
Introduction
In Part 1 of this article, we built a case for the benefits of documenting our schema via the use of a stored procedure, as well as the ways this information can be used for DML operations on a relational database. Below, we will continue where we left off by speeding up our SQL queries and then putting everything together so that we can demo a usable script that will hopefully make your life easier!
Optimization
One additional step that has not been addressed yet, but should be, is optimization. As we collect row counts, we will undoubtedly find many relationships with row counts of zero. For the sake of deleting data, these relationships may be removed from our foreign key data set. But wait—there’s more! Any relationship that is a child of a parent with zero rows can also be deleted. This is an immense optimization step as we can slice off large swaths of data very quickly. Even more importantly, each future iteration of our WHILE loop won’t have to touch that newly defined chunk of irrelevant relationship data. In tests I conducted on large test databases, these additional steps reduced runtime by as much as 95%.
The following change to our TSQL from above illustrates this optimization procedure:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
IF @row_count = 0 BEGIN DELETE FKEYS FROM @foreign_keys FKEYS WHERE FKEYS.object_id_hierarchy_rank LIKE @object_id_hierarchy_rank + '%' -- Remove all paths that share the same root as this one. AND (FKEYS.object_id_hierarchy_rank <> @object_id_hierarchy_rank OR FKEYS.foreign_key_id = @foreign_key_id) -- Don't remove paths where there are multiple foreign keys from one table to another. AND FKEYS.referencing_column_name_rank LIKE @referencing_column_name_rank + '%' -- Don't remove paths that have identical table relationships, but that occur through different FK columns. END ELSE BEGIN UPDATE FKEYS SET processed = 1, row_count = @row_count, join_condition_sql = @join_sql FROM @foreign_keys FKEYS WHERE FKEYS.foreign_key_id = @foreign_key_id; END |
By adding in a row count check, we can choose one of two scenarios:
- There are no rows of data to process: delete this foreign key relationship and all that are children of it.
- There are rows of data for this relationship, update @foreign_keys with the necessary information.
The generation of the INNER JOIN data that is stored in #inner_join_tables is a bit complex, and is written as it is to ensure that we never join into the same relationship twice or incorrectly. We want to the correct path from the current relationship back to the target table through a sequence of unique column relationships. The additional WHERE clauses guard against a handful of important scenarios:
- If a relationship could theoretically loop back through a table we have already referenced, prevent further processing. Otherwise, we would allow infinite loops to occur.
- Do not process the target table in the loop. Handle it separately as it is a special case.
- If multiple relationship paths exist between two tables, ensure that only the current path is traversed. The @has_same_object_id_hierarchy variable checks for identical table paths and allows for extra logic to be included when this happens.
At this point, we can take all of the data gathered above and use it to generate a list of DELETE statements, in order, for the target table and WHERE clause provided in the stored procedure parameters.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
WHILE EXISTS (SELECT * FROM @foreign_keys WHERE processed = 0 AND level > 0 ) BEGIN SELECT @sql_command = ''; SELECT @join_sql = ''; SELECT @old_table_name = ''; SELECT @old_schema_name = ''; SELECT TOP 1 @process_schema_name = referencing_schema_name, @process_table_name = referencing_table_name, @object_id_hierarchy_rank = object_id_hierarchy_rank, @row_count = row_count, @foreign_key_id = foreign_key_id FROM @foreign_keys WHERE processed = 0 AND level > 0 ORDER BY level DESC; SET @sql_command = '-- Maximum rows to be deleted: ' + CAST(@row_count AS VARCHAR(25)) + CHAR(10) + 'DELETE [' + @process_table_name + ']' + CHAR(10) + 'FROM [' + @process_schema_name + '].[' + @process_table_name + ']' + CHAR(10); SELECT @join_sql = FKEYS.join_condition_sql FROM @foreign_keys FKEYS WHERE FKEYS.foreign_key_id = @foreign_key_id SELECT @sql_command = @sql_command + @join_sql; IF @where_clause <> '' BEGIN SELECT @sql_command = @sql_command + 'WHERE (' + @where_clause + ')' + CHAR(10); END -- If rows exist to be deleted, then print those delete statements. PRINT @sql_command + 'GO' + CHAR(10); UPDATE @foreign_keys SET processed = 1 WHERE foreign_key_id = @foreign_key_id END -- Delete data from the root table SET @sql_command = '-- Rows to be deleted: ' + CAST(@base_table_row_count AS VARCHAR(25)) + CHAR(10) + 'DELETE FROM [' + @process_schema_name + '].[' + @table_name + ']'; IF @where_clause <> '' BEGIN SELECT @sql_command = @sql_command + CHAR(10) + 'WHERE ' + @where_clause; END -- Print deletion statement for root table PRINT @sql_command; |
Comments are added into the PRINT statements with the maximum number of rows to be deleted. This is based on join data and may be rendered inaccurate as execution occurs, as a row of data may belong to several relationships, and once deleted will not be available for deletion as part of any others. These estimates are useful, though, in gauging the volume of data that each relationship represents.
