
Introduction
AutoML in Azure Machine Learning is used to build machine learning models on its own as we discussed in the previous article. Over there, we discussed what AutoML is and how to develop classification models in AutoML using Azure Machine Learning. This article will be dedicated to the discussion about building machine learning models using AutoML for Clustering and Time Series tasks.
During the Azure Machine Learning series, we have discussed Regression analysis, Classification Analysis, Clustering, Recommender Systems and Anomaly detection of Time Series using Azure Machine learning Classic.
Regression
Let us create a New Automated ML run from Azure Machine Learning Studio. Then you need to select the dataset.

From the Select dataset option, we can select a necessary dataset for the regression task. In the last article, we created a new dataset, and, in this example, we will be using open datasets that are provided to build machine learning models in AutoML in Azure Machine Learning.

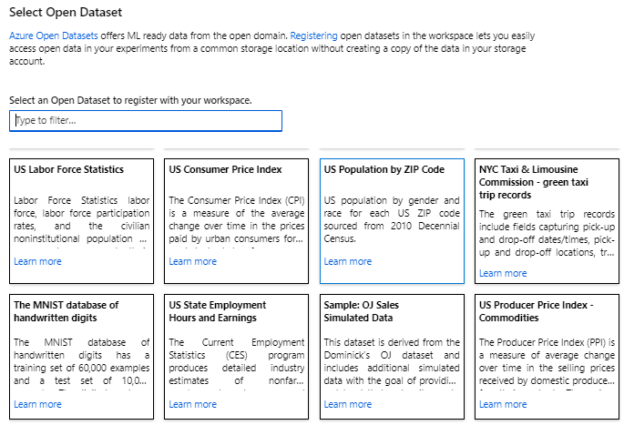
Once this option is selected, you will see the existing open-source datasets as shown in the below figure.

Every dataset has a description so that you can get an understating of the dataset. Let us select Sample: OJ Sales Simulated Data dataset to build a regression machine learning model.
Then you can register the dataset as shown below.

The following is the figure of the sample dataset after registering the dataset.

After the dataset is created, next is to create an experiment of AutoML in Azure Machine Learning to utilize the registered dataset.

In this AutoML configuration, the experiment name is entered, and the Target column is Revenue as we are going to predict the revenue using the regression techniques. As we discussed in the previous article, we have the option of creating dedicated virtual machines to process the AutoML processes. In AutoML, multiple models will be executed. Therefore, you need dedicated virtual machines which is a major advantage of using Azure Machine Learning Services.
Next is to select the task type which is Regression as shown in the below figure.

Once the regression model for AutoML in Azure Machine Learning is created, the next task is to set the additional configurations for the regression AutoML model.

In this additional configuration, you can define what is the primary metric. Normalized root mean squared error, Spearman correlation, R2 score, and Normalized mean absolute error are the options for a regression AutoML in Azure Machine Learning.
If you do not want to run some algorithms, you can select them so that those algorithms are not executed for those algorithms. This option can be used if you want to stop some algorithms due to performance or any other issues.
As these algorithms may take a little while to execute as Machine Learning needs a large volume of the dataset, therefore, we need to set the exit criterion. For example, we can set that if the algorithm is running for more than 3 hours, execution will stop. Further, we can define the metric score as the exit criteria.
Once the AutoML in Azure Machine Learning is processed, you will get the different models as shown in the following figure.

As you can see in the above figure, the best model is located at the top of the list and you can view evaluation parameters for the selected model as shown below.

Then you can publish the model to the live so that it can be utilized.
Time Series
Time Series Forecasting is one of the most complicated machine learning techniques due to the many components that are involved in Time Series. To demonstrate Time Series for AutoML in Azure Machine Learning, let us use NOAA Global Forecast System (GFS) dataset which is another open dataset.
This dataset has an additional feature of filtering date range as shown below.

By using the above filter, we can narrow down the dataset for the selected scenario. Depending on the dataset, there can be different filters. For example, the Holiday dataset has a filter for data range as well as a filter for the country, so that you can choose data for a specific date range as well as for a specific country.
After the dataset is selected, you can configure the Time Series for AutoML in the Azure Machine Learning service as shown in the below figure.

In this configuration, we have to select the target column as the temperature which is what we are going to forecast using the Time Series task. As we discussed before, we can choose dedicated hardware for the Machine learning process. We can expand or reduce the virtual machine loads, depending on the requirement and the dataset.
After selecting the Time Series as the task that we are going to process AutoML in Azure Machine Learning, we need to indicate additional parameters for the Time Series.

As time column is an important factor in Time Series analysis, we need to provide a Time column and if there are identifiers such as region, the country we need to provide that information as well. Frequency explains the frequency for the Time Column that can be auto-detected or you can provide the frequency that you want time series to be processed.
After the above configuration, we need to provide additional configuration settings as we did for classification and regression tasks.

First, we need to decide what is the primary metric to decide the best model in Time Series. In the above example, Normalized root mean squared error is the primary metric. Similarly, we can select the algorithms that we do not need to execute AutoML in Azure Machine Learning.
The next few parameters are specific to Time Series Task. Forecast target lags can be set to autodetect as well as the window for the lag.
Season and Trend is an important configuration in Time Series as forecasting depends not only on the trend but also on the season. Time Series depends on Holidays and you can select the holiday list that depends on the country that belongs to the dataset. This is a unique feature in AutoML in Azure Machine learning that will not be available in many other tools.
As we did in the previous tasks, we can set the Exit Criterion so that process will not execute for long hours. We can set either the maximum duration for the execution or the value of the primary matric parameter.
Like we did for the classification and regression tasks, the best model can be selected and deploy the model.
Conclusion
This article extended the discussion of AutoML in Azure Machine Learning for Regression and Time Series. These tasks have the same principle of providing the dataset and with the minimum of configurations, you can get the best model and deploy it. The best model will be selected depending on the primary metric that was configured. Time Series task has the option of incorporating different holiday calendars as holidays are dependent on the Time Series forecasting.
Further, this article explored how to register open-source datasets with different filters as well.
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021