

I would like to share one curios case that I recently came across.
Long story short:
This bug may lead to incorrect results if you use a partitioned table and the FORCESCAN hint.
Bug
Consider the following example, let’s keep it simple.
The following script creates partition function that has 4 ranges
- Range 1 – (…,0]
- Range 2 – (0,10]
- Range 3 – (10,100]
- Range 4 – (100,…)
Then the partition scheme on that function and the table partitioned by the clustered primary key. The table contains 4 values: 1, 10, 50, 100
Now run the script, creating the following test data and the queries (I added (select 1) to avoid simple parameterization, to keep it simple):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
use tempdb; go create partition function pf(int) as range for values (0, 10, 100) create partition scheme ps as partition pf all to ([primary]); go if object_id('t') is not null drop table t; create table t (a int primary key) on ps(a); insert t(a) values (1),(10),(50),(100); go select a,b=(select 1) from t where a < 100; select a,b=(select 1) from t with(forcescan) where a < 100; go |
Results

The first query returned results according to the specified predicate a < 100, among 1, 10, 50, 100 those are 1, 10, 50.
The second one is missing value 50! That is not what we expected.
Exploration
Before we are going to deep dive into details, I’d like to advise to refresh some background if needed. Here is a remarkable resource of information about how does the optimizer treats partitioned tables starting from the 2008 version: Partitioned Tables in SQL Server 2008.
Long story short with the quote:
“SQL Server 2005 treats partitioned tables specially and creates special plans, such as the above one, for partitioned tables. SQL Server 2008, on the other hand, for the most part treats partitioned tables as regular tables that just happen to be logically indexed on the partition id column. For example, for the purposes or query optimization and query execution, SQL Server 2008 treats the above table not as a heap but as an index on [PtnId]. If we create a partitioned index (clustered or non-clustered), SQL Server 2008 logically adds the partition id column as the first column of the index.”
Let us examine the query plans from the very right Clustered Index Seek operator of the first plan, that produces correct results, the Seek Predicates property.

You may observe two seek keys (not two seek predicates), the second one is what we specified in the query, and the query optimizer adds the first one automatically. The purpose for that is a Partition Elimination Technique.
This is an optimization trick to avoid accessing partitions, which the query would not touch to speed up execution. For example if we ask for “a < 100”, and the table is partitioned by a – why would we access partitions that do not contain the data and we know it beforehand. The partition range is determined, to eliminate useless.
There are two types of partition elimination static (our case, because we know the value 100 in “a < 100” predicate), and dynamic (if we use a parameter or a variable).
Both static and dynamic are vulnerable to the bug.
Back to our query plan, with that knowledge we may see that a partition elimination was involved by adding a predicate: Start: PtnId1000 >= Scalar Operator((1)); End: PtnId1000 <= Scalar Operator((3))
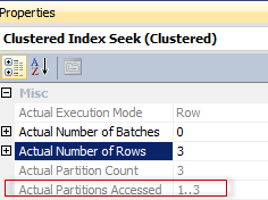
That means that the optimizer considering the partition function determined to scan Partitons 1 to 3.
We may determine it by exploring the Actual Plan property Actual Partition Accessed:

Now let’s examine the second query plan.

What we see is (from up to bottom):
Residual predicate (what we specified in the query predicate)
Static partition elimination, but, with a complex key, you see those delimiter “;” in the End property. We start seek from the partition 1 – PtnId1000>=Scalar Operator(1), and end up with: PtnId1000; [tempdb].[dbo].[t].a <= Scalar Operator((3)-(1)); Scalar Operator((100)).
Notice the bright red square – the partitions we are going to end with are (3)-(1)!
Indeed if we examine the plan property:

If we do a simple query to examine which partition each value belongs, we see that we obviously missed partition 3 for the value 50 that demands our predicate “a < 100”:
|
1 |
select a, PtnId = $partition.pf(a) from t |

