
This article explains the process of performing SQL delete activity for duplicate rows from a SQL table.
Introduction
We should follow certain best practices while designing objects in SQL Server. For example, a table should have primary keys, identity columns, clustered and non-clustered indexes, constraints to ensure data integrity and performance. Even we follow the best practices, and we might face issues such as duplicate rows. We might also get these data in intermediate tables in data import, and we want to remove duplicate rows before actually inserting them in the production tables.
Suppose your SQL table contains duplicate rows and you want to remove those duplicate rows. Many times, we face these issues. It is a best practice as well to use the relevant keys, constrains to eliminate the possibility of duplicate rows however if we have duplicate rows already in the table. We need to follow specific methods to clean up duplicate data. This article explores the different methods to remove duplicate data from the SQL table.
Let’s create a sample Employee table and insert a few records in it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TABLE Employee ( [ID] INT identity(1,1), [FirstName] Varchar(100), [LastName] Varchar(100), [Country] Varchar(100), ) GO Insert into Employee ([FirstName],[LastName],[Country] )values('Raj','Gupta','India'), ('Raj','Gupta','India'), ('Mohan','Kumar','USA'), ('James','Barry','UK'), ('James','Barry','UK'), ('James','Barry','UK') |
In the table, we have a few duplicate records, and we need to remove them.
SQL delete duplicate Rows using Group By and having clause
In this method, we use the SQL GROUP BY clause to identify the duplicate rows. The Group By clause groups data as per the defined columns and we can use the COUNT function to check the occurrence of a row.
For example, execute the following query, and we get those records having occurrence greater than 1 in the Employee table.
|
1 2 3 4 5 6 7 8 9 |
SELECT [FirstName], [LastName], [Country], COUNT(*) AS CNT FROM [SampleDB].[dbo].[Employee] GROUP BY [FirstName], [LastName], [Country] HAVING COUNT(*) > 1; |

In the output above, we have two duplicate records with ID 1 and 3.
- Emp ID 1 has two occurrences in the Employee table
- Emp ID 3 has three occurrences in the Employee table
We require to keep a single row and remove the duplicate rows. We need to remove only duplicate rows from the table. For example, the EmpID 1 appears two times in the table. We want to remove only one occurrence of it.
We use the SQL MAX function to calculate the max id of each data row.
|
1 2 3 4 5 6 7 8 9 10 |
SELECT * FROM [SampleDB].[dbo].[Employee] WHERE ID NOT IN ( SELECT MAX(ID) FROM [SampleDB].[dbo].[Employee] GROUP BY [FirstName], [LastName], [Country] ); |
In the following screenshot, we can see that the above Select statement excludes the Max id of each duplicate row and we get only the minimum ID value.
 To remove this data, replace the first Select with the SQL delete statement as per the following query.
To remove this data, replace the first Select with the SQL delete statement as per the following query.
|
1 2 3 4 5 6 7 8 9 |
DELETE FROM [SampleDB].[dbo].[Employee] WHERE ID NOT IN ( SELECT MAX(ID) AS MaxRecordID FROM [SampleDB].[dbo].[Employee] GROUP BY [FirstName], [LastName], [Country] ); |
Once you execute the delete statement, perform a select on an Employee table, and we get the following records that do not contain duplicate rows.

SQL delete duplicate Rows using Common Table Expressions (CTE)
We can use Common Table Expressions commonly known as CTE to remove duplicate rows in SQL Server. It is available starting from SQL Server 2005.
We use a SQL ROW_NUMBER function, and it adds a unique sequential row number for the row.
In the following CTE, it partitions the data using the PARTITION BY clause for the [Firstname], [Lastname] and [Country] column and generates a row number for each row.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
WITH CTE([firstname], [lastname], [country], duplicatecount) AS (SELECT [firstname], [lastname], [country], ROW_NUMBER() OVER(PARTITION BY [firstname], [lastname], [country] ORDER BY id) AS DuplicateCount FROM [SampleDB].[dbo].[employee]) SELECT * FROM CTE; |
In the output, if any row has the value of [DuplicateCount] column greater than 1, it shows that it is a duplicate row.

