
In the previous articles in this series (see TOC at bottom), we wrote about the various feature of the SQL Server FILESTREAM. In SQL Server, we use replication to replicate the articles to the destination server. Consider a scenario in which we have the FILESTREAM database in our environment. We would also have the requirement to configure this database for SQL Server replication.
As you might have noticed reading through the previous articles, SQL Server FILESTREAM stores large objects into the file system. Therefore, this question came into my mind of whether it is possible to replicate FILESTREAM data as well. In this article, we are going to cover the steps to configure SQL Server replication for the FILESTREAM database.
Pre-requisites
We should have installed the SQL Server replication components on the server to configure it. The following error shows that replication is not installed on this instance of SQL Server.

We can install replication components using the SQL Server installer. You need to run the installer of the same version of the database instance. In my environment, I am working on the SQL Server 2019 CTP 2.0. Therefore, I launched the installer of it.
In the feature selection page, select ‘SQL Server Replication’ as per the following image.

Once we have installed the SQL Server replication component, we can start the configuration of SQL Server replication for the FILESTREAM database.
Before we start to configure SQL Server replication, let me give a brief introduction of the replication components.
- Publisher: it is the source database that we want to SQL Server replication
- Subscriber: It is the destination database in which we want to replicate the data
- Articles: in SQL Server replication, each object is called an ‘Article’
We need to have the following pre-configurations.

Now let us start the SQL Server replication configuration from the Source database.
-
Connect to the Publisher instance. Right click on the ‘Replication’ and select ‘New Publication’

It starts the following publication wizard.


Click ‘Next’ and configure the distribution. In this article, we are going to use the publisher instance as the distributor as well. It shows this option by default. It will create the distribution database in the default data and log directories.

In the following page, we need to configure the SQL Server Agent service to start automatically. If the SQL Server Agent service startup mode is manual, SQL Server replication will not work in sync automatically after a restart of SQL Service.

SQL Server creates a snapshot of the publisher database. We can specify the proper path for this. We should have sufficient free space in this drive as per the publisher database size and the FILESTREAM container size as well.

Now, in the following step, we need to select the publisher database.

Now, we need to select the necessary SQL Server replication type. We can have the following SQL replication types.
- Snapshot replication: In this SQL replication type, the publication database snapshot is applied to the subscriber database. No further changes are applied
- Transactional replication: this SQL replication type sends the transactions as well to the subscriber database for the articles configured in the SQL Server replication
- Peer to Peer replication: In this type of SQL replication, we can configure multiple peers to read and write the articles, and changes are propagated to all the nodes in the SQL replication
- Merge replication: In merge SQL replication, we can make changes to the data in the publisher and the subscriber as well and later all the data synchronizes between the publisher and the subscriber
In this article, we are going to configure transactional SQL Server replication for the FILESTREAM database.

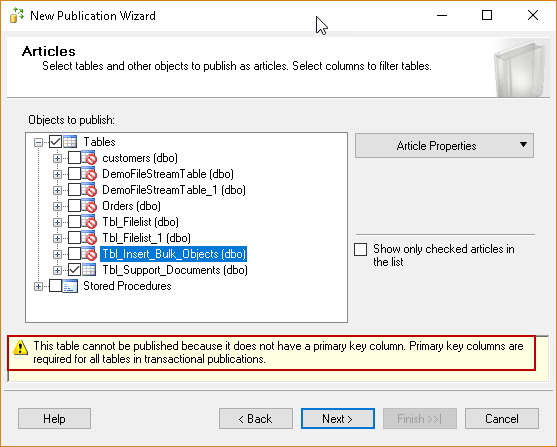
We need to select the objects from the publisher database. We should have the primary key on the object to configure replication on it. If we do not have any primary key on a particular object, we get an error message that the table cannot be published because it does not have a primary key defined on it.
Right click on the FILESTREAM table and ‘Design’.
Right click on the table and

In the table designer, right-click the required column and set the primary key on it. We set the primary key on the document_id column.

In the previous article, we did not specify the primary key on the FILESTREAM table. Therefore, you can create the primary key in the table designer using the steps above. Once we have created the primary key, you can check it using the below query.
|
1 |
Sp_help 'TBL_Support_Documents' |

I have already created a primary key on the ‘TBL_SUPPORT_DOCUMENTS’ table therefore in the following screenshot; you can see that we can configure transactional SQL replication on it.


In the next page, we can define the snapshot schedule for the publisher database. We want to do it immediately, therefore, leave the default option ‘Create the snapshot immediately and keep the snapshot available to initialize subscriptions’.

In the agent security page, we can define the service account for the log reader and the snapshot agent. We should set it to SQL Server Agent account as per best practice.

We have done the configuration stuff for the publication. In a further step, we can either generate a script for the SQL Server replication or create the publication.

Specify the publication name and finish.