The bulk of the work in our stored procedure is done when the counts are calculated. The deletion section is iterating through a similar loop and printing out the appropriate delete TSQL, in order, for each relationship that was previously defined and enumerated.
There is one final task to manage, and that is self-referencing relationships. If a table has a parent-child relationship with itself, we explicitly avoided it above. How to properly handle these relationships, should they exist, is up to you. Whether we cascade DELETE statements through the rest of our work or simply set the foreign key column to NULL would be based on the appropriate business logic. In the following TSQL, we set any of these relationships to NULL that happen to directly relate to the target table. We could also tie it into our big loop and traverse all relationships previously defined, but I have left this edge case out as it is not too common:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
WHILE EXISTS (SELECT * FROM @self_referencing_keys SRKEYS WHERE SRKEYS.processed = 0) BEGIN -- Get next self-referencing relationship to process SELECT TOP 1 @relationship_id = SRKEY.self_referencing_keys_id FROM @self_referencing_keys SRKEY WHERE processed = 0; -- Get row counts for the update statement SELECT @count_sql_command = 'SELECT COUNT(*)' + CHAR(10) + 'FROM [' + SRKEY.referencing_schema_name + '].[' + SRKEY.referencing_table_name + ']' + CHAR(10) + 'WHERE [' + SRKEY.referencing_column_name + '] IN' + CHAR(10) + ' (SELECT ' + SRKEY.primary_key_column_name + ' FROM [' + SRKEY.primary_key_schema_name + '].[' + SRKEY.primary_key_table_name + '])' + CHAR(10) FROM @self_referencing_keys SRKEY WHERE SRKEY.self_referencing_keys_id = @relationship_id; INSERT INTO @row_counts (row_count) EXEC (@count_sql_command) SELECT @row_count = row_count FROM @row_counts; IF @row_count > 0 BEGIN SELECT @sql_command = '-- Rows to be updated: ' + CAST(@row_count AS VARCHAR(MAX)) + CHAR(10) + 'UPDATE [' + SRKEY.referencing_schema_name + '].[' + SRKEY.referencing_table_name + ']' + CHAR(10) + ' SET ' + SRKEY.referencing_column_name + ' = NULL' + CHAR(10) + 'FROM [' + SRKEY.referencing_schema_name + '].[' + SRKEY.referencing_table_name + ']' + CHAR(10) + 'WHERE [' + SRKEY.referencing_column_name + '] IN' + CHAR(10) + ' (SELECT ' + SRKEY.primary_key_column_name + ' FROM [' + SRKEY.primary_key_schema_name + '].[' + SRKEY.primary_key_table_name + ')' + CHAR(10) FROM @self_referencing_keys SRKEY WHERE SRKEY.self_referencing_keys_id = @relationship_id; -- Print self-referencing data modification statements PRINT @sql_command; END ELSE BEGIN -- Remove any rows for which we have no data. DELETE SRKEY FROM @self_referencing_keys SRKEY WHERE SRKEY.self_referencing_keys_id = @relationship_id; END UPDATE @self_referencing_keys SET processed = 1, row_count = @row_count WHERE self_referencing_keys_id = @relationship_id; DELETE FROM @row_counts; END |
This logic is simplified, but at least identifies relationships where data exists, and provides some sample TSQL that could be used to clear them out in their entirety, if that is the best approach for your data.