We can remove the duplicate rows using the following CTE.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
WITH CTE([FirstName], [LastName], [Country], DuplicateCount) AS (SELECT [FirstName], [LastName], [Country], ROW_NUMBER() OVER(PARTITION BY [FirstName], [LastName], [Country] ORDER BY ID) AS DuplicateCount FROM [SampleDB].[dbo].[Employee]) DELETE FROM CTE WHERE DuplicateCount > 1; |
It removes the rows having the value of [DuplicateCount] greater than 1
RANK function to SQL delete duplicate rows
We can use the SQL RANK function to remove the duplicate rows as well. SQL RANK function gives unique row ID for each row irrespective of the duplicate row.
In the following query, we use a RANK function with the PARTITION BY clause. The PARTITION BY clause prepares a subset of data for the specified columns and gives rank for that partition.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT E.ID, E.firstname, E.lastname, E.country, T.rank FROM [SampleDB].[dbo].[Employee] E INNER JOIN ( SELECT *, RANK() OVER(PARTITION BY firstname, lastname, country ORDER BY id) rank FROM [SampleDB].[dbo].[Employee] ) T ON E.ID = t.ID; |
![]()
In the screenshot, you can note that we need to remove the row having a Rank greater than one. Let’s remove those rows using the following query.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DELETE E FROM [SampleDB].[dbo].[Employee] E INNER JOIN ( SELECT *, RANK() OVER(PARTITION BY firstname, lastname, country ORDER BY id) rank FROM [SampleDB].[dbo].[Employee] ) T ON E.ID = t.ID WHERE rank > 1; |
Use SSIS package to SQL delete duplicate rows
SQL Server integration service provides various transformation, operators that help both administrators and developers in reducing manual effort and optimize the tasks. SSIS package can remove the duplicate rows from a SQL table as well.
Use Sort Operator in an SSIS package for removing duplicating rows
We can use a Sort operator to sort the values in a SQL table. You might ask how data sorting can remove duplicate rows?

Let’s create the SSIS package to show this task.
- In SQL Server Data Tools, create a new Integration package. In the new package, add an OLE DB source connection
-
Open OLE DB source editor and configuration the source connection and select the destination table

-
Click on Preview data and you can see we still have duplicate data in the source table
-
Add a Sort operator from the SSIS toolbox for SQL delete operation and join it with the source data



For the configuration of the Sort operator, double click on it and select the columns that contain duplicate values. In our case, duplicate value is in [FirstName], [LastName], [Country] columns.
We can also use the ascending or descending sorting types for the columns. The default sort method is ascending. In the sort order, we can choose the column sort order. Sort order 1 shows the column which will be sorted first.

On the bottom left side, notice a checkbox Remove rows with duplicate sort values.
It will do the task of removing duplicate rows for us from the source data. Let’s put a tick in this checkbox and click ok. It performs the SQL delete activity in the SSIS package.

Once we click OK, it returns to the data flow tab, and we can see the following SSIS package.

We can add SQL Server destinations to store the data after removing duplicate rows. We only want to check that sort operator is doing the task for us or not.
Add a SQL Multicast Transformation from the SSIS toolbox as shown below.

To view the distinct data, right-click on the connector between Sort and Multicast. Click on Enable Data Viewer.

The overall SSIS package looks like below.

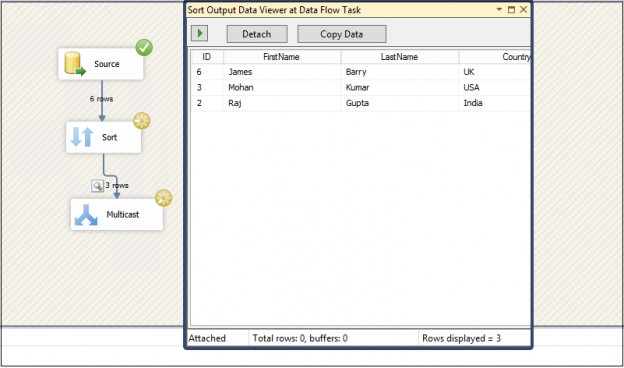
Execute the package to perform SQL delete operation. It opens the Sort output data viewer at the Data flow task. In this data viewer, you can see distinct data after removing the duplicate values.

Close this and the SSIS package shows successfully executed.

Conclusion
In this article, we explored the process of SQL delete duplicate rows using various ways such as T-SQL, CTE, and SSIS package. You can use the method in which you feel comfortable. However, I would suggest not to implement these procedures and package on the production data directly. You should test in a lower environment.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023