SQL Server starts the SQL replication configuration, and you can see a progress report of it.

If there is any error or warning, you can see it in the message tab. We get the below message that SQL Server could not configure the SQL Server Agent to start automatically. It is fine at for this demo however in production you should set SQL Server Agent service startup mode as Automatic to avoid this warning.

In the local publication, you can see publication as per the following image.

Once we have the publication, right click on it and go to properties. In the ‘Article’ page, go to ‘Article properties’

By default, SQL Server replication converts FILESTREAM to MAX data types. In this configuration, we cannot store the FILESTREAM data at the file system on the subscriber database. We need to change the configuration as below.
Convert FILESTREAM to max data types: FALSE

Now we are ready to create the subscription. Right click on the publication and create a new subscriber.

It automatically shows the publication list. We can go ahead to configure the distribution agent.

We can have two kinds of subscriptions.
- Push subscriptions: All the changes at the publisher database will be replicated to the subscriber database automatically
- Pull subscription: Each subscriber will request the changes from the publisher to replicate data on the database
Let us go with the push subscription.

In the next step, we can select the subscriber database. As already highlighted, we should have this database prepared for the FILESTREAM feature of the SQL Server.

Configure the distribution agent security. We will go with the SQL Server Agent security.

We can prepare the synchronisation schedule as per our requirement. We want to have immediate synchronization.

In the next step, we will configure subscriber to initialize with the publication snapshot we created earlier.

We can generate the subscription script or create the subscription in the next window.

Verify the details in the summary page and click on ‘Finish’ to configure the subscription.

In the following image, we can see that subscription is created successfully for out SQL Server FILESTREAM publisher database.

You can see the subscription in the local subscriptions. We have created the publication and subscription on the same instance; therefore, you can see both publication and subscription here. If we have configured subscription database to be on a different instance, connect to it and check for the subscription.

Right-click database and launch the SQL Server replication monitor. We can see that SQL replication performance is excellent with zero latency. It shows we have replicated all the FILESTREAM table data from the publisher to subscriber.

Let us verify the FILESTREAM table count on both the publisher and subscriber database.
|
1 2 3 4 5 6 |
--Publisher database SELECT Count(*) as PublisherTableCount FROM [FileStreamDemoDB_test].[dbo].[Tbl_Support_Documents] --Subscriber database SELECT Count(*) as SubscriberCount FROM [FileStreamDemoDB_test].[dbo].[Tbl_Support_Documents] |
We have the same row count on both the publisher and subscriber database FILESTREAM table.

We have verified the table count here, but we need to check the files in the FILESTREAM container. We should have the files in the FILESTREAM container of the subscriber database as well. In the following screenshot of the FILESTREAM container, we can see the files in the subscription database file system as well.

Now we will insert one FILESTREAM object at the publisher database, and it should replicate to the subscriber database automatically. Run the below query on the Publisher database.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Use FileStreamDemoDB_test --Publisher Database DECLARE @File varbinary(MAX); SELECT @File = CAST( bulkcolumn as varbinary(max) ) FROM OPENROWSET(BULK 'C:\sqlshack\akshita.png', SINGLE_BLOB) as MyData; INSERT INTO [Tbl_Support_Documents] VALUES ( NEWID(), 'akshita.png', 'Test image Repl', @File ) |
Once the insert is successful, verify the FILESTREAM table count at both the publisher and subscriber end. Previously we had 11 rows, but we have 12 rows at both sides. It shows that the data is replicated successfully.

Now let us try to insert video file in the FILESTREAM table of the publisher database using the following query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Use FileStreamDemoDB_test --Publisher Database DECLARE @File varbinary(MAX); SELECT @File = CAST( bulkcolumn as varbinary(max) ) FROM OPENROWSET(BULK 'C:\sqlshack\VID_20131211_191448.3gp', SINGLE_BLOB) as MyData; INSERT INTO [Tbl_Support_Documents] VALUES ( NEWID(), 'VID_20131211_191448.3gp', 'Test Video Repl', @File ) |
We got the error message that length of the LOB data (270219122) to be replicated exceeds the configured maximum 65536.

Right click on the server instance and go to properties. In the advanced section, we can see the ‘Max text Replication size’ is defined as 65536 (64K). In the error message also, SQL Server reported this value. We need to modify this value to replicate the LOB data to the subscriber.

We can define ‘Max Text Replication Size’ up to 2147483647(2GB). Let us change it to the maximum value and click ‘Ok’. We do not need to restart SQL Server to activate this configuration.

Rerun the query, and it executes successfully. We can verify the FILESTREAM table count in the following image.

Conclusion
In this article, we explored to replicate SQL Server FILESTREAM data to a subscriber database. It is an excellent way to publish part of the database so that it can be used for reporting purposes. We will continue to cover more articles on FILESTREAM in this series. Stay tuned!
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023