Putting Everything Together
With all of our objectives completed, we can now piece together our stored procedure in its final form. The relationship data is selected back to SSMS at the end as a reference, so you can easily view & save this data as needed:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 |
CREATE PROCEDURE dbo.atp_schema_mapping @schema_name SYSNAME, @table_name SYSNAME, @where_clause VARCHAR(MAX) = '' AS BEGIN SET NOCOUNT ON; DECLARE @sql_command VARCHAR(MAX) = ''; -- Used for many dynamic SQL statements SET @where_clause = ISNULL(LTRIM(RTRIM(@where_clause)), ''); -- Clean up WHERE clause, to simplify future SQL DECLARE @relationship_id INT; -- Will temporarily hold row ID for use in iterating through relationships DECLARE @count_sql_command VARCHAR(MAX) = ''; -- Used for dynamic SQL for count calculations DECLARE @row_count INT; -- Temporary holding place for relationship row count DECLARE @row_counts TABLE -- Temporary table to dump dynamic SQL output into (row_count INT); DECLARE @base_table_row_count INT; -- This will hold the row count of the base entity. SELECT @sql_command = 'SELECT COUNT(*) FROM [' + @schema_name + '].[' + @table_name + ']' + -- Build COUNT statement CASE WHEN @where_clause <> '' -- Add WHERE clause, if provided THEN CHAR(10) + 'WHERE ' + @where_clause ELSE '' END; INSERT INTO @row_counts (row_count) EXEC (@sql_command); SELECT @base_table_row_count = row_count -- Extract count from temporary location. FROM @row_counts; -- If there are no matching rows to the input provided, exit immediately with an error message. IF @base_table_row_count = 0 BEGIN PRINT '-- There are no rows to process based on the input table and where clause. Execution aborted.'; RETURN; END DELETE FROM @row_counts; -- This table will hold all foreign key relationships DECLARE @foreign_keys TABLE ( foreign_key_id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED, referencing_object_id INT NULL, referencing_schema_name SYSNAME NULL, referencing_table_name SYSNAME NULL, referencing_column_name SYSNAME NULL, primary_key_object_id INT NULL, primary_key_schema_name SYSNAME NULL, primary_key_table_name SYSNAME NULL, primary_key_column_name SYSNAME NULL, level INT NULL, object_id_hierarchy_rank VARCHAR(MAX) NULL, referencing_column_name_rank VARCHAR(MAX) NULL, row_count INT DEFAULT 0 NOT NULL, processed BIT DEFAULT 0 NOT NULL, join_condition_sql VARCHAR(MAX) DEFAULT ''); -- Save this after we complete the count calculations so we don't have to do it again later. -- Table to exclusively store self-referencing foreign key data DECLARE @self_referencing_keys TABLE ( self_referencing_keys_id INT NOT NULL IDENTITY(1,1), referencing_primary_key_name SYSNAME NULL, referencing_schema_name SYSNAME NULL, referencing_table_name SYSNAME NULL, referencing_column_name SYSNAME NULL, primary_key_schema_name SYSNAME NULL, primary_key_table_name SYSNAME NULL, primary_key_column_name SYSNAME NULL, row_count INT DEFAULT 0 NOT NULL, processed BIT DEFAULT 0 NOT NULL); -- Insert all foreign key relational data into the table variable using a recursive CTE over system tables. WITH fkey (referencing_object_id, referencing_schema_name, referencing_table_name, referencing_column_name, primary_key_object_id, primary_key_schema_name, primary_key_table_name, primary_key_column_name, level, object_id_hierarchy_rank, referencing_column_name_rank) AS ( SELECT parent_table.object_id AS referencing_object_id, parent_schema.name AS referencing_schema_name, parent_table.name AS referencing_table_name, CONVERT(SYSNAME, NULL) AS referencing_column_name, CONVERT(INT, NULL) AS referenced_table_object_id, CONVERT(SYSNAME, NULL) AS