
Quite often developers put the responsibility of the server performance on the shoulders of DBAs. But to be honest, as a developer, it is your responsibility to write code which is efficient and optimal. However, when writing code, the developer often lacks the knowledge and/or experience about SQL Server to meet this requirement.
In this series, I will be discussing various aspects of query designing, keeping performance and scalability in mind. We will be addressing the most common concepts which we often see that negatively impact SQL code written by developers.
To make sure that we do not get into the realm of “it depends”, the whole article is mostly based on an 80-20 rule. 80% of the work rules can benefit from the generalization but there is still 20% of particular specific used cases that the generalization might not be helpful.
In the article, we will talk about the various operators and what do they do, when do they come and what happens.
Avoid using SELECT *
When writing queries, it would be better to set the columns you need in the select statement rather than SELECT *. There are many reasons for that recommendation, like:
- SELECT * Retrieves unnecessary data besides that it may increase the network traffic used for your queries.
- When you SELECT *, it is possible to retrieve two columns of the same name from two different tables (when using JOINS for example).
- SELECT * with WHERE conditions will use clustered index by default so it may not use optimal other indexes.
- The application might break, because of column order changes.
Let us try to check out the drawbacks of using SELECT * with AdventureWorks2014 sample database:
Include actual execution plan while executing the following query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT SalesOrderID,SalesOrderDetailID,CarrierTrackingNumber FROM Sales.SalesOrderDetail WHERE ProductID = 707 GO SELECT * FROM Sales.SalesOrderDetail WHERE ProductID = 707 GO |
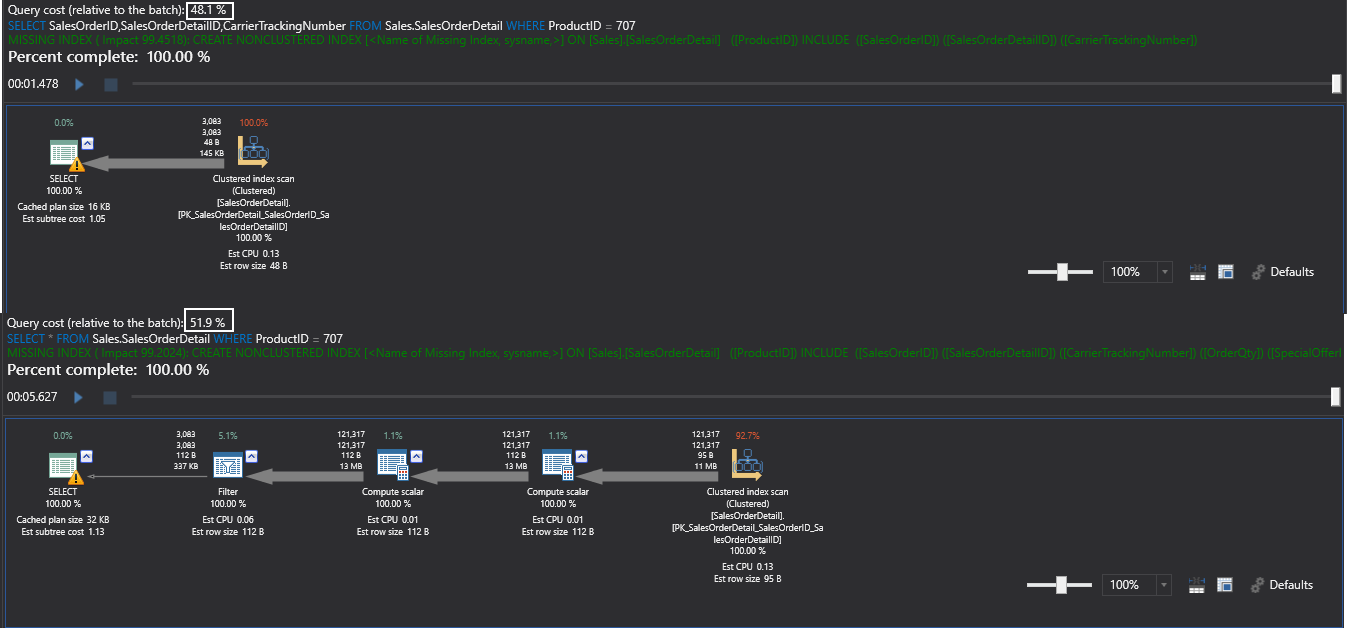
As you can see below, both queries have the same number of rows retrieved and the same number of logical reads done.

