

Introduction
While building and deploying an SSAS OLAP cube, there are two processing orders that you can choose from when you create a process operation:
- Parallel (All Objects will be processed in a single transaction): Used for batch processing, all tasks run in parallel inside one transaction.
-
Sequential (Transaction mode):
- One Transaction: All Tasks are executed in one transaction
- Separate Transactions: Every Task is executed in one transaction
As mentioned above, when choosing a parallel processing order, tasks are processed in parallel (specific degree of parallelism) but if one task fails all operations are rolled back, even if it was the last one. This may lead to a serious problem when processing a huge OLAP cube that contains lots of partitions.
In a similar case, using a sequential processing order will decrease the processing performance since tasks are processed sequentially which delays delivery.
One of the best workarounds would be processing partitions using a parallel option but in batches; each process operation (batch) will contain a specific number of partitions (tasks). In case that an error occurs during processing phase, only one batch tasks are rolled back.
I proposed this approach for the first time as a solution to a similar problem on stackoverflow.com. Since it addresses a wide audience, I decided to improve it and write it as a separate article.
To learn to build a cube from scratch using SSAS, I would recommend you to run through this interesting article, How to build a cube from scratch using SQL Server Analysis Services (SSAS).
This article contains a step-by-step guide for implementing this processing logic within a SQL Server Integration Services package.
Prerequisites
In order to implement this process, you have to make sure that SQL Server Data Tools are installed to be able to create Integration Services packages and to use the Analysis Services tasks. More information can be found at Download and install SQL Server Data Tools (SSDT) for Visual Studio.
Also, the OLAP cube must be created and deployed (without processing dimensions and cube).
Creating a package and preparing the environment
Adding variables
First, we have to create a new Integration Services project using Visual Studio, and then we have to create all the needed variables as described below:
Variable name | Data type | Description |
inCount | Int32 | Stores unprocessed partitions count |
intCurrent | Int32 | Used within for loop container |
p_Cube | String | The OLAP cube object id |
p_Database | String | The SSAS database id |
p_MaxParallel | Int32 | Degree of parallelism |
p_MeasureGroup | String | The Measure Group object id |
p_ServerName | String | The Analysis Server Instance Name |
strProcessData | String | Stores XMLA to process partitions Data |
strProcessIndexes | String | Stores XMLA to process partitions indexes |
strProcessDimensions | String | Stores XMLA to process dimensions |
The following image shows the Variables Tab in Visual Studio.

Note that, all variables names starting with “p_” can be considered as parameters
Adding Connection Managers
After defining variables, we must create an OLE DB connection manager in order to connect to the SQL Server Analysis Service Instance:
- First, we must open the connection manager and configure it manually:

- Then we must open the Expression editor form from the properties Tab and set the Server name expression to @[User::p_ServerName] and Initial Catalog expression to @[User::p_Database] as shown in the image below:

- Rename the OLE DB connection manager to “ssas”:

Processing Dimensions
In order to process dimensions, we must use a Sequence Container to isolate the dimension processing within the package. Then we must add a Script Task to prepare the processing commands and an Analysis Services Processing Task to execute them:


In the Script Task configuration form, we must select @[User::p_Database], @[User::p_MaxParallel] as ReadOnly Variables and @[User::strProcessDimensions] as ReadWrite variable as shown in the image below:

Now, Open the Script editor and use the following code (C#):
The following code is to prepare the XMLA command to process the dimensions. We used AMO libraries to read the SSAS database objects, loop over the dimensions and generate the XMLA query to be used in the Analysis Services Processing Task:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
#region Namespaces using System; using System.Data; using System.Data.SqlClient; using Microsoft.SqlServer.Dts.Runtime; using System.Linq; using System.Windows.Forms; using Microsoft.AnalysisServices; #endregion namespace ST_00ad89f595124fa7bee9beb04b6ad3d9 { [Microsoft.SqlServer.Dts.Tasks.ScriptTask.SSISScriptTaskEntryPointAttribute] public partial class ScriptMain : Microsoft.SqlServer.Dts.Tasks.ScriptTask.VSTARTScriptObjectModelBase { public void Main() { Server myServer = new Server(); string ConnStr = Dts.Connections["ssas"].ConnectionString; myServer.Connect(ConnStr); Database db = myServer.Databases.GetByName(Dts.Variables["p_Database"].Value.ToString()); int maxparallel = (int)Dts.Variables["p_MaxParallel"].Value; var dimensions = db.Dimensions; string strData; strData = "<Batch xmlns=\"http://schemas.microsoft.com/analysisservices/2003/engine\"> \r\n <Parallel MaxParallel=\"" + maxparallel.ToString() + "\"> \r\n"; foreach (Dimension dim in dimensions) { strData += " <Process xmlns:xsd=\"http://www.w3.org/2001/XMLSchema\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\" xmlns:ddl2=\"http://schemas.microsoft.com/analysisservices/2003/engine/2\" xmlns:ddl2_2=\"http://schemas.microsoft.com/analysisservices/2003/engine/2/2\" xmlns:ddl100_100=\"http://schemas.microsoft.com/analysisservices/2008/engine/100/100\" xmlns:ddl200=\"http://schemas.microsoft.com/analysisservices/2010/engine/200\" xmlns:ddl200_200=\"http://schemas.microsoft.com/analysisservices/2010/engine/200/200\" xmlns:ddl300=\"http://schemas.microsoft.com/analysisservices/2011/engine/300\" xmlns:ddl300_300=\"http://schemas.microsoft.com/analysisservices/2011/engine/300/300\" xmlns:ddl400=\"http://schemas.microsoft.com/analysisservices/2012/engine/400\" xmlns:ddl400_400=\"http://schemas.microsoft.com/analysisservices/2012/engine/400/400\"> \r\n" + " <Object> \r\n" + " <DatabaseID>" + db.ID + "</DatabaseID> \r\n" + " <DimensionID>" + dim.ID + "</DimensionID> \r\n" + " </Object> \r\n" + " <Type>ProcessFull</Type> \r\n" + " <WriteBackTableCreation>UseExisting</WriteBackTableCreation> \r\n" + " </Process> \r\n"; } //} strData += " </Parallel> \r\n</Batch>"; Dts.Variables["strProcessDimensions"].Value = strData; Dts.TaskResult = (int)ScriptResults.Success; } #region ScriptResults declaration enum ScriptResults { Success = Microsoft.SqlServer.Dts.Runtime.DTSExecResult.Success, Failure = Microsoft.SqlServer.Dts.Runtime.DTSExecResult.Failure }; #endregion } } |
After configuring the Script Task, we have to open the Analysis Services Processing Task and to define any valid task manually, then from the Properties Tab we must open the expressions editor form and set the ProcessingCommands property to @[User::strProcessDimensions] variable as shown in the image below:

Get the unprocessed partitions count
In order to process partitions in batches, we must first to get the unprocessed partitions count in a measure group. This can be done using a Script Task. Open the Script Task configuration form, and select @[User::p_Cube], @[User::p_Database], @[User::p_MeasureGroup] , @[User::p_ServerName] variables as ReadOnly variables and @[User::intCount] as a ReadWrite variable as shown in the image below:

Open the Script Editor and write the following C# script:
This script reads the SSAS database objects using AMO libraries, and retrieves the number of unprocessed partitions within the OLAP cube Measure group, then stores this value within a variable to be used later.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
#region Namespaces using System; using System.Data; using Microsoft.SqlServer.Dts.Runtime; using System.Windows.Forms; using Microsoft.AnalysisServices; using System.Linq; #endregion namespace ST_e3da217e491640eca297900d57f46a85 { [Microsoft.SqlServer.Dts.Tasks.ScriptTask.SSISScriptTaskEntryPointAttribute] public partial class ScriptMain : Microsoft.SqlServer.Dts.Tasks.ScriptTask.VSTARTScriptObjectModelBase { public void Main() { // TODO: Add your code here Server myServer = new Server(); string ConnStr = Dts.Connections["ssas"].ConnectionString; myServer.Connect(ConnStr); Database db = myServer.Databases.GetByName(Dts.Variables["p_Database"].Value.ToString()); Cube objCube = db.Cubes.FindByName(Dts.Variables["p_Cube"].Value.ToString()); MeasureGroup objMeasureGroup = objCube.MeasureGroups[Dts.Variables["p_MeasureGroup"].Value.ToString()]; Dts.Variables["intCount"].Value = objMeasureGroup.Partitions.Cast<Partition>().Where(x => x.State != AnalysisState.Processed).Count(); Dts.TaskResult = (int)ScriptResults.Success; } #region ScriptResults declaration enum ScriptResults { Success = Microsoft.SqlServer.Dts.Runtime.DTSExecResult.Success, Failure = Microsoft.SqlServer.Dts.Runtime.DTSExecResult.Failure }; #endregion } } |
Process Partitions in batches
Finally, we have to create a For loop container to loop over OLAP cube partitions in chunks. In the For Loop Editor, make sure to set the For Loop Properties as following:
- InitExpression: @intCurrent = 0
- EvalExpression: @intCurrent < @intCount
- AssignExpression: @intCurrent + @p_MaxParallel
Make sure the For Loop Editor form looks like the following image:

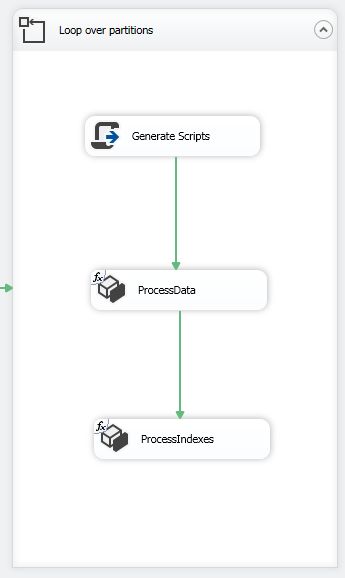
Within the For Loop container, add a Script Task to prepare the XMLA commands needed to process the Data and indexes of the partitions, and add two Analysis Services Processing Task to execute these commands as shown in the image below:

Open the Script Task configuration form and select @[User::p_Cube], @[User::p_Database], @[User::p_MaxParallel], @[User::p_MeasureGroup] as ReadOnly Variables, and select @[User::strProcessData], @[User::strProcessIndexes] as ReadWrite Variables. The Script Task Editor should looks like the following image:

In the script editor, write the following script:
The Script is to prepare the XMLA commands needed to process the partitions Data and Indexes separately. In this Script, we use AMO libraries to read SSAS database objects, loop over OLAP cube partitions and to generate two XMLA query that executes n partitions in parallel (10 in this example) as a single batch (one query for processing data and another one to process indexes). Then we store each XML query within a variable to be used in the SSAS processing task.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
#region Namespaces using System; using System.Data; using System.Data.SqlClient; using Microsoft.SqlServer.Dts.Runtime; using System.Linq; using System.Windows.Forms; using Microsoft.AnalysisServices; #endregion namespace ST_00ad89f595124fa7bee9beb04b6ad3d9 { [Microsoft.SqlServer.Dts.Tasks.ScriptTask.SSISScriptTaskEntryPointAttribute] public partial class ScriptMain : Microsoft.SqlServer.Dts.Tasks.ScriptTask.VSTARTScriptObjectModelBase { public void Main() { Server myServer = new Server(); string ConnStr = Dts.Connections["ssas"].ConnectionString; myServer.Connect(ConnStr); Database db = myServer.Databases.GetByName(Dts.Variables["p_Database"].Value.ToString()); Cube objCube = db.Cubes.FindByName(Dts.Variables["p_Cube"].Value.ToString()); MeasureGroup objMeasureGroup = objCube.MeasureGroups[Dts.Variables["p_MeasureGroup"].Value.ToString()]; int maxparallel = (int)Dts.Variables["p_MaxParallel"].Value; int intcount = objMeasureGroup.Partitions.Cast<Partition>().Where(x => x.State != AnalysisState.Processed).Count(); if (intcount > maxparallel) { intcount = maxparallel; } var partitions = objMeasureGroup.Partitions.Cast<Partition>().Where(x => x.State != AnalysisState.Processed).OrderBy(y => y.Name).Take(intcount); string strData, strIndexes; strData = "<Batch xmlns=\"http://schemas.microsoft.com/analysisservices/2003/engine\"> \r\n <Parallel MaxParallel=\"" + maxparallel.ToString() + "\"> \r\n"; strIndexes = "<Batch xmlns=\"http://schemas.microsoft.com/analysisservices/2003/engine\"> \r\n <Parallel MaxParallel=\"" + maxparallel.ToString() + "\"> \r\n"; string SQLConnStr = Dts.Variables["User::p_DatabaseConnection"].Value.ToString(); foreach (Partition prt in partitions) { strData += " <Process xmlns:xsd=\"http://www.w3.org/2001/XMLSchema\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\" xmlns:ddl2=\"http://schemas.microsoft.com/analysisservices/2003/engine/2\" xmlns:ddl2_2=\"http://schemas.microsoft.com/analysisservices/2003/engine/2/2\" xmlns:ddl100_100=\"http://schemas.microsoft.com/analysisservices/2008/engine/100/100\" xmlns:ddl200=\"http://schemas.microsoft.com/analysisservices/2010/engine/200\" xmlns:ddl200_200=\"http://schemas.microsoft.com/analysisservices/2010/engine/200/200\" xmlns:ddl300=\"http://schemas.microsoft.com/analysisservices/2011/engine/300\" xmlns:ddl300_300=\"http://schemas.microsoft.com/analysisservices/2011/engine/300/300\" xmlns:ddl400=\"http://schemas.microsoft.com/analysisservices/2012/engine/400\" xmlns:ddl400_400=\"http://schemas.microsoft.com/analysisservices/2012/engine/400/400\"> \r\n " + " <Object> \r\n " + " <DatabaseID>" + db.Name + "</DatabaseID> \r\n " + " <CubeID>" + objCube.ID + "</CubeID> \r\n " + " <MeasureGroupID>" + objMeasureGroup.ID + "</MeasureGroupID> \r\n " + " <PartitionID>" + prt.ID + "</PartitionID> \r\n " + " </Object> \r\n " + " <Type>ProcessData</Type> \r\n " + " <WriteBackTableCreation>UseExisting</WriteBackTableCreation> \r\n " + " </Process> \r\n"; strIndexes += " <Process xmlns:xsd=\"http://www.w3.org/2001/XMLSchema\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\" xmlns:ddl2=\"http://schemas.microsoft.com/analysisservices/2003/engine/2\" xmlns:ddl2_2=\"http://schemas.microsoft.com/analysisservices/2003/engine/2/2\" xmlns:ddl100_100=\"http://schemas.microsoft.com/analysisservices/2008/engine/100/100\" xmlns:ddl200=\"http://schemas.microsoft.com/analysisservices/2010/engine/200\" xmlns:ddl200_200=\"http://schemas.microsoft.com/analysisservices/2010/engine/200/200\" xmlns:ddl300=\"http://schemas.microsoft.com/analysisservices/2011/engine/300\" xmlns:ddl300_300=\"http://schemas.microsoft.com/analysisservices/2011/engine/300/300\" xmlns:ddl400=\"http://schemas.microsoft.com/analysisservices/2012/engine/400\" xmlns:ddl400_400=\"http://schemas.microsoft.com/analysisservices/2012/engine/400/400\"> \r\n " + " <Object> \r\n " + " <DatabaseID>" + db.Name + "</DatabaseID> \r\n " + " <CubeID>" + objCube.ID + "</CubeID> \r\n " + " <MeasureGroupID>" + objMeasureGroup.ID + "</MeasureGroupID> \r\n " + " <PartitionID>" + prt.ID + "</PartitionID> \r\n " + " </Object> \r\n " + " <Type>ProcessIndexes</Type> \r\n " + " <WriteBackTableCreation>UseExisting</WriteBackTableCreation> \r\n " + " </Process> \r\n"; } strData += " </Parallel> \r\n</Batch>"; strIndexes += " </Parallel> \r\n</Batch>"; Dts.Variables["strProcessData"].Value = strData; Dts.Variables["strProcessIndexes"].Value = strIndexes; Dts.TaskResult = (int)ScriptResults.Success; } #region ScriptResults declaration enum ScriptResults { Success = Microsoft.SqlServer.Dts.Runtime.DTSExecResult.Success, Failure = Microsoft.SqlServer.Dts.Runtime.DTSExecResult.Failure }; #endregion } } |
Now Open both Analysis Services Processing Task and define any valid task manually (just to validate the task). , then from the Properties Tab we must open the expressions editor form and set the ProcessingCommands property to @[User::strProcessData] variable in the First Task and @[User::strProcessIndexes] in the second one.
The package control flow should looks like the following:

Now, the package is ready. If an error occurs during processing, only the current batch will rollback.
Disadvantages and Possible improvements
One of the most critical disadvantages of this approach is that it can lead to inconsistent values if the OLAP cube is online and not all partitions are processed. Therefore, it has to be executed in off-hours or on a separate server then deployed to the production server after being processed.
Besides this, many improvements can be done for this process:
- We can configure some logging tasks to track the package progress, especially when dealing with a huge number of partitions
- This example is to process one measure group partitions; it can be expanded to manipulate all measure groups defined in the OLAP cube. To do that, we need to add a Script Task to get all measure groups in the SSAS database, then we should add a Foreach Loop container (Variable enumerator) to loop over measure groups and put the For loop container we already created within it
Some helpful Links
In the end, I will provide some external links that contain additional information that can serve to improve this solution:
See more
Check out SpotLight, a free, cloud based SQL Server monitoring tool to easily detect, monitor, and solve SQL Server performance problems on any device


Besides working with SQL Server, he worked with different data technologies such as NoSQL databases, Hadoop, Apache Spark. He is a MongoDB, Neo4j, and ArangoDB certified professional.
On the academic level, Hadi holds two master's degrees in computer science and business computing. Currently, he is a Ph.D. candidate in data science focusing on Big Data quality assessment techniques.
Hadi really enjoys learning new things everyday and sharing his knowledge. You can reach him on his personal website.
View all posts by Hadi Fadlallah
- An overview of SQL Server monitoring tools - December 12, 2023
- Different methods for monitoring MongoDB databases - June 14, 2023
- Learn SQL: Insert multiple rows commands - March 6, 2023