We should access 3 of them.
Explanation
The Devil is in the detail. First, we should recall some theory of the query optimization process. Before the query execution plan is build the Query Optimizer builds a physical operator tree, a tree of the C++ objects in memory, that reflects the query logical demands, but already expressed in physical operators. Next the three is extracted and transformed to what we used to call a query plan. This process is known as post optimization rewrite.
One of those rewrites – is merging “filter and a scan operator” to “scan with residual”. Fortunately, there is one trace flag that disables this transformation. It is quite helpful for debugging SQL Server plans, and it would be helpful here also – a TF 9130.
When we enforce FORCESCAN hint we enforce the scan with residual predicate, but then it is rewritten during the post optimization rewrite phase to the Seek on partitioned index.
Now, what if we disable this “filter merging” thing and rewriting, and run the query with the magic TF:
|
1 2 |
select a,b=(select 1) from t with(forcescan) where a < 100; select a,b=(select 1) from t with(forcescan) where a < 100 option(querytraceon 9130); |
Plans:

Results:

We observe that when the filter is not combined with the scan for the partition table. We have an extra Filter operator and expected results. When it is combined – we have a Seek and wrong results.
Now we obviously see that this issue is not about the optimization of the query, but rewriting it to the query plan.
The question is – what it is done during that rewrite?
The optimizer tries the last chance to push down a predicate closer to the scan and succeeds. It calculates partition range for elimination – and that is where the error sits. It is doing the wrong math. It tries to consider both predicates – residual and seek, and combine them to determine the right range for partition elimination.
Lets run the following and examine the query plan Seek Predicate property:
|
1 2 |
select a,b=(select 1) from t where a < 100 and a > 10; select a,b=(select 1) from t with(forcescan) where a < 100 and a > 10; |
Results:

The second one has no rows at all!
Now the plans.
The first one has:

As you see, It has combined the start of the seek with “a > 10” predicate and calculated that for this condition it should start with Partition ID = 2 + 1. 1 – the first one partition, 2 –partition for the value 10. Totally 1+2 = 3 which value 50 corresponds to. The end of the scan is calculated correctly also because there is no RESIDUAL predicate – and it is 3. So, we scan only one partition with PtnID = 3. You may see it if you examine “Actual Partition Accessed” property.
The second one, does the same math for the start predicate, but unfortunately, add the residual one for the calculation and ends up with the following:

The condition for the partition elimination is
PtnID <= 3-1 and PtnID >=2+1, i.e – PtnID <= 2 and PtnID >=3 – obviously – no partitions and no rows for that.
Also, you may see that this plan has one Seek Key, but the firs one has two Seek Keys. Combining into the one Seek key and applying the same logic as there were two of them – leads to the wrong specification. It is not about the residual itself though, it is about how the predicates get combined to calculate the partition range. I may be wrong in subtle details, because I do not have a source code, but I think I’m right in general.
Solution
This is a bug and the only appropriate solution is to update the SQL Server. However, I don’t know if it is a known bug or not, it is not removed by 4199 TF (generally, I think “Uncorrected results” bugs are fixed without any TF), so I’ve file a Connect Item, feel free to vote – more votes, more attention – quicker fix.
As an immediate fix, if you do suffer from an appropriate results – remove the hint FORCEPLAN, or add WITH(INDEX(0)) – that would remove the error, but may lead to inefficient plan.
References
- Introduction to Partitioned Tables
- Partitioned Tables in SQL Server 2008
- Partitioned Indexes in SQL Server 2008
- Dynamic Partition Elimination Performance
See more
Check out ApexSQL Plan, to view SQL execution plans, including comparing plans, stored procedure performance profiling, missing index details, lazy profiling, wait times, plan execution history and more


Currently he works as a database developer lead, responsible for the development of production databases in a media research company. He is also an occasional speaker at various community events and tech conferences. His favorite topic to present is about the Query Processor and anything related to it. Dmitry is a Microsoft MVP for Data Platform since 2014.
View all posts by Dmitry Piliugin
- SQL Server 2017: Adaptive Join Internals - April 30, 2018
- SQL Server 2017: How to Get a Parallel Plan - April 28, 2018
- SQL Server 2017: Statistics to Compile a Query Plan - April 28, 2018