
SQL Data Sync is a service that allows synchronizing data across multiple Azure SQL databases and on-premises SQL Server databases.
In this article, a base concept of how the SQL Data Sync service works will be explained as well as what the requirements and limitations are when want to create data synchronization by using SQL Data Sync
To synchronize data and the period, the sync group needs to be created and the databases, tables and columns should be defined.
The base concept of data synchronization with SQL Data Sync is shown on the image below:

SQL Data Sync uses a hub- spoke topology to synchronize data. In the sync group (e.g. Sync Groupe 1), one database is defined as the Hub database (must be an Azure SQL database) and the rest of databases under the sync group are the members databases. The data synchronization appears between the Hub and individual member database only.
The member databases can be Azure SQL databases, on-premises SQL Server databases or SQL Server instance on Azure virtual machines.
The data synchronization direction (Sync) can go in both directions (bi-directional) or in one, from the hub database to a member database (Hub to Member) and vice versa, from a member database to the hub database (Member to Hub)
To synchronize data between on-premises SQL Server to the Azure (Hub) database the Local sync agent needs to be installed on the local machine. This agent communicates between Hub and on-premises SQL Server database. More about how to install and configure SQL Azure Data Sync Agent is explained in the How to Sync Azure database and on-premises database with SQL Data Sync article.
All member databases with the hub database and sync agent together make a sync group.
The sync group will be defined in the same region as hub database (e.g. West Europe region)
Also, we need another database to store all metadata and logs (Sync database). The Sync database needs to be in the same region as the Sync group.
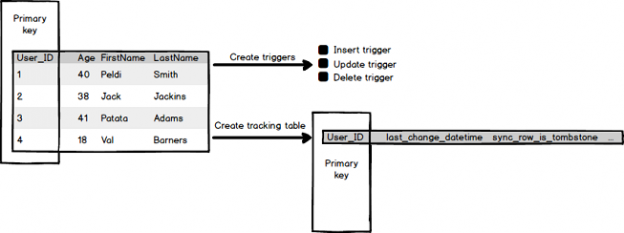
When the sync group is created, some database objects will be created in the production database to check the changes for each table being synched.
Those objects are update, insert, delete triggers:

Also, a tracking table is created to track the other changes which were made on your tables. This tracking table will have the same primary key as is defined in the tracked table. The tracking table has some other columns, but two most important columns are:

- last_change_datetime – indicates when the primary key is changed last time
- sync_row_is_tombstone – indicates when the row is deleted from the base (tracked) table

When the new record is inserted in a tracked table, a new record with the same primary key will be created in the tracking table to track the changes:

Now, user Jack (User_ID = 2) changes (updates) the age in the Age row and if that is done for the first time, then the new record in the tracking table will be created with the User_ID = 2:

Now, if in the tracked table the row with a User_ID = 5 is deleted, then in the tracking table for the User_ID = 5 under the sync_row_is_tombstone column the value will be changed from 0 to 1 to indicate that row was deleted:

And SQL Data Sync creates stored procedures to select and apply changes and add a user-defined table type, that are used for doing bulk change, too:

The hub database is sync with every member separately. Changes form the hub database will be downloaded to a member database and changes from a member database will be uploaded to the hub database.
In case of conflicts, there are the Hub wins and Member wins options for resolving of conflicts:
- Hub wins option always overwrites changes in a member database
- Member wins options always overwrites changes in the hub database. In case when in the sync group there are more members, the last value depends on which member syncs first
Requirements
Every table that should be synchronized must contain a primary key column
In case there is a need to change the primary key value, delete that column and then recreate it with the new primary key value
Snapshot isolation need to be enabled:
|
1 2 3 4 5 |
ALTER DATABASE Database SET ALLOW_SNAPSHOT_ISOLATION ON ALTER DATABASE Database SET READ_COMMITTED_SNAPSHOT ON |
Otherwise the following exception may appear when try to sync database:

Limitations
- An identity column that is not a column with a primary key, cannot be used in the tables that should be synchronized
- The datetime data type cannot be used for a primary key
- Maximum tables in one sync group is 500
- Maximum columns that one table can have in one sync group is 1000
- Minimal sync interval is 5 minutes
- SQL Data Sync doesn’t support Azure Active Directory authentication
More about SQL Data Sync requirements and limitations can be found on the Sync data across multiple cloud and on-premises databases with SQL Data Sync page.
Permissions
The SQL Data Sync synchronization operations require the following permissions:
-
Create table permissions for creating metadata tables (scope_info_dss, scope_config_dss, schema_dss, and provision_marker_dss) and tracking tables (table name_dss_tracking):

-
Alter table permissions to create Insert, Update, Delete triggers on tables that need to be synchronized:
- Create procedure permissions to create the procedures that SQL Data Sync uses
- Select permissions for scope_info_dss, scope_config_dss, schema_dss, and provision_marker_dss tables
- Insert Permission s for scope_info_dss, scope_config_dss, schema_dss, and provision_marker_dss tables
- Select permissions for table that should be synchronized
- Select, Insert, Update, and Delete permissions are required for tables that should be updated during synchronization process and for metadata tables
- Executed permissions for the stored procedures that SQL Data Sync uses to read and write to metadata tables and tables that should be synchronized



He is a prolific author of authoritative content related to SQL Server including a number of “platinum” articles (top 1% in terms of popularity and engagement). His writing covers a range of topics on MySQL and SQL Server including remote/linked servers, import/export, LocalDB, SSMS, and more.
In his part-time, Zivko likes basketball, foosball (table-soccer), and rock music.
See more about Marko at LinkedIn
View all posts by Marko Zivkovic
- How to connect to a remote MySQL server using SSL on Ubuntu - April 28, 2020
- How to install MySQL on Ubuntu - March 10, 2020
- Using SSH keys to connect to a remote MySQL Server - November 28, 2019