
What is a GUID?
GUID is a 16 byte binary SQL Server data type that is globally unique across tables, databases, and servers. The term GUID stands for Globally Unique Identifier and it is used interchangeably with UNIQUEIDENTIFIER.
To create a GUID in SQL Server, the NEWID() function is used as shown below:
|
1 |
SELECT NEWID() |
Execute the above line of SQL multiple times and you will see a different value every time. This is because the NEWID() function generates a unique value whenever you execute it.
To declare a variable of type GUID, the keyword used is UNIQUEIDENTIFIER as mentioned in the script below:
|
1 2 3 4 |
DECLARE @UNI UNIQUEIDENTIFIER SET @UNI = NEWID() SELECT @UNI |
As mentioned earlier, GUID values are unique across tables, databases, and servers. GUIDs can be considered as global primary keys. Local primary keys are used to uniquely identify records within a table. On the other hand, GUIDs can be used to uniquely identify records across tables, databases, and servers.
The Problem GUID Solves
Let’s see what issues we face if we have redundant records within tables across different databases and how GUID solves these issues.
Execute the following script.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE DATABASE EngDB GO USE EngDB GO CREATE TABLE EnglishStudents ( Id INT PRIMARY KEY IDENTITY, StudentName VARCHAR (50) ) GO INSERT INTO EnglishStudents VALUES ('Shane') INSERT INTO EnglishStudents VALUES ('Jonny') |
In the script above, we create a database named “EngDB”. We then create a table “EnglishStudents” within this database. The table has two columns: Id and StudentName. The Id column is the primary key column and we set it to auto increment using Identity as the constraint. Finally, we insert two records for students called ‘Shane’ and ‘Jonny’ into the “EnglishStudents” table.
Now if you select all the records from the “EnglishStudents” table, you should see the following output:
| Id | StudentName |
| 1 | Shane |
| 2 | Jonny |
Now, let’s create another database “MathDB”, create a table “MathStudents” in the DB and insert some records into the table. Execute the following script to do so.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE DATABASE MathDB GO USE MathDB GO CREATE TABLE MathStudents ( Id INT PRIMARY KEY IDENTITY, StudentName VARCHAR (50) ) GO INSERT INTO MathStudents VALUES ('Sally') INSERT INTO MathStudents VALUES ('Edward') |
The MathStudents table of the MathDB should have the following records.
| Id | StudentName |
| 1 | Sally |
| 2 | Edward |
Now if you select all the records from the EnglishStudents table of the EngDB and MathStudents table of the MathDB, you will see that records from both tables will have the same values for the primary key columns Id. Execute the following script to see this result:
|
1 2 |
SELECT * FROM EngDB.dbo.EnglishStudents SELECT * FROM MathDB.dbo.MathStudents |
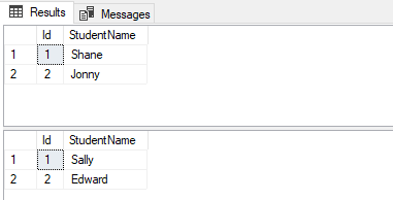
You will see the following output in SQL Server Management Studio

The student records from different tables that exist in two different databases have the same value for the Id column. This is the default behavior of SQL Server.
Now let’s create a new table “Student” that contains the union of all the records from the MathStudents table and EnglishStudents table. Execute the following script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
USE EngDB GO CREATE TABLE Students ( Id INT PRIMARY KEY, StudentName NVARCHAR (50) ) GO INSERT INTO Students SELECT * FROM EngDB.dbo.EnglishStudents UNION ALL SELECT * FROM MathDB.dbo.MathStudents |
In the above script, we create a new table “Students” in the EngDB. This table contains Id and StudentName columns.
If you try to run the above script, you will see an error:

This error is due to both the MathStudents and EnglishStudents table having the same values for the Id column which is also the primary key column for the newly created Students table. Therefore, when we try to insert the union of the records from MathStudents and EnglishStudents tables, the “Violation of PRIMARY KEY constraint” error occurs. Execute the following script to see what we are actually trying to insert in the Students table.
|
1 2 3 |
SELECT * FROM EngDB.dbo.EnglishStudents UNION ALL SELECT * FROM MathDB.dbo.MathStudents |

