
This article explores SQL Count Distinct operator for eliminating the duplicate rows in the result set.
A developer needs to get data from a SQL table with multiple conditions. Sometimes, we want to get all rows in a table but eliminate the available NULL values. Suppose we want to get distinct customer records that have placed an order last year.
Let’s go ahead and have a quick overview of SQL Count Function.
SQL Count Function
We use SQL Count aggregate function to get the number of rows in the output. Suppose we have a product table that holds records for all products sold by a company. We want to know the count of products sold during the last quarter. We can use SQL Count Function to return the number of rows in the specified condition.
The syntax of the SQL COUNT function:
COUNT ([ALL | DISTINCT] expression);
By default, SQL Server Count Function uses All keyword. It means that SQL Server counts all records in a table. It also includes the rows having duplicate values as well.
Let’s create a sample table and insert few records in it.
|
1 2 3 4 5 6 7 |
CREATE TABLE ##TestTable (Id int identity(1,1), Col1 char(1) NULL); INSERT INTO ##TestTable VALUES ('A'); INSERT INTO ##TestTable VALUES ('A'); INSERT INTO ##TestTable VALUES ('B'); INSERT INTO ##TestTable VALUES ('B'); INSERT INTO ##TestTable VALUES (NULL); INSERT INTO ##TestTable VALUES (NULL); |
In this table, we have duplicate values and NULL values as well.

In the following screenshot, we can note that:
- Count (*) includes duplicate values as well as NULL values
- Count (Col1) includes duplicate values but does not include NULL values

Suppose we want to know the distinct values available in the table. We can use SQL COUNT DISTINCT to do so.
|
1 2 |
Select count(DISTINCT COL1) from ##TestTable |
In the following output, we get only 2 rows. SQL COUNT Distinct does not eliminate duplicate and NULL values from the result set.

Let’s look at another example. In this example, we have a location table that consists of two columns City and State.
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE Location (City VARCHAR(30), State VARCHAR(20) ); Insert into location values('Gurgaon','Haryana') Insert into location values('Gurgaon','Rajasthan') Insert into location values('Jaipur','Rajasthan') Insert into location values('Jaipur','Haryana') |
Now, execute the following query to find out a count of the distinct city from the table.
|
1 2 |
SELECT COUNT(DISTINCT(City)) FROM Location; |
It returns the count of unique city count 2 (Gurgaon and Jaipur) from our result set.

If we look at the data, we have similar city name present in a different state as well. The combination of city and state is unique, and we do not want that unique combination to be eliminated from the output.
We can use SQL DISTINCT function on a combination of columns as well. It checks for the combination of values and removes if the combination is not unique.
|
1 2 |
SELECT DISTINCT City, State FROM Location; |
It does not remove the duplicate city names from the output because of a unique combination of values.

Let’s insert one more rows in the location table.
|
1 |
Insert into location values('Gurgaon','Haryana') |
We have 5 records in the location table. In the data, you can see we have one combination of city and state that is not unique.

Rerun the SELECT DISTINCT function, and it should return only 4 rows this time.

We cannot use SQL COUNT DISTINCT function directly with the multiple columns. You get the following error message.

We can use a temporary table to get records from the SQL DISTINCT function and then use count(*) to check the row counts.
|
1 2 3 4 |
SELECT DISTINCT City, State into #Temp FROM Location; Select count(*) from #Temp |
We get the row count 4 in the output.

If we use a combination of columns to get distinct values and any of the columns contain NULL values, it also becomes a unique combination for the SQL Server.
To verify this, let’s insert more records in the location table. We did not specify any state in this query.
|
1 2 |
Insert into location values('Gurgaon','') Insert into location(city)values('Gurgaon') |
Let’s look at the location table data.

Re-run the query to get distinct rows from the location table.
|
1 2 |
SELECT distinct City, State FROM Location; |
In the output, we can see it does not eliminate the combination of City and State with the blank or NULL values.

Similarly, you can see row count 6 with SQL COUNT DISTINCT function.

Difference between SELECT COUNT, COUNT(*) and SQL COUNT distinct
COUNT | Count(*) | Count(Distinct) |
It returns the total number of rows after satisfying conditions specified in the where clause. | It returns the total number of rows after satisfying conditions specified in the where clause. | It returns the distinct number of rows after satisfying conditions specified in the where clause. |
It gives the counts of rows. It does not eliminate duplicate values. | It considers all rows regardless of any duplicate, NULL values. | It gives a distinct number of rows after eliminating NULL and duplicate values. |
It eliminates the NULL values in the output. | It does not eliminate the NULL values in the output. | It eliminates the NULL values in the output. |
Execution Plan of SQL Count distinct function
Let’s look at the Actual Execution Plan of the SQL COUNT DISTINCT function. You need to enable the Actual Execution Plan from the SSMS Menu bar as shown below.

Execute the query to get an Actual execution plan. In this execution plan, you can see top resource consuming operators:
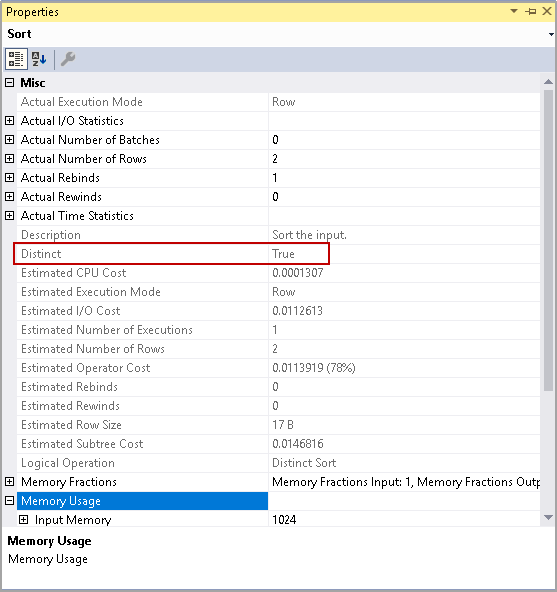
- Sort (Distinct Sort) – Cost 78%
- Table Scan – Cost 22%

You can hover the mouse over the sort operator, and it opens a tool-tip with the operator details.

In the properties windows, also we get more details around the sort operator including memory allocation, statistics, and the number of rows.

In a table with million records, SQL Count Distinct might cause performance issues because a distinct count operator is a costly operator in the actual execution plan.
SQL Server 2019 improves the performance of SQL COUNT DISTINCT operator using a new Approx_count_distinct function. This new function of SQL Server 2019 provides an approximate distinct count of the rows. There might be a slight difference in the SQL Count distinct and Approx_Count_distinct function output.
You can replace SQL COUNT DISTINCT with the keyword Approx_Count_distinct to use this function from SQL Server 2019.
|
1 2 |
SELECT APPROX_COUNT_DISTINCT(City) FROM Location; |

You can explore more on this function in The new SQL Server 2019 function Approx_Count_Distinct.
Conclusion
In this article, we explored the SQL COUNT Function with various examples. We also covered new SQL function Approx_Count_distinct available from SQL Server 2019. I would suggest reviewing them as per your environment. If you have any comments or questions, feel free to leave them in the comments below.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023