
Introduction
Until now, we have discussed a few topics in Analytics in Azure Machine Learning many aspects in the last couple of articles, we will be discussing the Latent Dirichlet Allocation in Text Analytics in this article.
Before this article, we have discussed the most commonly used machine learning techniques such as Regression analysis, Classification Analysis, Clustering, Recommender Systems and Anomaly detection of Time Series in Azure Machine Learning by using different sample datasets including data access to SQL Azure. Further, we have discussed the basic cleaning techniques, feature selection techniques and Principal component analysis, Comparing Models and Cross-Validation and Hyper Tune parameters in this article series as data engineering techniques to date. In the first article on Text Analytics, we had a detailed discussion on Language detection and Preprocessing of text in order to organize textual data for better analytics and how to recognize Named entities in Text Analytics. In the last article of the series, we have discussed how to perform Filter Based Feature Selection in Text Analytics.
What is Latent Dirichlet Allocation
Latent Dirichlet Allocation or LDA is a statistical technique that was introduced in 2003 from a research paper. LDA is used for topic modelling in text documents. LDA is more often analog to PCA that we covered before. If you remember in PCA, we used to generate a single value for the existing values in a dataset. LDA will generate a topic for documents by analyzing the content of the document. This technique can be used to cluster documents as well which is an important task in text analytics.
In the azure machine learning, there is a special LDA control. You can download and view the complicated Azure Machine Learning experiment from here. This experiment has more than 50 fifty controls and lets us see what the azure machine learning controls are used in the experiment.
|
Control |
Purpose |
|
Dataset |
Six datasets were used. |
|
Select Columns in Dataset |
Remove unnecessary columns to improve readability. |
|
Add Rows |
Combine two different data streams into one data stream. Since only two data streams can be added by Add Rows control, multiple controls were used. |
|
Detect Languages |
Detect English language text. |
|
Split Data |
Split data depending on a criterion |
|
Enter Data Manually |
Enter data for as stop words |
|
Preprocess Text |
Preprocessing text so that the content can be modelled. |
|
Clean Missing Data |
Remove empty rows if exists |
|
Latent Dirichlet Allocation |
Apply LDA for the dataset and this is the new control that we are introducing from this article. |
|
Apply SQL Transformation |
Include Topic Name as a column |
Dataset
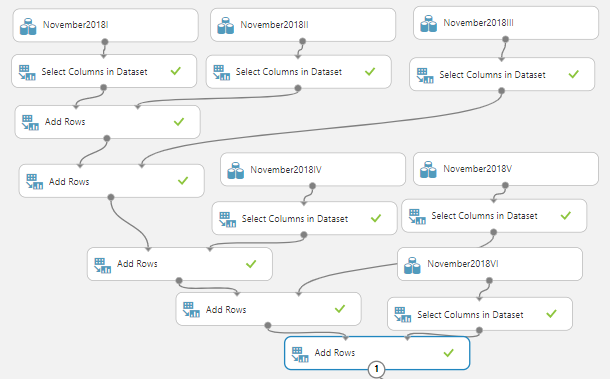
Since we need a rich dataset, we will be using the same dataset that was used in the entity recognition article. In this, we have combined six different datasets and unnecessary columns were removed from Select Columns in Dataset control as shown in the below figure.

We have joined the different news datasets and add them together using the Add Rows control.
After the dataset is created, next is to apply text analytics techniques that were performed in the previous articles.

First, we need to filter the English text by using the Detect Languages and Split Data controls. After English contents were filtered, we have performed Preprocess Text so that special characters are removed and stop words such as “a, and, the, is” are removed, etc. With all these processes, there can be situations where empty text will present. These empty records will cause errors therefore by using the Clean Missing Data control, those empty records are removed.
After the processing of text data, now we are ready to apply Latent Dirichlet Allocation as shown in the below figure.

Now let us see how to configure the Latent Dirichlet Allocation in Azure Machine Learning as shown in the below figure.

First, we have selected the attribute that we need to apply the LDA which is processed_media_content in this example. We would be looking at finding the main five topics to the model which is configured at the Number of topics to the model parameter. For the LDA, we are going to use bi-gram, therefore, we have configured 2 for the N-gram option.
Let us analyse the first two outputs of the Latent Dirichlet Allocation control in Azure Machine Learning. Let us look at the first output which is the transformed dataset.

The first column in the figure is the original content in the source and the preprocessed text can be seen in the second column. The next five columns are columns that are added from the LDA control. Each weighted says how close each content to each topic. If you have selected a different number of topics, those topics will be displayed here.
Ideally what you need is the content and the topic name in one column so that you can identify to what topic each content belongs. We can assign content to a Topic that has more than 0.5 weightage. To achieve this, we have used split data control with the following settings as shown in the below figure.

Then the unnecessary columns are removed from Select Columns in Dataset control as we did in many situations in previous articles.
Then by using Apply SQL Transformation control, the necessary topic is added as shown in the below figure.

The same approach will be carried out for the other four topics as well as shown in the following figure. Please note that the only selected portion of the experiment is shown.

All the data streams are added to a single data stream by using multiple Add Rows controls. The following is the final output from the above part of the experiment.

You can see that each content is assigned to the most relevant Topic.

The above figure shows the topic distribution in the content.
Similarly, we can follow the same approach to the second output of the Latent Dirichlet Allocation control that is the Feature Topic Matrix.
This output will display the different features of topics. The first column of the following figure shows the bi-grams and weightage for each topic.

As we did in the previous section, we will be using Split Data and Add rows controls to generate the relevant Columns. It is important to note that in the Feature topic matrix of Latent Dirichlet Allocation, there is additional space in the column. If you have used the same components, make sure that you change the configurations accordingly.
You can see how each N-gram is contributed to different topics as shown in the following figure.

Following is the distribution for topics for each N-Gram feature.

Please note that you can achieve this using python script as well. Python script would be much easier when you have topics in the range of 10 or more.
Summary
In this article, we looked at a topic modelling technique in Text Mining which is called, Latent Dirichlet Allocation. In Azure Machine Learning, there is a specific control named Latent Dirichlet Allocation. This control has the option of providing several topics. The control provides the different weights for the content and the N-grams.
By using the output of the LDA, and using the other controls such as Split Data, Add Rows, Select Columns in the Dataset and SQL Transformation controls, we were able to generate the most relevant topic for each content and the bi-gram feature. This feature can be extended to cluster the document as a similar Topic.
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021