referenced_schema_name, CONVERT(SYSNAME, NULL) AS referenced_table_name, CONVERT(SYSNAME, NULL) AS referenced_key_column_name, 0 AS level, CONVERT(VARCHAR(MAX), parent_table.object_id) AS object_id_hierarchy_rank, CAST('' AS VARCHAR(MAX)) AS referencing_column_name_rank FROM sys.objects parent_table INNER JOIN sys.schemas parent_schema ON parent_schema.schema_id = parent_table.schema_id WHERE parent_table.name = @table_name AND parent_schema.name = @schema_name UNION ALL SELECT child_object.object_id AS referencing_object_id, child_schema.name AS referencing_schema_name, child_object.name AS referencing_table_name, referencing_column.name AS referencing_column_name, referenced_table.object_id AS referenced_table_object_id, referenced_schema.name AS referenced_schema_name, referenced_table.name AS referenced_table_name, referenced_key_column.name AS referenced_key_column_name, f.level + 1 AS level, f.object_id_hierarchy_rank + '-' + CONVERT(VARCHAR(MAX), child_object.object_id) AS object_id_hierarchy_rank, f.referencing_column_name_rank + '-' + CAST(referencing_column.name AS VARCHAR(MAX)) AS referencing_column_name_rank FROM sys.foreign_key_columns sfc INNER JOIN sys.objects child_object ON sfc.parent_object_id = child_object.object_id INNER JOIN sys.schemas child_schema ON child_schema.schema_id = child_object.schema_id INNER JOIN sys.columns referencing_column ON referencing_column.object_id = child_object.object_id AND referencing_column.column_id = sfc.parent_column_id INNER JOIN sys.objects referenced_table ON sfc.referenced_object_id = referenced_table.object_id INNER JOIN sys.schemas referenced_schema ON referenced_schema.schema_id = referenced_table.schema_id INNER JOIN sys.columns AS referenced_key_column ON referenced_key_column.object_id = referenced_table.object_id AND referenced_key_column.column_id = sfc.referenced_column_id INNER JOIN fkey f ON f.referencing_object_id = sfc.referenced_object_id WHERE ISNULL(f.primary_key_object_id, 0) <> f.referencing_object_id -- Exclude self-referencing keys AND f.object_id_hierarchy_rank NOT LIKE '%' + CAST(child_object.object_id AS VARCHAR(MAX)) + '%' ) INSERT INTO @foreign_keys ( referencing_object_id, referencing_schema_name, referencing_table_name, referencing_column_name, primary_key_object_id, primary_key_schema_name, primary_key_table_name, primary_key_column_name, level, object_id_hierarchy_rank, referencing_column_name_rank) SELECT DISTINCT referencing_object_id, referencing_schema_name, referencing_table_name, referencing_column_name, primary_key_object_id, primary_key_schema_name, primary_key_table_name, primary_key_column_name, level, object_id_hierarchy_rank, referencing_column_name_rank FROM fkey; UPDATE FKEYS SET referencing_column_name_rank = SUBSTRING(referencing_column_name_rank, 2, LEN(referencing_column_name_rank)) -- Remove extra leading dash leftover from the top-level column, which has no referencing column relationship. FROM @foreign_keys FKEYS -- Insert all data for self-referencing keys into a separate table variable. INSERT INTO @self_referencing_keys ( referencing_primary_key_name, referencing_schema_name, referencing_table_name, referencing_column_name, primary_key_schema_name, primary_key_table_name, primary_key_column_name) SELECT (SELECT COL_NAME(SIC.OBJECT_ID, SIC.column_id) FROM sys.indexes SI INNER JOIN sys.index_columns SIC ON SIC.index_id = SI.index_id AND SIC.object_id = SI.object_id WHERE SI.is_primary_key = 1 AND OBJECT_NAME(SIC.OBJECT_ID) = child_object.name) AS referencing_primary_key_name, child_schema.name AS referencing_schema_name, child_object.name AS