

One of the most important things in databases is to understand the types of relations in the databases. That stands for both – a process of designing a database model as well as when you’re analyzing your data. Understanding these relations is somehow natural and not so complex but is still essential in the database theory (and practice).
Data model
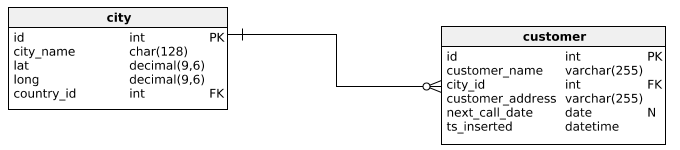
In the previous article, Learn SQL: SQL Scripts, we’ve extended the data model we’ve used so far by adding a few new tables and filling them with the data. “Very nice. I like.”. That is the model in the picture below:

While the model itself has only 6 tables (real-life models could have hundreds of tables), it contains the most common rules we’ll meet in many other models as well. This also stands for types of relations between tables. Without much effort, you can easily notice that each table is connected/related to another table with exactly one line (foreign key). The primary key from one table (e.g. employee.id) is related to the value from another table (e.g. call.employee_id). We’ll use this relation when we need data from both these tables, mostly when we’re writing select queries. The question remains on how to relate two tables. Even between two lines (relations), we could have some minor differences. We’ll discuss that now.
Types of relations
There are 3 different types of relations in the database:
- one-to-one
- one-to-many, and
- many-to-many
Although they are different, they are represented in (almost) the same manner in the databases and that is the line between the two tables. So, what’s different? We’ll explain each of these relations types separately and comment on what is their actual purpose.
One-to-many relation
The first of our 3 types of relations, we’ll start with is one-to-many. The reason for that is that it’s the most commonly used and the remaining two are “subtypes” of this one. Let’s start with a real-life problem.
Example
Imagine that we want to store a list of all our customers in the database. For each customer, we also want to store the city where this customer is located, and we know that the customer will be in exactly one city.
This the typical example of one-to-many relation and this is how we solved it in our model:
We simply established a relation from the city.id to customer.city_id. And this works, because the customer can be only in one city and the city could have many different customers located in it.
When you want to determine the nature of the relation you need to establish between two tables just do this. In our example – For one city, we could have many different customers located in it. And the other way around – For one customer, we can have only one city it’s located in.
So, how to choose between these 3 different types of relations? If you said the word “many” only once, then this is one-to-many relation. If you would use the word “many” two times, the relation would be many-to-many. And if you wouldn’t use it at all, then it would be one-to-one.
- Tip: One-to-many relation is resolved in such a manner that you add an attribute to the table that “is related to” word “many” and establish the relationship between this attribute and id of the original table.
In our case, we’ve added city_id to the customer table and related it to city.id attribute.
Now, let’s write 2 simple SQL SELECT statements and check if this is really true:
|
1 2 3 4 5 |
SELECT * FROM city; SELECT * FROM customer; |
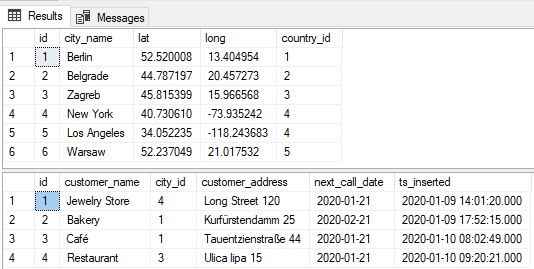
We can easily notice few things:
- Not all cites were used (only these with ids 1, 3 and 4 were)
- Each customer had exactly one city it belongs to (customer.city_id)
Now, we’ll write 3 more queries and join these two tables. Queries are:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT * FROM customer INNER JOIN city ON customer.city_id = city.id; SELECT * FROM customer LEFT JOIN city ON customer.city_id = city.id; SELECT * FROM city LEFT JOIN customer ON customer.city_id = city.id; |
The results returned are in the picture below:
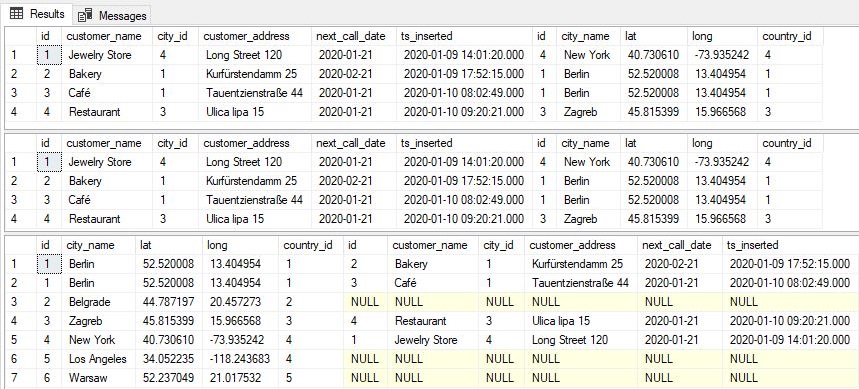
Let’s shortly comment on these results.
The first query (using INNER JOIN) returned only rows where cities and customers had a pair. Since we had 4 rows for customers and all 4 had related city defined, the final result also has 4 rows.
The second query (customer LEFT JOIN city) returned the same result as the first one. That happened because all customers had related city defined. In case some customers wouldn’t have city_id defined (NULL), these customers would be included in this result too.