Although there is a missing index, there is a slight query cost advantage for the first SELECT statement.
Now, let us create the missing index as suggested by the query optimizer.
|
1 2 |
CREATE INDEX IX_SalesOrderDetail_1 ON Sales.SalesOrderDetail(ProductID, SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber)<pre> |
And rerun the same queries again.

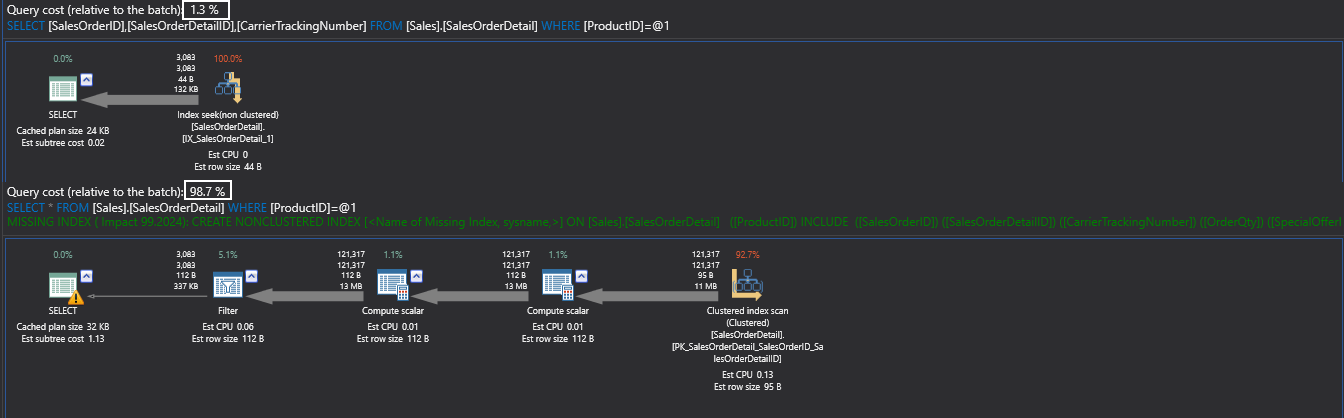
Now, the difference is very obvious that the first query has only 13 logical reads with a relative query cost percent of only 1% versus the second query which is actually doing a complete scan of the clustered index, not using the recently created non-clustered index.
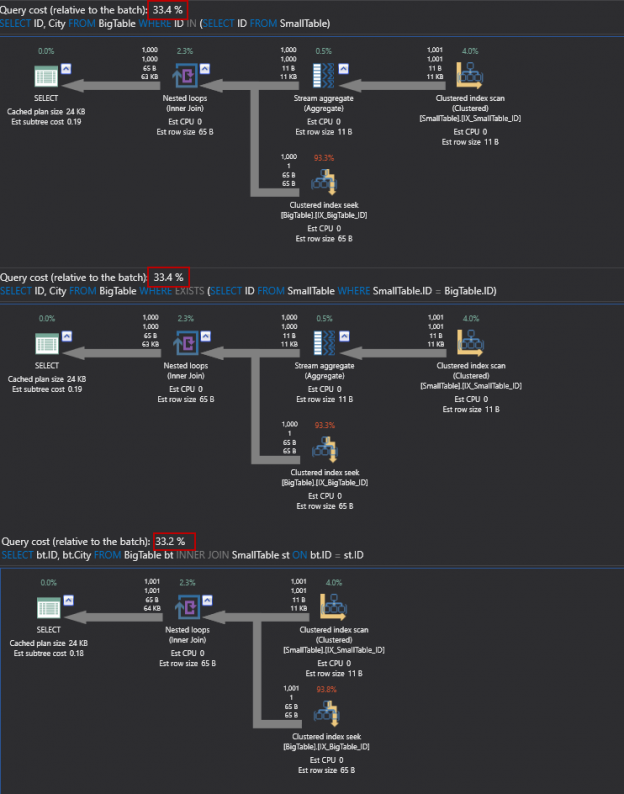
EXISTS vs IN vs JOINs
Before chosing IN or EXISTS, there are some details that you need to look at.
