGELATCH_*. (For an example PAGELATCH_EX, PAGELATCH_SH)
- Non-buffer latches (Non-BUF) are reported in the DMV with prefix LATCH_*. (For an example LATCH_UP, LATCH_EX, LATCH_SH, LATCH_DT)
- IO Latch is reported with prefix PAGEIOLATCH_*. (For an example PAGEIOLATCH_SH, PAGEIOLATCH_EX)
Hot Latches (PAGELATCH_EX)
As per the above-mentioned overview, there are the different wait types that arise due to these latch contentions. Out of these waits, I have focused on the wait type PAGELATCH_EX.
This wait type means that when a thread is waiting for access to a data file page in memory because it might be page structure in exclusive mode due to another running process. The structure would be a primary page from table or index.
Usually, when the concurrency request frequency is made higher on the server with insert operations, those multiple requests will be waiting on the same resource with a PAGELATCH_EX wait type on the index page. This occurrence is also called a “hot latches” issue or a “hot spot”. This type of latch contention also possible with an update or delete operation while a concurrency load.
For this contention, it can be possible, that the issue has been generated due to sequential leading index keys. Generally, Indexing is the backbone of the database engine but aftereffect the contention can arise. To be more specific, if a table has a clustered index, it organizes data in a sorted manner while inserting the data. Though it’s adding a record at the end of the clustered index it could be more intuitive that the issue is page split occurrences. But the insertion requests queue is generated on the last page, and in addition to this, we may also add an identity column to cluster index, then it can lead to additional performance problems while the concurrent insertion frequency is higher on the single object. On concurrency insertion, how do these requests pile up? How does this latch contention PAGELATCH_EX come up in the picture? For more clarification, kindly review the diagram below.

As per the diagram, there are multiple requests to insert data into a single table which has a clustered index hence those are waiting on the last page because this insert statement is performed serially performed due to physical order, and as a result of this latch contention arises and results in excessive occurrences of the wait type PAGELATCH_EX. However, this contention refers to the last page insert contention issue.
Identifying the Hot latches contention issue
For more clarification, I will recreate this scenario on my local server to do so, I have prepared sample script. In the script, I have introduced one base table and procedure and a database, Hotspot.
Sample Script
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
CREATE DATABASE Hotspot GO Use Hotspot GO CREATE TABLE audit_Data ( audit_id int primary key identity (1,1), audit_action nvarchar(max), audit_desc nvarchar(max), ref_person_action int, actionlist xml, actionarea xml, dtauditDate datetime default getdate () ) GO CREATE PROCEDURE audit_history ( @audit_action nvarchar(MAX), @audit_desc nvarchar(max), @ref_person_action int, @actionlist xml, @actionarea xml ) as begin insert into audit_Data select @audit_action,@audit_desc,@ref_person_action,@actionlist,@actionarea,GETUTCDATE() select SCOPE_IDENTITY () end GO |
I have applied above-mentioned script in my test server, now I have the database “Hotspot” ready for execution.
Apply load test in local server
There are multiple tools and utility available for the load test in the testing server; I have used Adam Machanic’s SQLQuerystress tool.
During this testing, It is necessary to get query statistics for troubleshooting this issue. For the purpose of demonstration, I have prepared scripts for getting same which is I mentioned below, which you can review.
Query for getting wait resource vs T-SQL execution
I have used multiple SQL DMVs and based on that I have prepared a query for getting the wait statistics. Alternatively, we can also use a tool like a Profiler, Activity monitor, etc.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
use Hotspot go SELECT wt.wait_duration_ms, wt.wait_type, s_text.text, DB_NAME(req.database_id) DatabaseName, req.wait_resource, session.login_name, req.last_wait_type FROM sys.dm_os_waiting_tasks wt INNER JOIN sys.dm_exec_requests req ON wt.session_id = req.session_id INNER JOIN sys.dm_exec_sessions session ON session.session_id = req.session_id CROSS JOIN sys.dm_exec_sql_text (req.sql_handle) s_text CROSS APPLY sys.dm_exec_query_plan (req.plan_handle) qp WHERE session.is_user_process = 1 GO |
Query for measuring statistics of the transaction, latch wait, batch requests etc.
In addition, I have prepared this query for getting latches, batch requests in detail with respect to transaction vs time. I have configured 30-second delay by default in this query. Alternatively, we can also use performance monitor.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
use Hotspot go select object_name,counter_name,cntr_value into #perfcounter From sys.dm_os_performance_counters where counter_name in ( 'Transactions/sec', 'Latch Waits/sec', 'Average Latch Wait Time (ms)', 'Batch Requests/sec') and ( ltrim(rtrim(instance_name)) = 'HotSpot' OR instance_name = '') WAITFOR DELAY '00:00:30'; select counters.object_name,counters.counter_name As ActionName,counters.cntr_value - perf.cntr_value ActionValue From #perfcounter perf inner join sys.dm_os_performance_counters counters on counters.counter_name = perf.counter_name where counters.counter_name in ( 'Transactions/sec', 'Latch Waits/sec', 'Average Latch Wait Time (ms)', 'Batch Requests/sec') and ( ltrim(rtrim(instance_name)) = 'HotSpot' OR instance_name = '') DROP TABLE #perfcounter GO |
Now I have the availability for monitoring queries as well as SQLQueryStress tool. Now I will go for executing both things in parallel.
- Locally, I have configured SQLQueryStress then applying procedure load 100 Thread * 1000 Iterations.
- In Parallel, I have run both monitoring queries in SSMS.
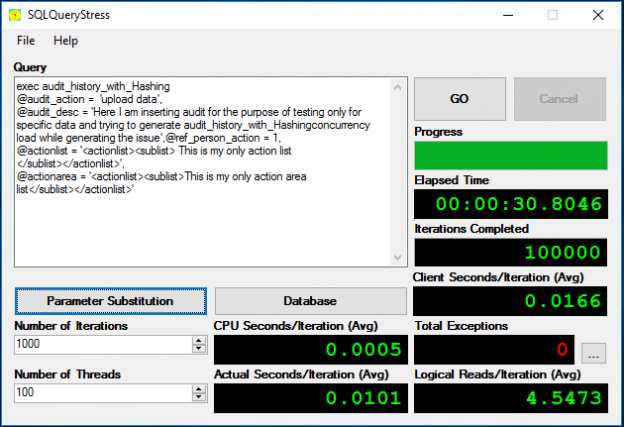
SQLQueryStress Load test result with 100 thread * 1000 iterations

