
In the previous articles of this series (see the full article TOC at bottom), we discussed the internal structure of the SQL Server tables and indexes, the best practices to follow when designing a proper index, the group of operations that you can perform on the SQL Server indexes, how to design effective Clustered and Non-clustered indexes and finally the different types of SQL Server indexes, above and beyond Clustered and Non-clustered indexes classification. In this article, we will discuss how to tune the performance of the bad queries using SQL Server Indexes.
Until this point, after getting full understanding about the SQL Server index concept, structure, design and types, we are ready to design the most effective SQL Server index that the SQL Server Query Optimizer will always take benefits from, in speeding up the data retrieval process on our queries, which is the main goal of creating an index, with the minimum disk I/O operations and the least system resources usage.
Before designing an index, that helps the query processor to find the data quickly and touching the underlying table as few times as possible, you should have good understanding of the underlying data structure and usage, the type of queries reading that data and the frequency the queries are run. As a database administrator, you can use different tools and scripts to provide the system owners with the list of suggested indexes that may enhance the performance of their system queries. But depending on their understanding of system behavior, they should provide the final confirmation of creating such indexes, only after examining the performance of the query on the development environment before and after creating the suggested index.
Database administrators have to balance between creating too many indexes and too few indexes. For example, there is no need to index every column individually or involve the column in many overlapping indexes. They should also take into consideration that, the index that will enhance the performance of SELECT queries will also slow down the different DML operations, such as INSERT, UPDATE and DELETE queries.
Another thing to consider is the tuning of the index itself, as the index that is working fine with your queries in the past may not fit the queries now, due to frequent changes in the table schema and data itself. This may require removing the index and create more effective one. We will discuss in detail in the next article, how to get information about index usage and decide if we need to keep or remove that index. On the other hand, the index may be suffering from fragmentation issues only due to changing the data very frequently, that can be resolved using the different index maintaining tasks, discussed deeply in the last article of this series.
Let us start our demo to understand the performance tuning concept practically. We will create a new database, IndexDemoDB, that contains three tables; the STD_Info table that contains the students’ information, the Courses table that contains the list of available courses and finally the STD_Evaluation table that contains the grades of the registered students in the available courses. The STD_Evaluation table contains two foreign keys; the ID of the student that references the STD-Info table and the ID of the course that reference the Courses table. The T-SQL script below is used to create the database and the tables as described:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
CREATE DATABASE IndexDemoDB GO CREATE TABLE STD_Info ( STD_ID INT IDENTITY (1,1) PRIMARY KEY, STD_Name VARCHAR (50), STD_BirthDate DATETIME, STD_Address VARCHAR (500) ) GO CREATE TABLE Courses ( Course_ID INT IDENTITY (1,1) PRIMARY KEY, Course_Name VARCHAR (50), Course_MaxGrade INT ) GO CREATE TABLE STD_Evaluation ( EV_ID INT IDENTITY (1,1), STD_ID INT, Course_ID INT, STD_Course_Grade INT, CONSTRAINT FK_STD_Evaluation_STD_Info FOREIGN KEY (STD_ID) REFERENCES STD_Info (STD_ID), CONSTRAINT FK_STD_Evaluation_Courses FOREIGN KEY (Course_ID) REFERENCES Courses (Course_ID) ) |
Once the database and the tables are created, with no index or key defined on the STD_Evaluation table, we will fill each table with 100K records, using ApexSQL Generate, as shown below:

Tuning a simple query
Reading from a table that has no index is similar to finding a word in a book by examining every single page in that book. If you try to execute the below SELECT query to retrieve data from the STD_Evaluation table, after enabling the TIME and IO statistics and including the execution plan, using the T-SQL statement below:
|
1 2 3 4 |
SET STATISTICS TIME ON SET STATISTICS IO ON GO SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530 |
You will see from the execution plan, generated after executing the query, that SQL Server will perform a Table Scan operation against that table by examining all table rows to check if these rows achieve the WHERE condition, as shown in the execution plan below:

You can see also from the TIME and IO statistics, that the query is executed within 655 ms, consuming 94 ms from the CPU time, as shown below:

Having an index in the front of the book will allow the reader finds their target faster. The same applies to the SQL Server tables; having an index on the table, will speed up the data retrieval process, providing the client with the requested data in shorter time, of course, if the index is designed properly.
If we look at the surface of the previous SELECT query and decide to add an index on the STD_ID column mentioned in the WHERE clause of that query, using the CREATE INDEX T-SQL statement below:
|
1 |
CREATE NONCLUSTERED INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] (STD_ID) |
Then execute the same SELECT statement:
|
1 |
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530 |
You will see from the execution plan, generated after executing the query, that SQL Server performs again Table Scan operation, to retrieve the data from that table, without considering the created index, as shown in the execution plan below:

Checking the TIME and IO statistics of the query, you will see that, the time required, and the CPU time consumed to execute the query is not very far from the previous SELECT statement without indexes, with tiny enhancement as shown below:

Having an index created on that table does not mean that SQL Server will necessarily use it. In some situations, SQL Server finds that scanning the underlying table is faster than using the index, especially when the table is small, or the query returns most of the table records.
Let us have a second look at the previous execution plan, you will see a green message from the SQL Server that recommends an index to improve the performance of that query with 77.75%. Right-click on that execution plan and choose Missing Index Details option, to show the suggested index, as shown below:

The same index suggestion can be also found by querying the sys.dm_db_missing_index_details dynamic management view, that returns detailed information about missing indexes, excluding spatial indexes, as shown below:
|
1 |
SELECT * FROM sys.dm_db_missing_index_details |
The previous query will suggest the same covering index, with the STD_ID that is used in the WHERE clause of the query as an index key and the rest of returned columns in the SELECT statement, EV_ID, Course_ID and STD_Course_Grade columns, as non-key columns in the INCLUDE clause of the index creation statement shown below:

We will drop the wrong index created previously and create a new index that is suggested by the SQL Server using the T-SQL script below:
|
1 2 3 4 5 6 7 8 |
USE [IndexDemoDB] GO DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] GO CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_STD_ID] ON [dbo].[STD_Evaluation] ([STD_ID]) INCLUDE ([EV_ID],[Course_ID],[STD_Course_Grade]) GO |
If you try to execute the same SELECT statement:
|
1 |
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530 |
Then check the execution plan, generated after executing the query, you will see that SQL Server will perform an Index Seek operation to retrieve the data to the user, as shown below:

The TIME and IO statistics will show that the time required to execute the query decreased from 655ms to 554ms, with about 15% enhancement after adding the index, and the consumed CPU time reduced from 94ms to 31ms, with about 67% enhancement when using the index. You can imagine the enhancement that can be gained in the case of large tables, as shown below:

The previous Non-clustered index is created over a heap table. We will drop the previously created Non-clustered index, create a Clustered index on the EV_ID column, then create the Non-clustered index again, using the T-SQL script below:
|
1 2 3 4 5 6 7 |
DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] GO CREATE CLUSTERED INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] ([EV_ID]) GO CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_STD_ID] ON [dbo].[STD_Evaluation] ([STD_ID]) INCLUDE ([EV_ID],[Course_ID],[STD_Course_Grade]) |
Recall what we mentioned in the previous articles of this series that the Non-clustered index will be rebuilt automatically when creating a Clustered index on the table in order to point to the Clustered key instead of pointing to the base table. If we execute the same SELECT statement again:
|
1 |
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530 |
You will see that the same execution plan will be created without any change from the previous one, as shown below:

In addition, the TIME and IO statistics will show that the time required to execute the query and the CPU time consumed by the query is somehow similar to the previous result, with a small enhancement in reducing the IO operations performed to retrieve the data, due to working with a small table, as shown below:

You may also think about replacing the Non-clustered index with a Clustered index on STD_ID column, taking into consideration that the Clustered index contains no INCLUDE clause. If we drop all indexes available on that table and replace it with only one Clustered index, using the T-SQL script below:
|
1 2 3 4 5 |
DROP INDEX IX_STD_Evaluation_STD_ID ON [STD_Evaluation] GO DROP INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] GO CREATE CLUSTERED INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] ([STD_ID]) |
Then execute the same SELECT statement:
|
1 |
SELECT * FROM [dbo].[STD_Evaluation] WHERE STD_ID < 1530 |
You will see from the generated execution plan, that a Clustered Index Seek operation will be performed to retrieve the requested data, as shown below:

With no noticeable enhancement in the TIME and IO statistics generated from executing the query, in the case of our small table, as shown below:

Tuning a complex query
Let us try now to tune the performance of more complex query, that returns the name of the student, the name of the course, the maximum grade of the course and finally the grade of the student in that grade, by joining the three previously created tables together based on the common columns between each two tables, taking into consideration that the STD_Evaluation table has no index on it, as shown in the SELECT statement below:
|
1 2 3 4 5 6 7 |
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320 |
If you check the execution plan generated after executing the query, you will see that, due to the fact that the STD_Evaluation has no index, SQL Server will scan all the STD_Evaluation table records to search for the rows that meet the WHERE clause condition, by performing a Table Scan operation. In addition, a green message will be displayed in the execution plan showing a suggested index from the SQL Server to enhance the performance of the query, as shown below:

Right-click on that execution plan and choose Missing Index Details option, to show the suggested index. The T-SQL statement that is used to create the new index, with the performance improvement percentage, which is 82% here, will be displayed in the appeared window, as shown below:

The TIME and IO statistics generated from executing the previous query shows that the SQL Server performs 310 logical reads, within 65ms and consumes 16ms from the CPU time in order to retrieve the data, as shown below:

The same index suggestion can be also found by querying the sys.dm_db_missing_index_details dynamic management view, that returns detailed information about missing indexes, excluding spatial indexes, as shown below:

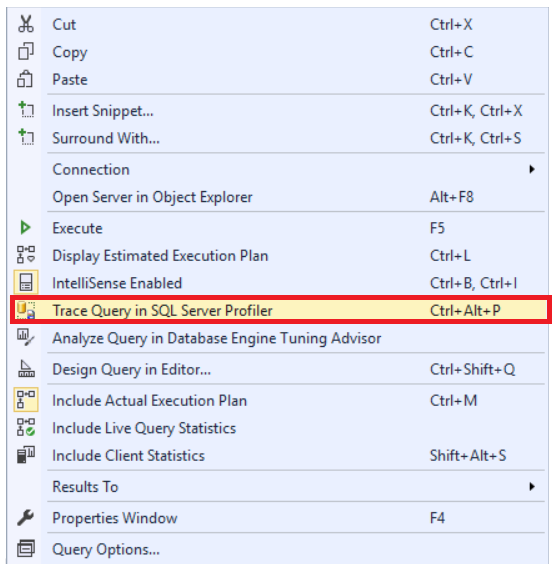
The performance of the query can be also tuned using the combination of the SQL Server Profiler and the Database Engine Tuning Advisor tools. Right-click on the query that you manage to tune and click on the Trace Query in SQL Server Profiler option, as shown below:

A new SQL Server Profiler session will be displayed. When you execute the query to be tuned, the query statistics will be caught in the opened SQL Server Profiler session, as shown in the snapshot below:

Save the previous trace in order to use it as the workload for the Database Engine Tuning Advisor. From the Tools menu of the SQL Server Management Studio, choose the Database Engine Tuning Advisor option, as shown below:

From the opened Database Engine Tuning Advisor window, connect to the target SQL Server, the database from which the query will retrieve data and finally allocate the workload file that contains the query trace, then click on
 as shown below:
as shown below:

Once the analysis operation completed successfully, recommendations that include indexes and statistics that could enhance the performance of the query, with the estimated enhancement percentage will be displayed on the generated report. In our case, the same previously suggested index will be displayed in the recommendations report, as shown below:

If we take the CREATE INDEX statement provided from the previous execution plan or from the Database Engine Tuning Advisor report and create that suggested index to enhance the query performance, as in the T-SQL statement below:
|
1 2 3 4 5 6 |
USE [IndexDemoDB] GO CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_Course_ID] ON [dbo].[STD_Evaluation] ([STD_ID],[Course_ID]) INCLUDE ([STD_Course_Grade]) GO |
Then execute the same SELECT statement:
|
1 2 3 4 5 6 7 |
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320 |
You will see from the generated execution plan, that the previous slow Table Scan operation changed to a fast Index Seek operation, as shown below:

The TIME and IO statistics also shows that, after creating the suggested index, SQL Server performs only 3 logical rea operations, compared with 310 logical reads before creating the index, with about 91% enhancement, within 40ms, compared with the 65ms required to execute the query before creating the index, with about 39% enhancement, and consume no CPU time compared with the 16ms consumed before creating the index, as shown clearly below:

The previous Non-clustered index is created over a heap table. We will drop the previously created Non-clustered index, create a Clustered index on the EV_ID column, then create the Non-clustered index again, using the T-SQL script below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE [IndexDemoDB] GO DROP INDEX [IX_STD_Evaluation_Course_ID] ON [dbo].[STD_Evaluation] GO CREATE CLUSTERED INDEX IX_Evaluation_EV_ID ON [STD_Evaluation] ([EV_ID]) GO CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_Course_ID] ON [dbo].[STD_Evaluation] ([STD_ID],[Course_ID]) INCLUDE ([STD_Course_Grade]) GO |
If you execute the same SELECT statement again:
|
1 2 3 4 5 6 7 |
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320 |
The same execution plan will be generated as shown below:

In addition, the TIME and IO statistics will show a slight enhancement in the logical reads number and the time required to execute the query, as we are working with a small table, as shown below:

In the previous articles of this series, we mentioned that the sorting order of the columns in the index key should match the same order of the columns in the query that the index will cover. To understand the reason in practical terms, let us perform the below two examples.
In the previously created index, the sorting order of the STD_ID and Course_ID columns is the default ASC sorting order. If we modify the SELECT query to sort the returned rows based on the STD_ID and Course_ID columns DESC, which is totally opposite to the columns order in the index, as shown in the T-SQL query below:
|
1 2 3 4 5 6 7 8 |
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320 ORDER BY ST.[STD_ID] DESC,C.[Course_ID] DESC |
You will see from the generated execution plan, that nothing will be changed, except for the Scan Direction of the Non-Clustered index that will be Backward, that can be viewed from the Index Seek node properties window. This means that, rather than reading the index from the top to the bottom, SQL Server will read the data from that index from the bottom to the top, without the need to sort the data again, as shown clearly below:

With the minimal backward reading overhead, the statistics are shown below:

Things will be different when modifying the query to retrieve the rows in an order that is very far from the sorting order in the index key. For example, if we modify the SELECT query to retrieve the data sorted based on the STD_ID column in ASC order and based on the Course_ID column in DESC order, as shown in the T-SQL statement below:
|
1 2 3 4 5 6 7 8 |
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320 ORDER BY ST.[STD_ID] ASC,C.[Course_ID] DESC |
SQL Server cannot derive benefit from the sorting order of the columns in the index, as it is very far from the requested order in the query, but still can still benefit from the index to retrieve the data, using Index Seek operation, then it should sort the rows returned from the index using the expensive Sort operation, as shown in the generated execution plan below:

You can see from the TIME statistics that the expensive Sort operation will slow down the query execution with a noticeable amount. This is why we keep saying that it is really important to match the sorting order of the columns in the index and the query that will take benefits from that index. The extra time overhead of the Sort operation is shown clearly below:

It is important to mention here that, indexing the columns individually may not be the optimal solution to enhance the performance of the query. Assume that we plan to index both the STD_ID and Course_ID columns that are used in the WHERE and JOIN conditions in the previous query, taking into consideration that the STD_Evaluation table has no index created on it, using the T-SQL script below:
|
1 2 3 4 5 6 |
CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_STD_ID] ON [dbo].[STD_Evaluation] ([STD_ID]) GO CREATE NONCLUSTERED INDEX [IX_STD_Evaluation_Course_ID] ON [dbo].[STD_Evaluation] (Course_ID) GO |
If you execute the same SELECT statement:
|
1 2 3 4 5 6 7 |
SELECT ST.[STD_Name] , C.[Course_Name], C.[Course_MaxGrade],EV.[STD_Course_Grade] FROM [dbo].[STD_Info] ST JOIN [dbo].[STD_Evaluation] EV ON ST.STD_ID =EV.[STD_ID] JOIN [dbo].[Courses] C ON C.Course_ID= EV.Course_ID WHERE ST.[STD_ID] > 1500 AND C.Course_ID >320 |
You will see from the execution plan, generated after executing the query that, the created indexes do not cover the previous query, that requires the SQL Server to perform an extra Key Lookup operation to retrieve the rest of columns that are not included in the created indexes from the base table, as shown below:

And the expensive cost of the Key Lookup operation will be translated into extra TIME cost as shown in the statistics below:

In this article, we translated the index design tips and tricks mentioned in the previous articles of this series in practical terms. Staty tuned for the next article, in which we will check the index information to keep the useful indexes and drop the bad ones.
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021