referencing_table_name, referencing_column.name AS referencing_column_name, referenced_schema.name AS primary_key_schema_name, referenced_table.name AS primary_key_table_name, referenced_key_column.name AS primary_key_column_name FROM sys.foreign_key_columns sfc INNER JOIN sys.objects child_object ON sfc.parent_object_id = child_object.object_id INNER JOIN sys.schemas child_schema ON child_schema.schema_id = child_object.schema_id INNER JOIN sys.columns referencing_column ON referencing_column.object_id = child_object.object_id AND referencing_column.column_id = sfc.parent_column_id INNER JOIN sys.objects referenced_table ON sfc.referenced_object_id = referenced_table.object_id INNER JOIN sys.schemas referenced_schema ON referenced_schema.schema_id = referenced_table.schema_id INNER JOIN sys.columns AS referenced_key_column ON referenced_key_column.object_id = referenced_table.object_id AND referenced_key_column.column_id = sfc.referenced_column_id WHERE child_object.name = referenced_table.name AND child_object.name IN -- Only consider self-referencing relationships for tables somehow already referenced above, otherwise they are irrelevant. (SELECT referencing_table_name FROM @foreign_keys); ------------------------------------------------------------------------------------------------------------------------------- -- Generate the Delete script for self-referencing data ------------------------------------------------------------------------------------------------------------------------------- WHILE EXISTS (SELECT * FROM @self_referencing_keys SRKEYS WHERE SRKEYS.processed = 0) BEGIN -- Get next self-referencing relationship to process SELECT TOP 1 @relationship_id = SRKEY.self_referencing_keys_id FROM @self_referencing_keys SRKEY WHERE processed = 0; -- Get row counts for the update statement SELECT @count_sql_command = 'SELECT COUNT(*)' + CHAR(10) + 'FROM [' + SRKEY.referencing_schema_name + '].[' + SRKEY.referencing_table_name + ']' + CHAR(10) + 'WHERE [' + SRKEY.referencing_column_name + '] IN' + CHAR(10) + ' (SELECT ' + SRKEY.primary_key_column_name + ' FROM [' + SRKEY.primary_key_schema_name + '].[' + SRKEY.primary_key_table_name + '])' + CHAR(10) FROM @self_referencing_keys SRKEY WHERE SRKEY.self_referencing_keys_id = @relationship_id; INSERT INTO @row_counts (row_count) EXEC (@count_sql_command) SELECT @row_count = row_count FROM @row_counts; IF @row_count > 0 BEGIN SELECT @sql_command = '-- Rows to be updated: ' + CAST(@row_count AS VARCHAR(MAX)) + CHAR(10) + 'UPDATE [' + SRKEY.referencing_schema_name + '].[' + SRKEY.referencing_table_name + ']' + CHAR(10) + ' SET ' + SRKEY.referencing_column_name + ' = NULL' + CHAR(10) + 'FROM [' + SRKEY.referencing_schema_name + '].[' + SRKEY.referencing_table_name + ']' + CHAR(10) + 'WHERE [' + SRKEY.referencing_column_name + '] IN' + CHAR(10) + ' (SELECT ' + SRKEY.primary_key_column_name + ' FROM [' + SRKEY.primary_key_schema_name + '].[' + SRKEY.primary_key_table_name + ')' + CHAR(10) FROM @self_referencing_keys SRKEY WHERE SRKEY.self_referencing_keys_id = @relationship_id; -- Print self-referencing data modification statements PRINT @sql_command; END ELSE BEGIN -- Remove any rows for which we have no data. DELETE SRKEY FROM @self_referencing_keys SRKEY WHERE SRKEY.self_referencing_keys_id = @relationship_id; END UPDATE @self_referencing_keys SET processed = 1, row_count = @row_count WHERE self_referencing_keys_id = @relationship_id; DELETE FROM @row_counts; END ------------------------------------------------------------------------------------------------------------------------------- -- Generate row counts for non-self-referencing data