
Introduction
In this article, we will be discussing how to Tune Model Hyperparameters to choose the best parameters for Azure Machine Learning models. During this article series on Azure Machine Learning, we have discussed multiple machine learning techniques such as Regression analysis, Classification Analysis and Clustering. Further, we have discussed the basic cleaning techniques, feature selection techniques and Principal component analysis, Comparing Models and Cross-Validation until today in this article series.
In the Regression and Classification techniques, there are many techniques to choose from. For example, for two-class classification, there are many classification techniques such as Boosted Decision Tree, Decision Jungle, Decision Forest, Logistic Regression, Neural Network, and Support Vector Machine. In Regression, we have techniques such as Bayesian Linear Regression, Boosted Decision Tree Regression, Decision Forest, Linear Regression, Poisson Regression among other techniques. We learned that a proper model can be chosen by performing Model Comparisons in order to achieve better modeling predictions.
To improve the model’s performance, we have used feature selection techniques to find out what are the better input attributes. Further, we discussed that we can use Cross-Validation in order to perform a better evaluation. During the Clustering technique discussion, we came across with Sweep clustering option where the optimal number of clusters was defined. However, every technique has its own parameters to work. How do we know what are the best combinations of those parameters that will get us the best results? To mitigate that challenge, we can utilize the Tune Model Hyperparameters so that the best parameters will be selected from the tool itself.
Let us quickly create an Azure Machine Learning experiment as we have done multiple times before in previous articles.

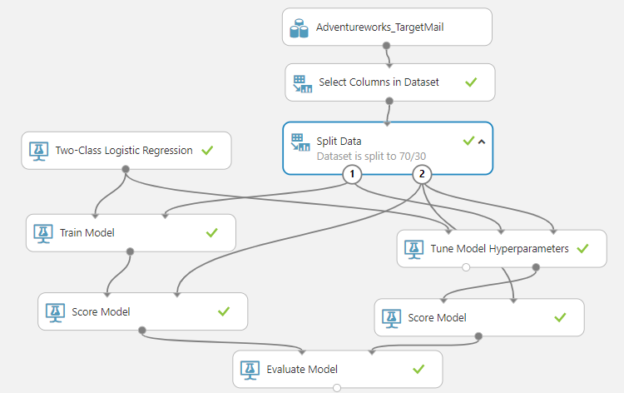
In this simple Azure Machine Learning Experiment, we have selected the common AdventureWorks data set which discusses the customers’ details of a mythical cycle selling company. Since we do not need all the attributes, we will filter attributes from Select Columns in Dataset control so that attributes such as addresses, names were eliminated. Then we will split data by 70/30 in order to train and test by using Split Data control. Then the train data set is sent to the Train Model control and Two-Class Logistic Regression is used to train the model. The BikeBuyer attribute is used as the predictive attribute in the Train Model. Finally, the built model was evaluated with the Evaluate Model control.
In the Two-Class Logistic Regression technique, there are many model parameters as shown in the below figure.

In order to model to work with higher accuracy, we need to choose the better parameter options for every technique that we select. Since there are four parameters in the Two-Class Logistic Regression technique, choosing the correct combinations will be a challenging task. Tune Model Hyperparameters will help to find the best combinations depending on the selected data set.
Let us see how we can implement Tune Model Hyperparameters in Azure Machine Learning to achieve the above-said objective.

In the above experiment, both the previous model and the TMH included the model so that we can compare both models. In the above experiment, Tune Model Hyperparameters control is inserted between the Split Data and Score Model controls as shown. In the TMH, control has three inputs. The first control needs the relevant technique and, in this scenario, it is the Two-Class Logistic Regression technique. The second input needs the train data set and the last input needs the evaluation data set and for that, the test data set can be used.
Tune Model Hyperparameters control provides the best combinations and it will be connected to the score model. After the test data stream is connected to the score model, the output of the model is connected to the second input of the Evaluate model so that the previous model and the tuned model can be compared.
The following figure shows the comparison of both models.

You will realize that there is no major difference between standard and tuned models. Similarly, Precision / Recall, LIFT charts can be used for the comparisons. Let us look at the other evaluation matrices for a typical Classification question such as Accuracy, Precision, Recall and F1 Score.

This will be compared with the model after tuning using the Hyperparameters Model.

You will see that in the tuned model there is a very little increase in the Accuracy from 75.9% to 76.2%. Though the F1 score also has very little increase, there is a small decrease in Precision and Recall.
Tune Model Hyperparameters for Regression
Similar to classification, tuning can be done for the Regression techniques as well. Let us change the above model with Decision Forest Regression. We will change the target column to YearlyIncome.

It is a similar Azure Machine Learning experiment like we did before for the Classification. Following are the model parameters for Decision Forest Regression which we need to configure using the same Tune model Hyperparameters for a better model.

Let us compare the evaluated model parameters for the Regression model.

In the above comparison, it is clear that TMH have reduced the model errors than the standard model.
Tune Model Hyperparameters Configuration
There are a few configurations:

There are three configurations to specify parameter sweeping mode that are Entire Grid, Random Sweep, and Random Grid. The entire Grid should be used when you do not know the best parameters to choose. In the random technique, it will generate all the combinations possible for the parameters.
Next, it has to select the attribute that you want to predict the YearlyIncome in this scenario. Since there are a few evaluate parameters, you need to choose the parameter that you are optimizing. In the above configuration, Accuracy is selected for the classification while Mean absolute error is selected for the regression problem. Accuracy, Precision, Recall, F-score, AUC, Average Log Loss, Train Log loss are the parameters for the classification while Mean absolute error, Root of mean absolute error, relative absolute error, Relative squared error, Coefficient of determination are available parameters for regression.
When you visualize the Tune Model Hyperparameters control you will see the combination of parameters along with the evaluation parameters. Following is the figure that shows the combinations for the classification technique.

You can see that different combinations of Optimization Tolerance, L1 Weight, L2 Weight, and Memory size are selected to improve the accuracy and parameters with the highest accuracy are selected to build the model.
Setting Ranges for the Parameters
When there are many parameters for the technique, obviously the model building will take a long time. You can provide the possible values or ranges as shown below so that model generation performance will be improved.

When the Tune Model Hyperparameters were observed, you will see that combinations are derived from the given parameters as shown below.

Cross-validation can be used with the TMH as shown in the below figure.

In the above configuration, Partition and Sample are set to 5 folds. We have discussed the usage of Partition and Sample control extensively in the Clustering article.
Conclusion
Tune Model Hyperparameters is used to choose better combinations of parameters for Classification and Regression Models. In Azure Machine Learning, we looked at how to choose hyperparameters from random and sweeping techniques. Further, we have the option of providing possible values or value ranges so that tuning of parameters can be done in quick time.
Further References
- https://docs.microsoft.com/en-us/azure/machine-learning/algorithm-module-reference/tune-model-hyperparameters
- https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/tune-model-hyperparameters
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021