
In this article, we will explore SQL Server ALTER TABLE ADD Column statements to add column(s) to an existing table. We will also understand the impact of adding a column with a default value and adding and updating the column with a value later on larger tables.
As a database developer, you need to add columns to the existing tables too offen. You would think that adding a column to the SQL Server database table would not be a major deal. Sometimes you might be adding the column from the SQL Server Management Studio itself. Well, that would be fine for a small table or a table which does not have a large number of transactions. Let’s go ahead and see how we can add columns to an existing table and also understand the reasons and the best practices to add a column to a table that is large in size.
Sample Table
Let us create a sample table with sufficient data set from the following script.
|
1 2 3 4 5 6 7 8 9 |
IF EXISTS (SELECT 1 FROM Sys.tables where Name = 'SampleTable') DROP TABLE SampleTable CREATE TABLE dbo.SampleTable ( ID BIGINT IDENTITY (1,1) NOT NULL PRIMARY KEY CLUSTERED, DateTime4 DATETIME DEFAULT GETDATE(), Column1 CHAR(1000) DEFAULT 'MMMMMMMMMMMMMMMMM', Column2 CHAR(2000) DEFAULT 'YYYYYYYYYYYYYYYYY' ) |
The above script will create a sample table called SampleTable. Data fields are added so that the large size table will be created. Next, a large number of records were added by executing the following query multiple times.
|
1 2 3 4 5 6 |
SET NOCOUNT ON INSERT INTO SampleTable (DateTime4, Column1, Column2) VALUES (GETDATE(),'XXXX','YYYY') GO 500000 |
After the above query is executed, 500,000 records are updated to the SampleTable. After executing the above query following is the table size and other parameters for the table.
This can be retrieved by sp_spaceused ‘SampleTable’

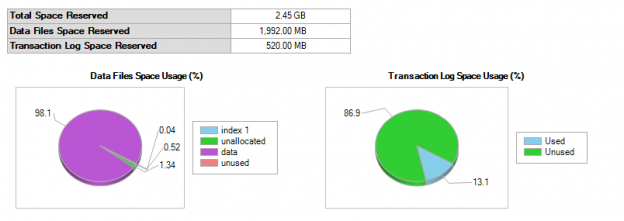
The following is the database size for data and the log file.

Let’s quickly go over the syntax of adding one column to an existing table by using ALTER TABLE ADD statement as shown below.
|
1 2 |
ALTER TABLE tbl_name ADD Col_name data_type col_constraint; |
You can use the below statement to add column NewColumn1 to our table SampleTable.
|
1 2 |
ALTER TABLE SampleTable ADD NewColumn1 varchar(200) |
Also, you can add multiple columns to a table using the single SQL Server ALTER TABLE statement as below.
|
1 2 3 |
ALTER TABLE SampleTable ADD NewColumn2 varchar(20), NewColumn3 varchar(50) |
When adding a column to a large table, typically you want to add the column and fill the added column with a default value. For example, if you want to add a status column, next is to fill the column with a default value.
Adding a Column with a Default Constraints
To achieve the above objective, the easiest way is to add a column with a default constraint. When the default column is added, the default value will be added to the table. The following script makes use of SQL Server ALTER TABLE ADD Column (Status in our case) statement to add a column named Status with default constraint.
|
1 2 3 |
ALTER TABLE SampleTable ADD Status CHAR(5000) DEFAULT 'INC' WITH VALUES |
When the column is added as above, the Status column will be added with the Value INC for all records.
From the profiler following statics are captured via SQL Profiler during the column addition with default values.
CPU | 0 |
Reads | 185 |
Writes | 0 |
Duration Mille Seconds | 65 |
You can see that the column is added to the table even less than one second and operation is very minimal cost.
The following are the locking stats during the column that are added with a constraint.
Resource Type | Resource Subtype | Request Mode | Records Count |
DATABASE | S | 1 | |
DATABASE | DDL | S | 1 |
KEY | X | 11 | |
METADATA | DATA_SPACE | Sch-S | 1 |
OBJECT | IX | 6 | |
OBJECT | Sch-M | 2 |
Please note that the following query should be executed in an open transaction in order to capture the above locking statistics.
|
1 2 3 4 5 6 7 8 9 |
SELECT resource_type, resource_subtype, request_mode, COUNT(*) FROM sys.dm_tran_locks WHERE request_session_id = @@SPID GROUP BY resource_type, resource_subtype, request_mode |
This shows that Table (Object) has intended Exclusive lock which means that the table is not exclusively locked during the addition of the column. Also, adding a column with default value has not taken even a one minute though it has 500,000 records.
Let us see the table size.

You will see that nothing has changed.
Let us see the file sizes of the database.

Nothing much has changed to the data file as well as for the log file. All of these results indicate that adding a column with a default constraint will result in only a metadata change.
Update with a Value
Let us update the same column with a different value and let us get the same stats.
Resource Type | Request Mode | Records Count |
DATABASE | S | 1 |
OBJECT | X | 1 |
The above table shows that the table is exclusively locked which means that the table is not accessible during the update.
Let us look at the table size.

The table has grown by some value as shown in the above figure.
The following are the details for the query expenses captured from the SQL Profiler.
CPU | 29,781 |
Reads | 9,188,986 |
Writes | 527,436 |
Duration Mille Seconds | 1,113,142 |
Evidently, when updating a column for a large table, resource consumption is high.
The following is the database file sizes when the column is added and updated the values.

These stats show that there is a remarkable difference between adding a column with a default value and adding a column and updating the column with a value later. During the column update, the transaction log will grow and exclusive locking will be placed on the table prohibiting any reads or writes to the table.
What is the difference in these scenarios? Prior to the SQL Server 2012, when adding a column with default value will cause the same behavior. In SQL Server 2012 and onwards, this is no longer the situation, the column is added online to the table and no update occurs and it is only a metadata change.
How This is Achieved
This is achieved by a somewhat very simple but novel approach. sys.system_internals_partition_columns DMV has two additional columns named has_default and default_value as shown below.

So when the column added with a default value, it will not update the data page instead it will update this system table. When a row is updated, then the default value will be pushed to the table even if the default value column is not updated.
Now, the next question is what if the Default constraint is dropped just after it is created. In that scenario, still, the above setting will prevail hence the previously set default value will be kept.
Conclusion
We covered the basic syntax of SQL Server ALTER TABLE in this article and implemented it to add columns to an existing table.
Before SQL Server 2012, there was no difference between adding a column with the default and adding a column and updating it. Therefore, in the prior SQL Server 2012 era, rather than adding a column with a default constraint, it is better to add a column and updating with batches so that the table is not exclusively locked.
However, from SQL Server 2012 onwards, the approach has changed so that adding a column with default constraints is much better.

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021