Most of the time, IN and EXISTS give you the same results with the same performance.
On the other hand, when you use JOINS you might not get the same result set as in the IN and the EXISTS clauses.
So, to optimize performance, you need to be smart in using and selecting which one of the operators.
1. EXISTS vs IN vs JOIN with NOT NULLable columns:
We will use TEMPDB database for all of these scenarios.
The following script will create, and fill two tables in the TEMPDB database. The main ideas in these tables are that the small table is a subset of the big table and the ID column doesn’t allow null.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
USE tempdb GO SET NOCOUNT ON GO CREATE TABLE BigTable (ID INT NOT NULL, FirstName VARCHAR(100), LastName VARCHAR(100), City VARCHAR(100)) GO INSERT INTO BigTable (ID,FirstName,LastName,City) SELECT TOP 100000 ROW_NUMBER() OVER (ORDER BY a.name) RowID, 'Bob', CASE WHEN ROW_NUMBER() OVER (ORDER BY a.name)%2 = 1 THEN 'Smith' ELSE 'Brown' END, CASE WHEN ROW_NUMBER() OVER (ORDER BY a.name)%10 = 1 THEN 'New York' WHEN ROW_NUMBER() OVER (ORDER BY a.name)%10 = 5 THEN 'San Marino' WHEN ROW_NUMBER() OVER (ORDER BY a.name)%10 = 3 THEN 'Los Angeles' WHEN ROW_NUMBER() OVER (ORDER BY a.name)%427 = 1 THEN 'Hyderabad' ELSE 'Houston' END FROM sys.all_objects a CROSS JOIN sys.all_objects b GO CREATE TABLE SmallTable (ID INT NOT NULL, FirstName VARCHAR(100), LastName VARCHAR(100), City VARCHAR(100)) GO INSERT INTO SmallTable (ID,FirstName,LastName,City) SELECT TOP(1000) * FROM BigTable |
|
1 2 3 4 5 6 |
CREATE CLUSTERED INDEX IX_BigTable_ID ON BigTable(ID) GO CREATE CLUSTERED INDEX IX_SmallTable_ID ON SmallTable(ID) GO |
Last, we will add one duplicate row in the small table:
|
1 2 |
INSERT INTO SmallTable (ID,FirstName,LastName,City) SELECT TOP(1) * FROM SmallTable |
Now, with including the actual execution plan execute the following three queries together to figure out the differences:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
