

In this article, I am going to demonstrate in detail the Modular ETL Architecture. ETL is a vast concept which explains the methodology of moving data across various sources to destinations while performing some sort of transformations within it. This is an advanced article that considers that the user has a substantial amount of understanding about how ETL is implemented using different tools like SSIS and the underlying working principle along with how to deploy multiple packages using SSIS. It is extremely important to implement a well-designed ETL architecture for your organization’s workload, otherwise, it might lead to performance degradations along with other challenges. To keep things simple, I will just explain the Modular ETL Architecture in this article which will be followed by a detailed hands-on tutorial in the next article – “Implementing Modular Architecture in ETL using SSIS”.
What is Modular ETL Architecture
The key components of an ETL system can be categorized into an extract, transformation, and load. Although there can be other subparts within the ETL system, for this article, we will consider these three. While designing the ETL packages, it is often a challenge for the BI Engineer as to how to build the overall architecture of the project, so that all the modules in a pipeline can interact with each other and with minimum dependencies. This translates to a system where all the components like extract, transform, and load can be decoupled with each other and can be executed independently.
An analogy to Modular ETL Architecture in the Software Development world
To describe in general words, most of the software developers in the modern world are aware of microservices-based system architecture, wherein the product is designed such that various modules of the same application are isolated and works independently without being in touch with each other. For illustration please refer to the figure below:

Figure 1 – Simple Microservices Architecture
In the above figure, you can see that there are four independent services like Product Center, Order Center, System Center and Payment Center of a simple web application which also have their own databases. All these individual services are connected to the UI through which the end-user can view the products using the Product Center service, order products which leverage the Order Center, and the payments are processed using the Payment Center service. All these services are in fact managed by the System center which acts as a control center across all the other microservices.
In a similar fashion, we can also design our ETL system where all the components like extract, transform and load of various modules will function independently of one another.
For example, let us consider a simple warehouse in which we must load data for two modules like Orders and Sales. The data is generated across a variety of sources like databases, flat files, and API. We need to integrate data across all these data sources and load it into a data warehouse from where the reporting team and takes it all.

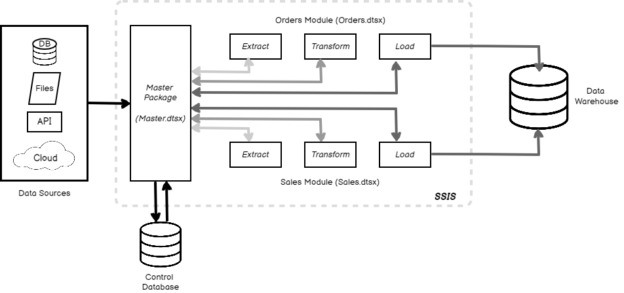
Figure 2 – Modular ETL Architecture
This can be implemented by creating a master package in SSIS which will mimic the System Center from the first illustration and control the flow of all the other individual modules and components within the data pipeline. For your reference, I have created a simple illustration in the above figure, where you can see that we have our multiple data sources listed on the left-hand side. The master package (Master.dtsx) connects to the data sources and executes the individual packages one by one. It also has its own database, the ControlDB which is used to store log information about when to execute which modules. You can also see that there are two packages namely Orders.dtsx and Sales.dtsx which are specifically built to handle data movement for the respective modules. These individual packages can be considered as child packages and are controlled by the master package.
Also, the child packages are further designed in a modular fashion that each of the components within the package like extract, transform and load can also be independently executed by the master package without having to run the entire child package again. This is a benefit when a part of the package fails, the master package can simply re-execute the failed component. For example, let us consider that the Sales.dtsx is being executed by the master package, however, due to some issues the extract component of the package is executed successfully but the transform and load components fail. This incident is being tracked by the master package and logged into the ControlDB for further actions.
The master package now restarts the Sales.dtsx package again but disables the extract component since the data is already extracted and available in the staging tables in the warehouse. It just triggers the transform and load components from the child package. This is a benefit since we have saved a lot of time without having to re-extract the data from the source and did not impose and load on the source data systems by extracting the data twice. In the world of modern cloud technology, where customers already spend a huge amount of money on I/O, this could be a cost saver as there was no or minimal data transfer over the networks. This technique holds true for one to many numbers of the child packages that you want to design for your ETL workload provided you must maintain a proper logging mechanism by the master package to be able to detect failed executions and restart them correctly.
Scalability of the solution
Talking about the scalability of the above-mentioned ETL solution, we can leverage the scale-out feature of SSIS and run multiple child packages in parallel. This might also help to reduce the execution duration of the entire solution.

Figure 3 – Sequence Diagram – Modular ETL Architecture
If you look at the above sequence diagram, you can see that we have a master package that controls the execution of the Orders and Sales packages. As you can see, at first, the extract components of both the modules are executed in parallel. Once the extraction is completed, it then executes the subsequent preparation or transformation phase and finally executes the load component. At this time, data is successfully extracted from the source databases, transformed, and loaded into the data warehouse. Additionally, few solutions may also want to opt for an OLAP solution on top of the data warehouse for faster data querying and reporting. In such a case, you can also process the OLAP cube from the ETL solution without having to process the cubes separately.
Conclusion
In this article, we have understood how to design or build a modular ETL architecture. We have understood the underlying concepts using SSIS, although it is not only limited to SSIS. It can be used for any other ETL tool in the same way as with SSIS. Implementing a modular ETL architecture helps us to maintain a very loosely coupled data pipeline that is not dependent on the other components within the ETL pipeline. The main idea behind creating the modular packages is that each module can be converted into a child package that can be orchestrated using a master or a parent package. In my next article, Implementing Modular ETL architecture using SSIS, I am going to demonstrate in detail how to create an SSIS project with parent and child packages that will implement the modular architecture in ETL.
See more
For a collection of SSIS tools including SSIS package comparison, SSIS system performance monitoring and SSIS documentation, see ApexSQL SSIS tools


He is a prolific author, with over 100 articles published on various technical blogs, including his own blog, and a frequent contributor to different technical forums.
In his leisure time, he enjoys amateur photography mostly street imagery and still life. Some glimpses of his work can be found on Instagram. You can also find him on LinkedIn
View all posts by Aveek Das
- Getting started with PostgreSQL on Docker - August 12, 2022
- Getting started with Spatial Data in PostgreSQL - January 13, 2022
- An overview of Power BI Incremental Refresh - December 6, 2021