Monitoring query result in SSMS
As per mentioned above monitoring queries, I am going to execute in two different sessions.


As can be seen, as a result of this, the total process has been completed in 40 seconds and multiple instances of the wait type PAGELATCH_EX have been found in the monitoring query result.
How to resolve hot latches contention
It might be possible to reduce the contention if I remove the clustered index but this might not be ideal. We have multiple ways to distribute insertion across the index range; horizontal partition techniques, using a hash value in the leading unique key column, etc.
Using hash value in the leading unique key column
A hash value means, a dynamically generated key value. If I use hash value in the leading primary key column, the unique key value is distributed with audit_id across the B-Tree structure. Because of this, I have changed my table structure. For demonstration purpose, I will create a table and a procedure with a different name which is I attached the script below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
Use Hotspot GO CREATE TABLE audit_Data_with_Hashing ( audit_id int identity (1,1) NOT NULL, audit_action nvarchar(max), audit_desc nvarchar(max), ref_person_action int, actionlist xml, actionarea xml, dtauditDate datetime default getdate (), HashValue as (CONVERT([INT], abs([audit_id])%(30))) PERSISTED NOT NULL ) GO ALTER TABLE audit_Data_with_Hashing ADD CONSTRAINT pk_hashvalue PRIMARY KEY CLUSTERED (HashValue, audit_id) GO CREATE PROCEDURE audit_history_with_Hashing ( @audit_action nvarchar(MAX), @audit_desc nvarchar(max), @ref_person_action int, @actionlist xml, @actionarea xml ) as begin insert into audit_Data_with_Hashing select @audit_action,@audit_desc,@ref_person_action,@actionlist,@actionarea,GETUTCDATE() select SCOPE_IDENTITY () end GO |
I have applied above-mentioned script in my test server now I am going to apply the same load test as previous and capture statistics again.
SQLQueryStress load test result with 100 thread * 1000 iterations
I have re run SQLQueryStress tool and execute as follows.

Monitoring query result in SSMS
As per the previously mentioned monitoring queries, I am going to execute in two different sessions.


Now, I have got load test results in 30 seconds and got latch waits/sec of 484 instead of 196,746 and average latch wait time(MS) count of 206,170 instead of 1,421,675. As a result of query statistics, the Pagelatch_EX waits have been reduced. As per my product use case, I have configured this approach. It could be possible different effects for this approach. Later on, I will describe pros and cons of this.
Partition techniques
When a table has millions of rows, then the table cost comes up in the picture vis a vis DML operations. In this behavior, structure level changes are needful like vertical and horizontal table level partitions. There are several trade-offs between these. Horizontal table partition could be integrated easily We can also apply horizontal partitions on a computed column, which is practically the same functionality with just minor differences as using leading unique indexes. When the insertion operation is performed, this is still going on the end of this logical range, but hash values produce dynamic values and its split across the B-tree structure. To do so, it might be possible, due to this frequency insertion contention issue can be solved using a computed column.
Conclusion
I have concluded points and mentioned trade-off below.
Pros
- Using it, Insertion will be performed in a non-sequential manner and provide a benefit against the frequency of latch contention issue.
- The table partition feature is very useful for managing large volume data;
Cons
- Index key length is bigger than normal. Due to this index size difference and page traversing cost, fragmentation can become an issue.
- Random insertion operations might generate page split operations.
- Get data action like select queries might produce issues while retrieving the data from hash partitions because the query plan estimates might be inaccurate.
- It’s difficult to maintain reference integrity while increasing key combination of indexes.
See more
Check out ApexSQL Plan, to view SQL execution plans, including comparing plans, stored procedure performance profiling, missing index details, lazy profiling, wait times, plan execution history and more


During his career, he strongly workes on his DBA development and has been working with SQL Server 2000, 2005, 2008, 2012, 2014 and 2016.
Currently, his main role is query tuning with respect to optimization and server performance. He is interested in constant learning and likes to face challenges. In his spare time, he spends time with his family.
- Hash partitions in SQL Server - June 28, 2018
- The Halloween Problem in SQL Server and suggested solutions - May 4, 2018
- How to identify and resolve Hot latches in SQL Server - November 7, 2017