However, what if we want records to have unique values across multiple databases? For instance, we want that the Id column of the EnglishStudents table and the MathStudents table to have unique values, even if they belong to different databases. This is when we need to use the GUID data type.
You can see that students Shane and Sally both have Ids of 1 while Jonny and Edward both have Ids of 2. This causes the violation of primary key constraint for the Students table.
Solution with GUID
Now, let’s see how GUID can be used to solve this issue
Let’s create a table EngStudents1 within the EngDB but this time we change the data type of the Id column from INT to UNIQUEIDENTIFIER. To set a default value for the column we will use the default keyword and set the default value as the value returned by the ‘NEWID()’ function.
This will ensure that whenever a new record is inserted in the EngStudents1 table, by default, the NEWID() function generates a unique value for the Id column. When inserting the records, we simply have to specify “default” as value for the first column. This will insert a default unique value to the Id column. Execute the following script to create EngStudents1 table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE EngDB GO CREATE TABLE EnglishStudents1 ( Id UNIQUEIDENTIFIER PRIMARY KEY default NEWID(), StudentName VARCHAR (50) ) GO INSERT INTO EnglishStudents1 VALUES (default,'Shane') INSERT INTO EnglishStudents1 VALUES (default,'Jonny') |
Now if you select all the records from EnglishStudents1 table, you will a result that looks like this:
| Id | StudentName |
| 4B900A74-E2D9-4837-B9A4-9E828752716E | Jonny |
| AEDC617C-D035-4213-B55A-DAE5CDFCA366 | Shane |
Note: Your values for the Id column will be different from the ones shown in the above table, because they are generated randomly on the fly. However, they should be globally unique.
In the same way, create another table MathStudents1 in the MathDB database. Execute the following script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE MathDB GO CREATE TABLE MathStudents1 ( Id UNIQUEIDENTIFIER PRIMARY KEY default NEWID(), StudentName VARCHAR (50) ) GO INSERT INTO MathStudents1 VALUES (default,'Sally') INSERT INTO MathStudents1 VALUES (default,'Edward') |
Again if you try to retrieve all the records from the MathStudents1 table of the MathDB database, you will see results similar to the one below:
| Id | StudentName |
| 69121893-3AFC-4F92-85F3-40BB5E7C7E29 | Sally |
| CB77CCE6-C2CB-471B-BDD4-5DAC8C93B756 | Edward |
Now we have globally unique values in the Id columns of both the EnglishStudents1 and MathStudents1 table. Let’s create a new Table named Student1s and just as we did before, try to insert the union of the records from EnglishStudents1 and MathStudents1. This time we will see that there will be no “Violation of PRIMARY KEY constraint” error, since the values in the Id column of both EnglishStudents1 and MathStudents1 are unique across both the EngDB and MathDB databases.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
USE EngDB GO CREATE TABLE Students1 ( Id UNIQUEIDENTIFIER PRIMARY KEY, StudentName NVARCHAR (50) ) GO INSERT INTO Students1 SELECT * FROM EngDB.dbo.EnglishStudents1 UNION ALL SELECT * FROM MathDB.dbo.MathStudents1 |
You can see in the above script that the type of the Id column is UNIQUEIDENTIFIER. Run the above script and then try to retrieve all the records from the Students1 table and you should see results similar to the following:
| Id | StudentName |
| 69121893-3AFC-4F92-85F3-40BB5E7C7E29 | Sally |
| CB77CCE6-C2CB-471B-BDD4-5DAC8C93B756 | Edward |
| 4B900A74-E2D9-4837-B9A4-9E828752716E | Jonny |
| AEDC617C-D035-4213-B55A-DAE5CDFCA366 | Shane |
You can see that using GUID, we are able to insert a union of records from two different databases into a new table without any “Violation of PRIMARY KEY constraint” error.
References
Other great articles from Ben
| Difference between Identity & Sequence in SQL Server |
| What is the difference between Clustered and Non-Clustered Indexes in SQL Server? |
| Understanding the GUID data type in SQL Server |

View all posts by Ben Richardson
- Working with the SQL MIN function in SQL Server - May 12, 2022
- SQL percentage calculation examples in SQL Server - January 19, 2022
- Working with Power BI report themes - February 25, 2021