
We receive many database alerts with many of the alerts logging some of these same alerts or information to files or tables. What we’ve found over time is that the logging is now costing us quite a bit of resource. Our logging server (where both files and table logging are stored) has had a few outages related to conflicts from messages for other servers. We’ve considered scaling the alerting by environment type, but we’ve also considered that we may be logging too much information about our databases. In addition, since we receive so many alerts each day, it’s impossible for us to resolve them and assist with other issues that arise. What are some techniques that we can use to help us with the issue of too much logging information and too many alerts?
Overview
We often coordinate alerting with logging errors, where some errors become alerts. While we have situations where we want a detailed log of what happened, especially with some errors or application processes, we can over log information or retain information well after we need it and face an issue where our logging uses many resources. In a few cases, we may have a next step we can immediately run or try before logging if an event occurs. We’ll look at some scenarios about when intensive logging is useful and scenarios where we can reduce or eliminate it.
Logged messages require multiple steps to resolve
Suppose that we run a delete script, which removed 1 million rows of data in a database. This delete signals one of our applications to remove further related data in other databases, as our initial database is a starting point for our applications. Eventually, over 25 million rows of data are removed along with other records in other databases being updated for various applications, but we find an error: only 30% of the 1 million rows that were removed needed to be removed. This means that we have a significant amount of deletes to revert along with re-updating related information.
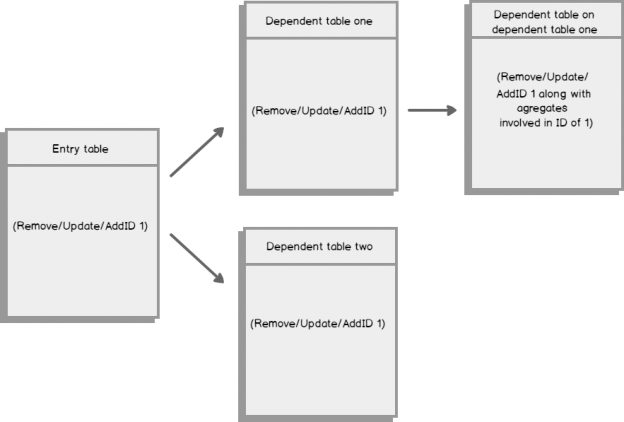
When we consider how we would log a delete where multiple databases are impacted, we would use intensive logging that would cost many resources; for an example:
- Log the deletes of the records in first database
- Log the deletes in all further databases, that use the first database as a resource
- Log the updates to all related database records
We could use change data tracking or queue tables to keep this information (the below code shows an example of using a queue table for this), but we have to keep at least one logging table of the delete operation so that further transactions can execute this same delete. The same would be true for an insert or update if we have further tables that must also be updated or added to with new or changed data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
---- Save our transaction prior to the transaction INSERT INTO tbQueue SELECT ID --- id of values being removed , 'D' --- operation , GETDATE() --- time , 0 --- processed yet in further tables FROM tbReport WHERE ID BETWEEN 13 AND 41 ---- Execute our transaction DELETE FROM tbReport WHERE ID BETWEEN 13 AND 41 ---- Using our queue table to execute removals or updates in tables dependent on our tbReport DELETE FROM OtherDatabase.dbo.DependentTableOne WHERE ID IN (SELECT ID FROM tbQueue WHERE Processed = 0) DELETE FROM OtherDatabase.dbo.DependentTableTwo WHERE ID IN (SELECT ID FROM tbQueue WHERE Processed = 0) |
This carries significant costs to log (not just in space, but we must design this in a manner in which we lose none of these records, or else we can’t revert a change), but without this, how would we accurately revert the original removal? Even if we did a multi-table removal, update or insert where we passed in one removal, update or insert at a time for all tables, upon reversion, we’d still need logging that allowed us to revert the change. A restore database operation is not always an option if a change creates further changes in other databases or tables.