SET STATISTICS IO ON SET NOCOUNT OFF print'Using IN Clause' SELECT ID, City FROM BigTable WHERE ID IN (SELECT ID FROM SmallTable) GO print 'Using Exists Clause' SELECT ID, City FROM BigTable WHERE EXISTS (SELECT ID FROM SmallTable WHERE SmallTable.ID = BigTable.ID) GO Print 'Using JOIN' SELECT bt.ID, bt.City FROM BigTable bt INNER JOIN SmallTable st ON bt.ID = st.ID GO |

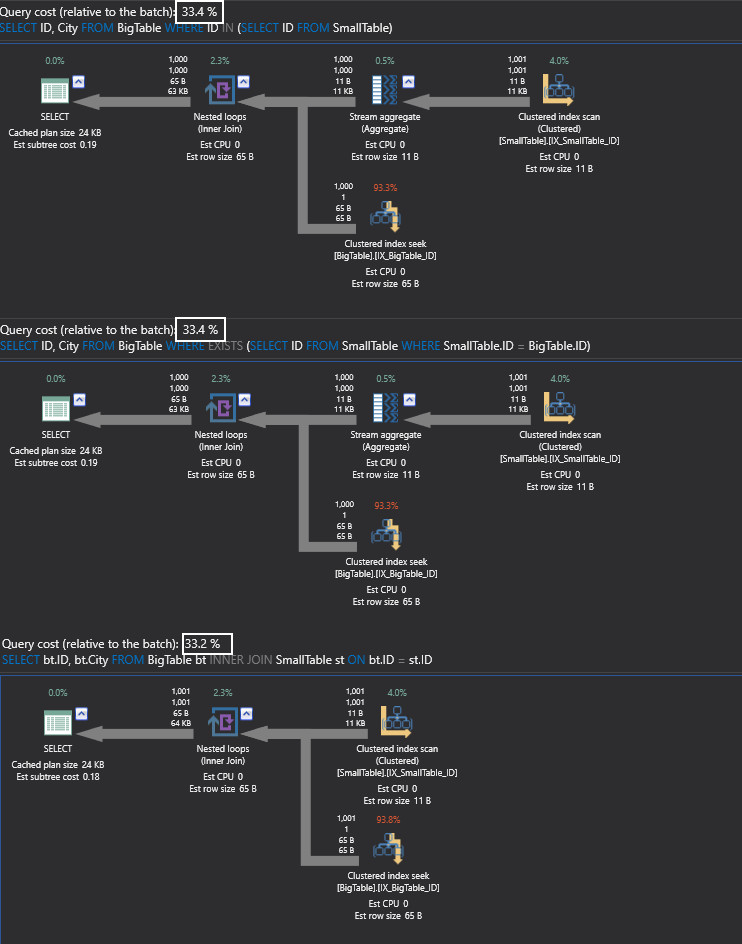
First difference you will notice, as I said, the rows returned by JOIN is 1001 rows against 1000 rows for IN and EXISTS clauses.
And the reason for that is the duplicate row we inserted.
If we look at the execution plans, we will notice that they have the same query cost of 33%.
The only difference over here is that the execution plan of the JOIN query is slightly different, but the cost seems to be the same.
In this particular condition, you are seeing that the execution plans for both the IN clause and the EXISTS clause are identical.
2. NOT EXISTS vs NOT IN vs JOIN with NOT NULLable columns:
Using the same two tables in the previous scenario and including the actual execution plan, execute the following three queries:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SET STATISTICS IO ON SET NOCOUNT OFF print'Using NOT IN Clause' SELECT ID, City FROM BigTable WHERE ID NOT IN (SELECT ID FROM SmallTable) GO print 'Using NOT Exists Clause' SELECT ID, City FROM BigTable WHERE NOT EXISTS (SELECT ID FROM SmallTable WHERE SmallTable.ID = BigTable.ID) GO Print 'Using LEFT JOIN' SELECT bt.ID, bt.City FROM BigTable bt LEFT JOIN SmallTable st ON bt.ID = st.ID WHERE st.ID IS NULL GO |
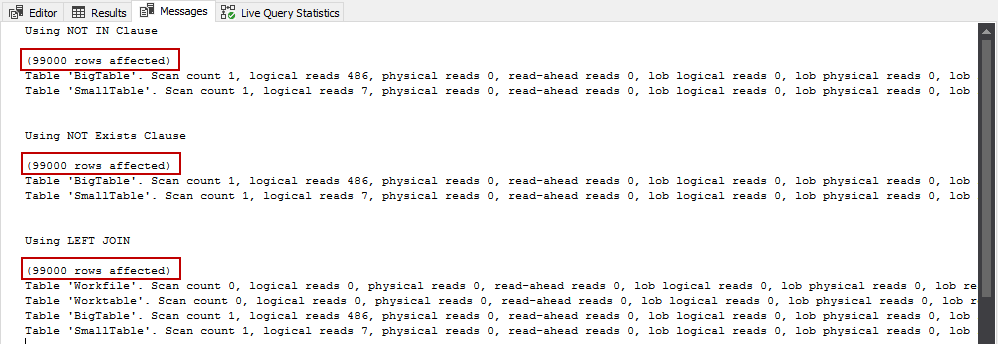
Here, the same number of records were returned for all of the three queries, but if we look at the execution plans in the following figure (see below) slightly different behavior can be noticed.