and delete any entries that have a zero row count ------------------------------------------------------------------------------------------------------------------------------- DECLARE @object_id_hierarchy_sql VARCHAR(MAX); DECLARE @process_schema_name SYSNAME = ''; DECLARE @process_table_name SYSNAME = ''; DECLARE @referencing_column_name SYSNAME = ''; DECLARE @join_sql VARCHAR(MAX) = ''; DECLARE @object_id_hierarchy_rank VARCHAR(MAX) = ''; DECLARE @referencing_column_name_rank VARCHAR(MAX) = ''; DECLARE @old_schema_name SYSNAME = ''; DECLARE @old_table_name SYSNAME = ''; DECLARE @foreign_key_id INT; DECLARE @has_same_object_id_hierarchy BIT; -- Will be used if this foreign key happens to share a hierarchy with other keys DECLARE @level INT; WHILE EXISTS (SELECT * FROM @foreign_keys WHERE processed = 0 AND level > 0 ) BEGIN SELECT @count_sql_command = ''; SELECT @join_sql = ''; SELECT @old_schema_name = ''; SELECT @old_table_name = ''; CREATE TABLE #inner_join_tables ( id INT NOT NULL IDENTITY(1,1), object_id INT); SELECT TOP 1 @process_schema_name = FKEYS.referencing_schema_name, @process_table_name = FKEYS.referencing_table_name, @object_id_hierarchy_rank = FKEYS.object_id_hierarchy_rank, @referencing_column_name_rank = FKEYS.referencing_column_name_rank, @foreign_key_id = FKEYS.foreign_key_id, @referencing_column_name = FKEYS.referencing_column_name, @has_same_object_id_hierarchy = CASE WHEN (SELECT COUNT(*) FROM @foreign_keys FKEYS2 WHERE FKEYS2.object_id_hierarchy_rank = FKEYS.object_id_hierarchy_rank) > 1 THEN 1 ELSE 0 END, @level = FKEYS.level FROM @foreign_keys FKEYS WHERE FKEYS.processed = 0 AND FKEYS.level > 0 ORDER BY FKEYS.level ASC; SELECT @object_id_hierarchy_sql ='SELECT ' + REPLACE (@object_id_hierarchy_rank, '-', ' UNION ALL SELECT '); INSERT INTO #inner_join_tables EXEC(@object_id_hierarchy_sql); SET @count_sql_command = 'SELECT COUNT(*) FROM [' + @process_schema_name + '].[' + @process_table_name + ']' + CHAR(10); SELECT @join_sql = @join_sql + CASE WHEN (@old_table_name <> FKEYS.primary_key_table_name OR @old_schema_name <> FKEYS.primary_key_schema_name) THEN 'INNER JOIN [' + FKEYS.primary_key_schema_name + '].[' + FKEYS.primary_key_table_name + '] ' + CHAR(10) + ' ON ' + ' [' + FKEYS.primary_key_schema_name + '].[' + FKEYS.primary_key_table_name + '].[' + FKEYS.primary_key_column_name + '] = [' + FKEYS.referencing_schema_name + '].[' + FKEYS.referencing_table_name + '].[' + FKEYS.referencing_column_name + ']' + CHAR(10) ELSE '' END , @old_table_name = CASE WHEN (@old_table_name <> FKEYS.primary_key_table_name OR @old_schema_name <> FKEYS.primary_key_schema_name) THEN FKEYS.primary_key_table_name ELSE @old_table_name END , @old_schema_name = CASE WHEN (@old_table_name <> FKEYS.primary_key_table_name OR @old_schema_name <> FKEYS.primary_key_schema_name) THEN FKEYS.primary_key_schema_name ELSE @old_schema_name END FROM @foreign_keys FKEYS INNER JOIN #inner_join_tables join_details ON FKEYS.referencing_object_id = join_details.object_id WHERE CHARINDEX(FKEYS.object_id_hierarchy_rank + '-', @object_id_hierarchy_rank + '-') <> 0 -- Do not allow cyclical joins through the same table we are originating from AND FKEYS.level > 0 AND ((@has_same_object_id_hierarchy = 0) OR (@has_same_object_id_hierarchy = 1 AND FKEYS.referencing_column_name = @referencing_column_name) OR (@has_same_object_id_hierarchy = 1 AND @level > FKEYS.level)) ORDER BY join_details.ID DESC; SELECT @count_sql_command = @count_sql_command + @join_sql; IF @where_clause <> '' BEGIN SELECT @count_sql_command = @count_sql_command + ' WHERE (' + @where_clause + ')'; END INSERT INTO @row_counts (row_count) EXEC (@count_sql_command); SELECT @row_count = row_count FROM @row_counts; IF @row_count = 0 BEGIN DELETE FKEYS FROM @foreign_keys FKEYS WHERE FKEYS.object_id_hierarchy_rank LIKE @object_id_hierarchy_rank + '%' -- Remove all paths that share the same root as this one. AND (FKEYS.object_id_hierarchy_rank <> @object_id_hierarchy_rank OR FKEYS.foreign_key_id = @foreign_key_id) -- Don't remove paths where there are multiple foreign keys from one table to another. AND FKEYS.referencing_column_name_rank LIKE @referencing_column_name_rank + '%' -- Don't remove paths that have identical table relationships, but that occur through different FK columns. END ELSE BEGIN UPDATE FKEYS SET processed = 1, row_count = @row_count, join_condition_sql = @join_sql FROM @foreign_keys FKEYS WHERE FKEYS.foreign_key_id = @foreign_key_id; END DELETE FROM @row_counts; DROP TABLE #inner_join_tables END -- Reset processed flag for all rows UPDATE @foreign_keys SET processed = 0; ------------------------------------------------------------------------------------------------------------------------------- -- Generate the Delete script for non-self-referencing data ------------------------------------------------------------------------------------------------------------------------------- WHILE EXISTS (SELECT * FROM @foreign_keys WHERE processed = 0 AND level > 0 ) BEGIN SELECT @sql_command = ''; SELECT @join_sql = ''; SELECT @old_table_name = ''; SELECT @old_schema_name = ''; SELECT TOP 1 @process_schema_name = referencing_schema_name, @process_table_name = referencing_table_name, @object_id_hierarchy_rank = object_id_hierarchy_rank, @row_count = row_count, @foreign_key_id = foreign_key_id FROM @foreign_keys WHERE processed = 0 AND level > 0 ORDER BY level DESC; SET @sql_command = '-- Maximum rows to be deleted: ' + CAST(@row_count AS VARCHAR(25)) + CHAR(10) + 'DELETE [' + @process_table_name + ']' + CHAR(10) + 'FROM [' + @process_schema_name + '].[' + @process_table_name + ']' + CHAR(10); SELECT @join_sql = FKEYS.join_condition_sql FROM @foreign_keys FKEYS WHERE FKEYS.foreign_key_id = @foreign_key_id SELECT @sql_command = @sql_command + @join_sql; IF @where_clause <> '' BEGIN SELECT @sql_command = @sql_command + 'WHERE (' + @where_clause + ')' + CHAR(10); END -- If rows exist to be deleted, then print those delete statements. PRINT @sql_command + 'GO' + CHAR(10); UPDATE @foreign_keys SET processed = 1 WHERE foreign_key_id = @foreign_key_id END -- Delete data from the root table SET @sql_command = '-- Rows to be deleted: ' + CAST(@base_table_row_count AS VARCHAR(25)) + CHAR(10) + 'DELETE FROM [' + @process_schema_name + '].[' + @table_name + ']'; IF @where_clause <> '' BEGIN SELECT @sql_command = @sql_command + CHAR(10) + 'WHERE ' + @where_clause; END -- Print deletion statement for root table PRINT @sql_command; -- Select remaining data from hierarchical tables & Update SELECT data for the base table to reflect the row count calculated at the start of this script UPDATE @foreign_keys SET row_count = @base_table_row_count, processed = 1 WHERE level = 0; IF (SELECT COUNT(*) FROM @self_referencing_keys) > 0 BEGIN SELECT * FROM @self_referencing_keys; END SELECT * FROM @foreign_keys; END GO |
We can run some test scenarios on Adventureworks:
|
1 2 3 4 5 6 7 |
EXEC dbo.atp_schema_mapping @schema_name = 'Production', @table_name = 'Product', @where_clause = 'Product.Color = ''Silver''' GO |
This will return 14 relationships that stem from Production.Product, up to 2 levels away from that table. The DELETE statements are printed to the text window and are directly tied to each row of relationship output from above.