The last query (city LEFT JOIN customer) returns more rows than the previous two queries. It returns all 4 rows they’ve returned, but also returns 3 more rows for cities where we have no customers. And that’s completely ok because if we wrote query this way, we obviously wanted to point to that fact.
Many-to-many relation
The second out of three types of relations is a many-to-many type. This type is used when both tables could have multiple rows on the other side. Let’s see an example.
Example
We need to store calls between employees and customers.
One employee, during the time, could call many customers. Also, one customer, during the time, could receive calls from many employees.
Notice that we’ve mentioned the word “many” two times. This is the signal we need to resolve this using many-to-many relation (out of 3 types of relations we have on disposal). To solve it we’ll:
- Add a table between tables employee and customer
- Add foreign keys (employee_id & customer_id) to that new table (call)
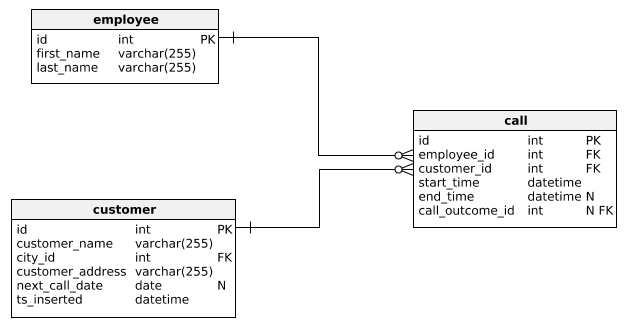
Now, when we look from the employee perspective, one employee could make many (multiple) calls. On the other hand, one customer could be related to many (multiple) calls. Therefore, many-to-many relation is implemented with adding a new table and one-to-many relations from both sides.
Let’s peek into the contents of these three tables now. We’ll use simple queries:
|
1 2 3 4 5 6 7 8 |
SELECT * FROM employee; SELECT * FROM call; SELECT * FROM customer; |
The result is in the picture below:
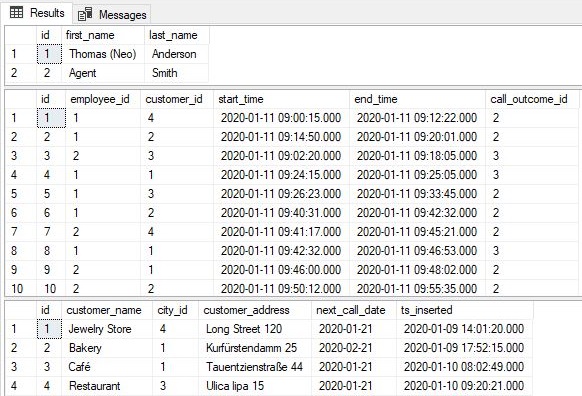
You can easily notice that the table call has attributes employee_id related to the employee.id and customer_id related to the customer.id. Since they are foreign keys, they hold only values from the set defined in the referenced tables (employee & customer).
Actually, we have 1 more foreign key here and that is the call.call_outcome_id. The relation between tables call and call_outcome is one-to-many. This means that the table call actually relates three tables – customer, employee, and call_outcome.
The attribute call.call_outcome_id could contain NULL value (e.g. when the call starts, we still don’t know the outcome and it shall be defined later). That is the reason why, on the relation line, close to the table call_outcome, you can see a little circle (representing “zero”). Other one-to-many relations have a vertical line (representing “one”).
One-to-one relation
Compared to previously mentioned types of relations, this one is really rarely used. Let’s go with an example.
Example
In the database, we want to store employees, but also their valid identity cards. We’re not interested in storing any other types of documents or identity cards that were previously valid, so we need exactly 1 (or none) identity card for 1 employee.
Let’s check this truly is a one-to-one relation. We’ve been given these rules: One employee could have only one valid identity card in our system. One identity card could belong to only one employee. We haven’t used the word “many”, so this can’t be any type of relation including the word “many”.
We could do two things here:
- Store identity card details in the employee table. This is how it’s usually done and the reason for doing it differently (as mentioned below) is some kind of exception
- Store identity card details in a separate table and relate these two tables with a foreign key. But that foreign key (identity_card.employee_id), referencing employee.id, should, at the same time, be the primary key of the identity_card table. This way we could have only 1 record per employee
We could decide to go with the second option if we want:
- To keep identity card data separately because we want to keep the model clear and follow the same logic in the whole model (each entity from the real-world has its’ own table in the data model)
- Maybe not all employees will have identity cards, so we’ll spare some storage space this way
Please notice that one-to-one was also implemented in the same manner as one-to-many (1 relation) but with the additional condition (the foreign key is also the primary key).
Conclusion
Today, we’ve described 3 types of relations used in the databases. While this is more of a theory, it’s necessary for understanding how everything works. In upcoming articles, especially those focused on how to write (complex) SQL queries, I’ll also, from time to time, mention these 3 types.
Table of contents

His past and present engagements vary from database design and coding to teaching, consulting, and writing about databases. Also not to forget, BI, creating algorithms, chess, philately, 2 dogs, 2 cats, 1 wife, 1 baby...
You can find him on LinkedIn
View all posts by Emil Drkusic
- Learn SQL: How to prevent SQL Injection attacks - May 17, 2021
- Learn SQL: Dynamic SQL - March 3, 2021
- Learn SQL: SQL Injection - November 2, 2020