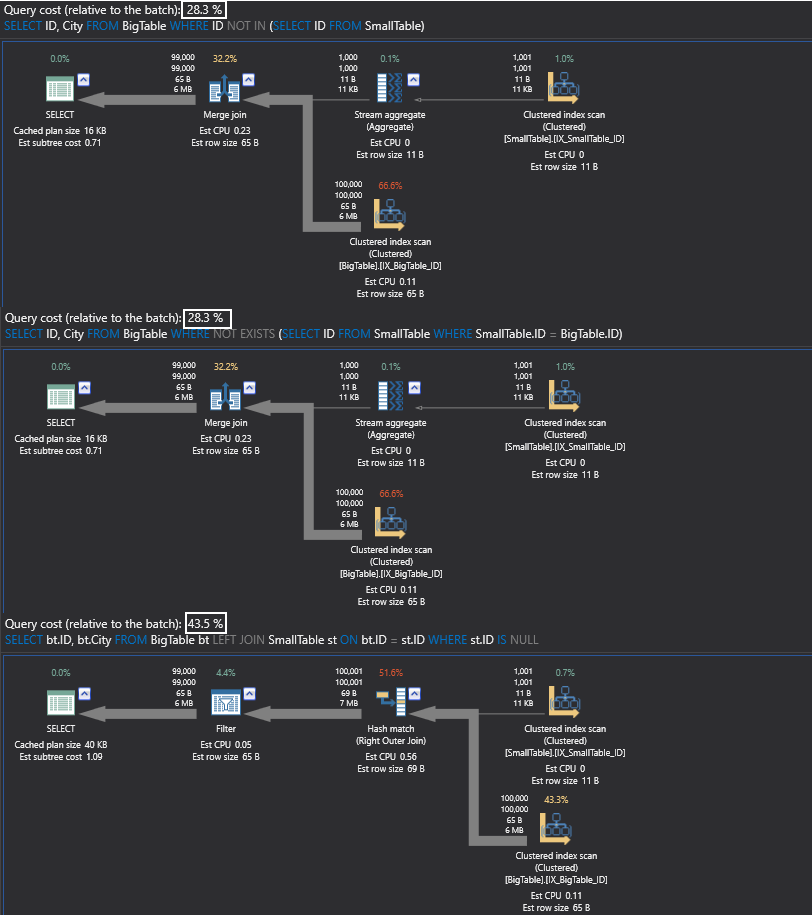
The NOT EXISTS and the NOT IN give me 28% relative cost.
And here I am seeing that the JOIN conditions are actually being more cost clear with 43% relative to the batch.
This is an interesting case, indeed. So, could you predict what will happen if we switch the tables in the previous query?
Let us check it out with the following query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SET STATISTICS IO ON SET NOCOUNT OFF print'Using NOT IN Clause' SELECT ID, City FROM SmallTable WHERE ID NOT IN (SELECT ID FROM BigTable) GO print 'Using NOT Exists Clause' SELECT ID, City FROM SmallTable WHERE NOT EXISTS (SELECT ID FROM BigTable WHERE SmallTable.ID = BigTable.ID) GO Print 'Using LEFT JOIN' SELECT bt.ID, bt.City FROM SmallTable st LEFT JOIN BigTable bt ON bt.ID = st.ID WHERE st.ID IS NULL GO |
Understanding that the small table is a subset of the big table, none of these queries are going to return you any result set.
But, what about the execution plans? Are they returning the same thing?