Another example can be run that shows an additional level of relationship abstraction, and the 15 relationships that exist as part of it:
|
1 2 3 4 5 6 7 |
EXEC dbo.atp_schema_mapping @schema_name = 'Production', @table_name = 'ProductModel', @where_clause = 'ProductModel.Name = ''HL Mountain Frame''' GO |
We can look at one relationship from this example to see what data was output and why:
foreign_key_id: 20 referencing_object_id: 1154103152
referencing_schema_name: Sales
referencing_table_name: SalesOrderDetail
referencing_column_name: SpecialOfferID
primary_key_object_id: 414624520
primary_key_schema_name: Sales
primary_key_table_name: SpecialOfferProduct
primary_key_column_name: SpecialOfferID
level: 3
object_id_hierarchy_rank: 418100530-1973582069-414624520-1154103152
referencing_column_hierarchy_rank: ProductModelID-ProductID-SpecialOfferID
This charts the foreign key relationships Sales. SalesOrderDetail, Sales. SpecialOfferProduct, Production.Product, and Production.ProductModel as is shown in the following ERD:
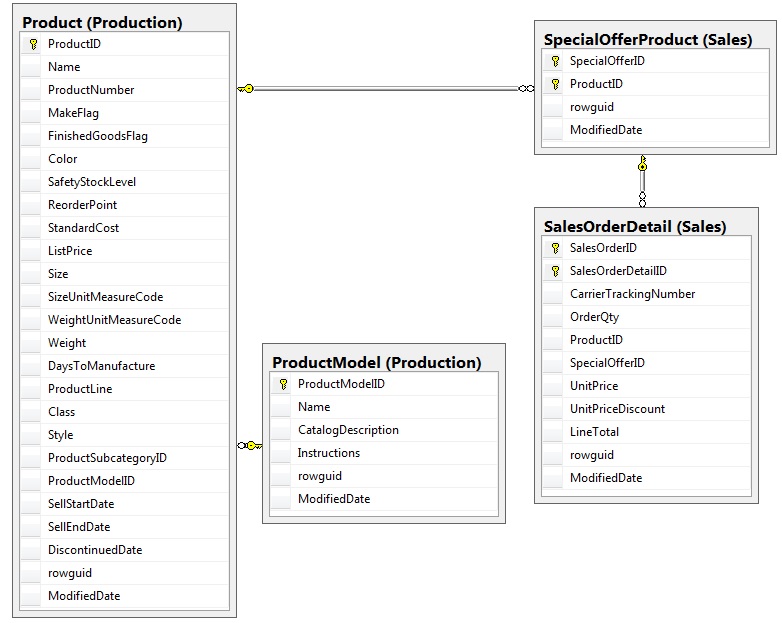
The resulting DELETE statement for this relationship is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DELETE [SalesOrderDetail] FROM [Sales].[SalesOrderDetail] INNER JOIN [Sales].[SpecialOfferProduct] ON [Sales].[SpecialOfferProduct].[SpecialOfferID] = [Sales].[SalesOrderDetail].[SpecialOfferID] INNER JOIN [Production].[Product] ON [Production].[Product].[ProductID] = [Sales].[SpecialOfferProduct].[ProductID] INNER JOIN [Production].[ProductModel] ON [Production].[ProductModel].[ProductModelID] = [Production].[Product].[ProductModelID] WHERE (ProductModel.Name = 'HL Mountain Frame') GO |
Conclusion
The ability to quickly map out a complete relationship hierarchy can be a huge time-saving tool to have at one’s disposal. The stored procedure presented here is intended to be a base research script. You, the user, can customize to your heart’s content, adding additional parameters, print options, or unique logic that is exclusive to your business. Deletion was the target usage, but a similar process could be used in any application where complete hierarchical knowledge of a database (or part of a database) is needed. This stored procedure can be used as-is with no modifications, and will still provide quite a bit of information on your database schema.
If you are working in a relational environment that lacks foreign keys, you can still utilize this approach, but would have to define those relationships in a table, file, or TSQL statement. Once available, the stored procedure could be modified slightly to take that data as an input, format it as the system views would, and continue as though it were the same data.
Leaving off the WHERE clause allows you to get a complete relationship tree if one were to want to touch all data in a target table. If your interest was a database map with no omissions, you could drop the DELETE statement that was added in for efficiency. The resulting stored procedure will take more time to execute, but will provide all possible relationships from a given entity, which could be useful when researching code changes or data integrity.
Regardless of usage, knowledge is power, and the ability to obtain large amounts of schema-dependent information quickly & efficiently can turn complex tasks into trivial bits of work. The ability to customize those processes allows for nearly limitless applications and the ability to conduct research and reconnaissance that would otherwise be extremely labor-intensive, error-prone, or seemingly impossible!

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019