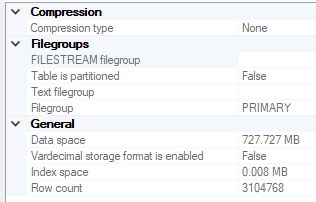
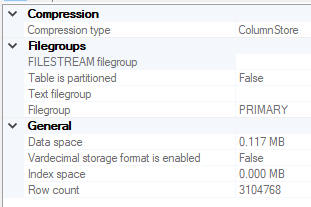
In these situations, we must keep extensive logs of information and I suggest that our logging tables use data compression techniques, such as row or page level compression or column store compression, which can reduce disk usage. In the below images, we see the effects of column store compression for a table that retains logging information from the error log:
|
1 |
CREATE CLUSTERED COLUMNSTORE INDEX CCI_tbSavedErrorLog ON tbSavedErrorLog |
Logged messages have a couple of solutions
In some cases, we may get extensive log messages on an error or successful messages that may not need to be kept, especially over longer periods of time. For example, most of us frequently run CHECKDB against all our databases on a schedule. In some cases, because our environment may be limited in resources, we may only retain the final CHECKDB message if it passes – whether by saving the output or retaining it from the error log, or we may only retain the latest successful CHECKDB result (assuming it was successful). When we find an error, we want the full error, even with the objects that passed, as we may have multiple steps that we follow or we may want additional information even if we fix the error – what could have caused corruption in the first place is a question we may be asking and want to know more information.

When CHECKDB fails – we need to know why it failed and how to resolve it. In this case, logging becomes very useful. The fact that CHECKDB passed seven years ago for our database when we run the command every 8 hours is less important to know and something we don’t need to retain. Since failed events like this require several possible solutions along with related information, we want to keep extensive logging for these types of events. As for successful CHECKDB messages and related logged messages like this, DBAs can decide how much and how long they want to keep the successful messages they receive based on their experience of when they may need them or under what circumstances.
In these situations, we may want to keep failures, related information upon failures, a reduced message on success, or archive or remove old logging in a shorter period. These situations require less logging than the first case, except in some situations, and they may also not need to be retained for a long period of time.
Logged messages have one solution or outcome
In some cases, if an error occurs, we have one solution or outcome after the error, or we may not need logging at all, but an immediate resolution. Suppose that we have a configuration table that we update on deployments – adding new records, updating existing records, and removing records. We could log the success or failure of the events after the script. We could also validate the script as we run it so that we avoid this additional logging, or significantly reduce it.
In the below example, we add one record and update two records to a configuration table and we validate that 3 total rows were added or changed (the @count variable) and we test that the report location we added is valid in our report dump table, where we would keep track of these locations;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
DECLARE @count INT = 0, @rptcount INT BEGIN TRAN ---- INSERT INTO tbConfigurables VALUES ('D:\Files\fields.rpt',GETDATE(),GETDATE()) SELECT @count += @@ROWCOUNT UPDATE tbConfigurables SET LocFile = '<data>17</data>' , EditDate = GETDATE() WHERE LocFile = '<data>12</data>' SELECT @count += @@ROWCOUNT SELECT @rptcount = COUNT(*) FROM tbReportLocations WHERE FileDump = 'D:\Files\fields.rpt' ---- Testing the changes: IF ((@count = 3) AND (@rptcount >= 1)) BEGIN COMMIT TRAN END ELSE BEGIN ROLLBACK TRAN END |
In some cases, we may not be able to perform this with values we change, as we may require application validation. An alternative route to this is to include a rollback script with every change. For example, to rollback the above script, we could add in a commented section below the script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
/* ---- Roll back script DELETE FROM tbConfigurables WHERE LocFile = 'D:\Files\fields.rpt' UPDATE tbConfigurables SET LocFile = '<data>12</data>' , EditDate = GETDATE() WHERE LocFile = '<data>17</data>' */ |
The result of this is that we don’t end up with extra information that doesn’t help us, or requires that we make more decisions when we only have one decision to make – the script and (or) validation of the script failed, which means the script needs to be rolled back. This approach holds true for some events that require one or two solutions when they occur, such as an event that always requires a restart or an event that always requires a cache flush, etc. We may want to only log what was executed and whether it passed, or alert with the immediate next step and avoid information that uses space for no reason.
In these situations, we want to solve as much as we can within the transaction or if we only have one action to take after a message. Logging the summary may be useful, but logging each step if on error we do one thing consumes unnecessary resources.
See also
Interested in reading the SQL Server transaction log? Consider ApexSQL Log, a 3rd party SQL Server transaction log reader, that renders transaction log information into a searchable, sortable grid and can produce Undo and Redo scripts.

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020