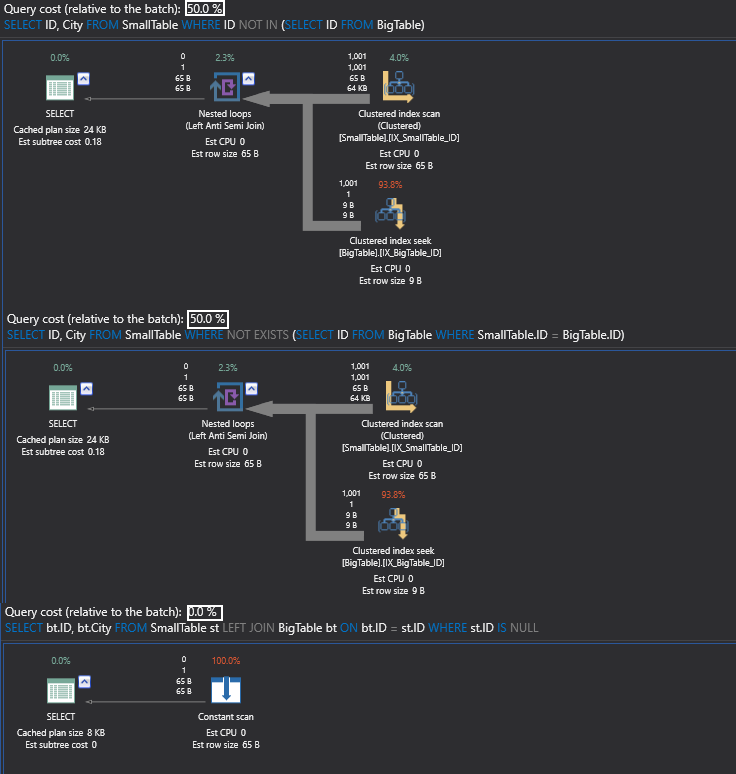
Interesting results … Now, the first and the second query are 50% relative to the batch.
And ironically the last query which is the LEFT JOIN is actually showing 0% relative percent and is doing a constant scan.
This is the power of the cost-based optimizer. SQL Server is intelligent enough in making a decision according to the integrity made behind the scenes.
Hence, 0 rows and a constant scan which means that SQL Server has not touched big table also.
This is the place where the cost based optimizer comes to the help and does the optimizations for you rather than us doing it based on a NOT EXISTS or NOT IN clauses.
3. EXISTS vs IN vs JOIN with NULLable columns:
After creating the same two tables, but with the ID column allowing null and filling them with the same data.
One small thing to mention here to make sure that all scenarios are covered is that EXISTS vs IN vs JOIN with NULLable columns will give you the same results and the same performance as what you get with NOT NULLABLE columns mentioned above.
4. NOT EXISTS vs NOT IN vs JOIN with NULLable columns:
We will see how a small change like allowing null values for ID column in both tables will make a big difference in the performance of the three clauses.
With including the actual execution plan, execute the following query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SET STATISTICS IO ON SET NOCOUNT OFF print'Using NOT IN Clause' SELECT ID, City FROM BigTable WHERE ID NOT IN (SELECT ID FROM SmallTable) GO print 'Using NOT Exists Clause' SELECT ID, City FROM BigTable WHERE NOT EXISTS (SELECT ID FROM SmallTable WHERE SmallTable.ID = BigTable.ID) GO Print 'Using LEFT JOIN' SELECT bt.ID, bt.City FROM BigTable bt LEFT JOIN SmallTable st ON bt.ID = st.ID WHERE st.ID IS NULL GO |
For sure, you will get the same number of records for each one
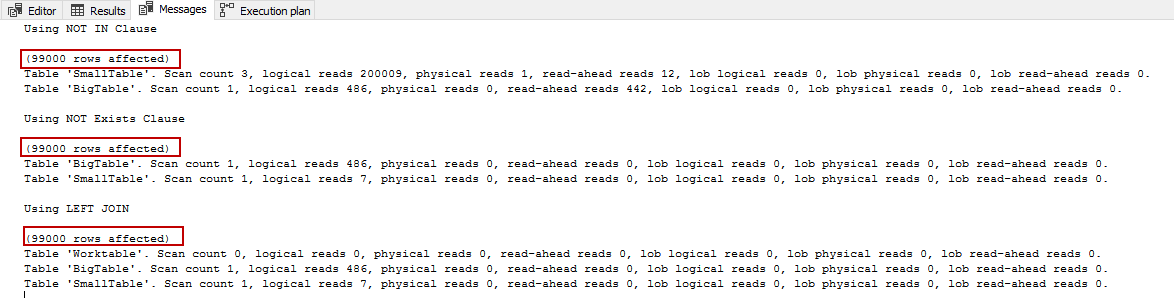
But let us check out the execution plans:
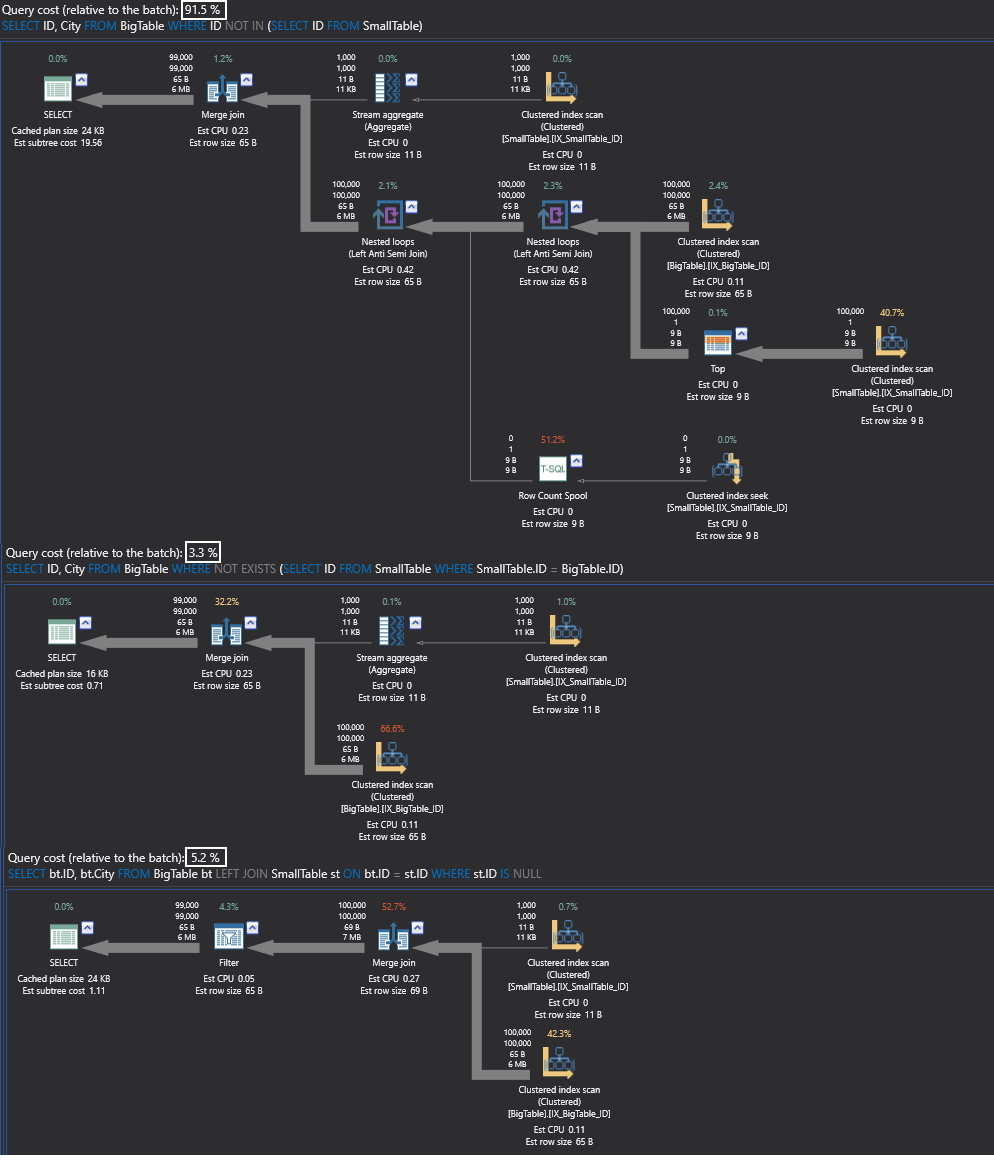
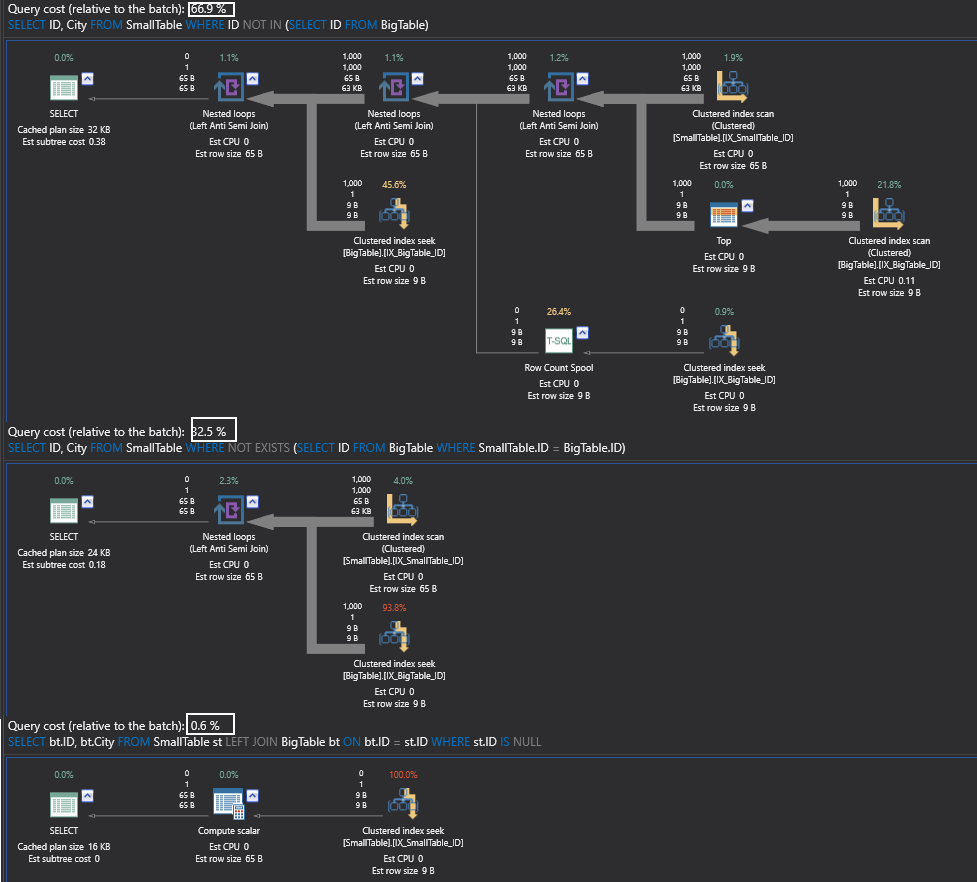
In this particular case, there is a NULLable column.
And here the NOT IN is actually getting you all the values from the table. That is why NOT IN is much costlier. Even when you switch the tables, NOT IN will still be the costliest query.
Summary
I have introduced here few aspects in the query design for getting better performance. I have tried several possible scenarios you may face in creating SQL queries as a developer. I hope this article has been informative for you.

Living in Egypt, have worked as Microsoft Senior SQL Server Database Administrator for more than 4 years.
As a DBA, I design, install, maintain and upgrade all databases (production and non-production environments), I have practical knowledge of T-SQL performance, HW performance issues, SQL Server replication, clustering solutions, and database designs for different kinds of systems. I worked on all SQL Server versions (2008, 2008R2, 2012, 2014 and 2016).
I love my job as the database is the most valuable thing in every place in the world now. That's why I won't stop learning. In my spare time, I like to read, speak, learn new things and write blogs and articles.
View all posts by Ayman Elnory
- SQL Server Query Execution Plans for beginners – NON-Clustered Index Operators - April 24, 2018
- SQL Server Query Execution Plans for beginners– Clustered Index Operators - March 5, 2018
- A walk through the SQL Server 2016 full database backup - February 12, 2018