
If you’ve already worked with databases, then you could hardly miss the term – Primary Key (PK). And if you’re reading this series and use it to learn about databases, well, this article should give you a good overview of what the PK really is. Still, if you’re a database expert, maybe you’ll find something new or just refresh your knowledge. So, sit back, relax, and let’s dive into PKs.
What is a Primary Key (PK)?
We’re literally surrounded by PKs in the database world. But we mostly take them for granted. Before examples let’s go with a simplified definition of a PK:
“Primary key is a value which is unique for every record in the table.”
And a rule – “Each table in the database should have a PK defined.”

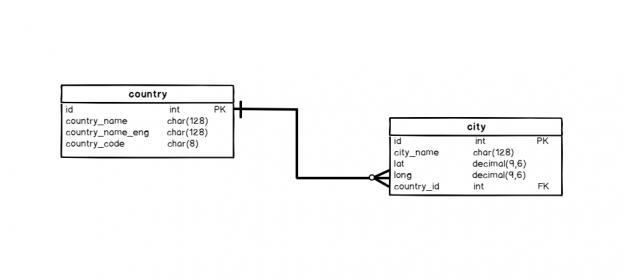
Our database structure
We can expect that in our database we’ll almost always have 1 table for 1 entity from the real world. For example, we’ll have 1 table for countries, 1 for cities, 1 for employees, 1 for calls, etc.
Now, we’re ready to go with examples of primary keys from real life:
- Each country in the world has a unique name, and code (ISO, ICAO, IOC, E. 164 or any other). Both are PKs in real-life (and could also be PKs or alternate keys/unique values in the database)
- Each employee has a unique personal number, company code, etc.
- Each call has the unique combination of who called whom and at which moment. (Please notice that we need all 3 of these – only 2 wouldn’t be enough. E.g. a call center agent could call the same customer many times)
We’ll conclude this part with a more descriptive definition.
“Primary key is a value, or a combination of few values from the table, uniquely defining each record in this table. If we know this value/combination, we can easily find the related record and access all remaining values from that record.”
For instance, if you know the name of the country, you’ll easily find the row with that name and have access to remaining values related to that country – population, statistical data, etc.
What is the purpose of the Primary Key (PK)?
Without PKs, databases wouldn’t work as they work now, or to be precise, wouldn’t function at all.
Let’s take a look at what is in our database. To expand the “tree” click on the “+” sign next to “Databases”, database name (“our_first_database”), and table names (“dbo.city” and “dbo.country”) and “Keys”:

You can easily notice that both tables have PKs (“city_pk”, “country_pk”) and that the “dbo.country” table has alternate keys / unique values ( “country_ak_1”, “country_ak_2”, “country_ak_3”). The key “city_country” is the foreign key and we’ll discuss this later. In order to clarify where all of this came from, let’s remind ourselves of the commands used to create these two tables:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
-- Table: city CREATE TABLE city ( id int NOT NULL IDENTITY(1, 1), city_name char(128) NOT NULL, lat decimal(9,6) NOT NULL, long decimal(9,6) NOT NULL, country_id int NOT NULL, CONSTRAINT city_pk PRIMARY KEY (id) ); -- Table: country CREATE TABLE country ( id int NOT NULL IDENTITY(1, 1), country_name char(128) NOT NULL, country_name_eng char(128) NOT NULL, country_code char(8) NOT NULL, CONSTRAINT country_ak_1 UNIQUE (country_name), CONSTRAINT country_ak_2 UNIQUE (country_name_eng), CONSTRAINT country_ak_3 UNIQUE (country_code), CONSTRAINT country_pk PRIMARY KEY (id) ); |
We’re using databases to store (usually) large amounts of data. In the previous article, we’ve inserted rows in our tables. That is cool, but there’s no point in adding rows if we can’t do anything with them. If we want to do that, we need a way how to recognize each separate row using known value(s). I would separate these values into two groups:
Values we use in the real world. Knowing these values, we can find 1 or more records we need from our database. In the case of the country table, if we know the name of the country, we can easily find a record related to that country in our table and that way access all other values from the same record. If we type the exact name of the country, we’ll use the unique value and our result will be exactly 1 row

As you can see, this is a pretty elegant way to access the data we need. This approach is used when we type search parameters on the front-end form and then pass that value to the SQL query
Values without any meaning in the real world (usually primary keys). It works in the same manner as the previous case, but we’ll use the numerical value from the id column to access a certain country
I guess you see the problem with this approach. Since PKs were generated by the system, we can’t know which id value shall be assigned to which country – they will be assigned in the same order countries were inserted in the table, and this is pretty much “random” order


Still, there is some magic in the second approach because in some cases, the system knows what is the PK value. So, the purpose of the PK is to use it when we’re accessing data and when we (or system) know that value. We’ll explain how the system knows this value in the next article while describing foreign keys.
Primary key VS. UNIQUE (alternate keys)
When I’m designing a database, I always stick to a few rules regarding PKs and unique values. This is the best I’ve learned (so far) and besides technical reasons, it’s also worth mentioning that using this approach you’ll stay consistent throughout the whole database model. So, my rules are:
- Each table in the database should have the PK defined. This will not only improve the overall database performance but is also essential in order that data are related and consistent
- In each table, I’ll add the column named id. It shall be used as a PK column, the type is unsigned integer, with IDENTITY set to (1,1). This way, the DBMS will automatically generate PK values as we add rows. Using integers as PKs also significantly improves the performance (index is created over that attribute automatically! – indexes shall be covered in a separate article)
- All attributes, besides PKs, which contain unique values, should be defined as
UNIQUE (alternate keys). This property could be defined on a single attribute, or on the combination of few attributes. This will prevent inserting unwanted duplicated values
- E.g. if we don’t have a UNIQUE defined on a country_name and we insert country with the same name twice, we’ll have 2 records with different ids with the same country_name. The DBMS would treat these as 2 different countries. Having the alternate key/UNIQUE defined prevents this from happening. Let’s take a look at an example. We already have the country with the name “Deutschland” in our database

Since we’ve defined the UNIQUE rules on 3 columns, all 3 of them will prevent this Insert statement and this is the desired behavior. We’ve defined rules and the system takes care of whether the data we want to insert follow these rules or not.
Conclusion
Understanding what primary key is and when it’s used is the backbone of the database theory. The next thing is understanding the concept of a foreign key and how foreign keys are used to relate data. We’ll cover this in the upcoming article. With these two in your pocket, you have all that’s needed to start creating databases and to expend your knowledge along the way. There is a lot more that has to be learned in order to become a database professional, but you’ve just made your first steps towards that direction.
Table of contents

His past and present engagements vary from database design and coding to teaching, consulting, and writing about databases. Also not to forget, BI, creating algorithms, chess, philately, 2 dogs, 2 cats, 1 wife, 1 baby...
You can find him on LinkedIn
View all posts by Emil Drkusic
- Learn SQL: How to prevent SQL Injection attacks - May 17, 2021
- Learn SQL: Dynamic SQL - March 3, 2021
- Learn SQL: SQL Injection - November 2, 2020