
SQL (Structured Query Language) is an ANSI/ISO standard programming language that is designed to program relational databases and T-SQL (Transact-SQL) is an extended implementation of the SQL for Microsoft SQL Server databases. T-SQL is highly used by database persons when they want to program or manage the SQL Server databases. However, the beginners may do some mistakes without realizing when they write queries with SQL. In the next section of this article, we will glance at the common mistakes that may be made by newbies.
Pre-requisites
In this article examples, we will use the following tables and we also use the Adventureworks2019 sample database.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
CREATE TABLE Products ( Id INT IDENTITY(1, 1) PRIMARY KEY ,ProductCode VARCHAR(100) ,ProductName VARCHAR(100) ,ProductColor VARCHAR(50) ,Price INT ,PriceTax INT ,Size VARCHAR(1) ) INSERT INTO Products VALUES ('A42-12','Blue Jean','White',12,8,'L') , ('X74-12','Shirt','Blue',10,18,'S') , ('A19-01',NULL,'Purple',9,1,'M') , ('P-765','T-Shirt','Red',10,0,NULL) , ('Z-OP12',NULL,'Pink',28,0,'M') , ('AL-1211','Short','Yellow',6,12,'S') CREATE TABLE SizeTable( [Id] [int] IDENTITY(1,1) PRIMARY KEY NOT NULL, [SizeCode] [varchar](1) NULL, [SizeDefination] [varchar](100) NULL) INSERT INTO SizeTable VALUES ('M','Medium') ,('S','Small'),('L','Large'),('C','Child') |
Counting SQL NULL values
A NULL value specifies an unknown value but this unknown value does not equivalent to a zero value or a field that contains spaces. The COUNT() function returns the number of rows in the result set of a query. However, when we use this function with a particular column name it ignores the NULL values when it performs the counting operation. Let’s consider the following simple example.
|
1 2 3 4 5 |
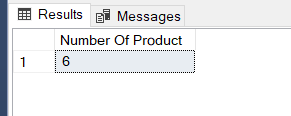
SELECT * FROM Products SELECT COUNT(ProductName) AS 'Number Of Product' FROM Products |
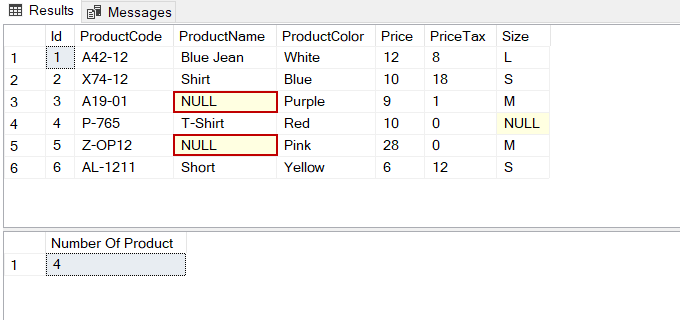
As we can see the ProductName column includes two NULL values but the count function does not count these rows. We can use the ISNULL function to include these NULL values into the count operation.
|
1 2 3 |
SELECT COUNT(ISNULL(ProductName,'')) AS 'Number Of Product' FROM Products |
Avoid the risk of the divide by zero error
In the T-SQL queries, we can divide one column value into another one. At this point, we need to consider divisor column values because when a number is divided by zero the result is undefined and the query returns an divide by zero error.
|
1 2 3 4 5 6 |
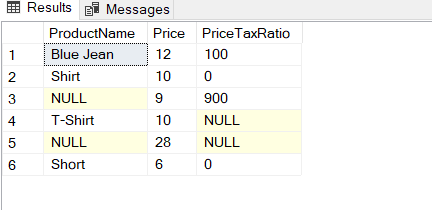
SELECT ProductName , Price , (Price / PriceTax) * 100 AS [PriceTaxRatio] FROM Products |
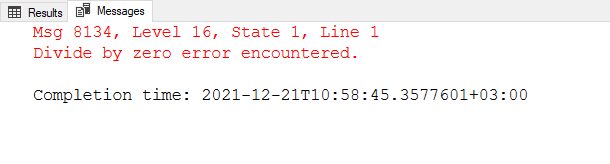
After the execution of the query, an error has occurred because of some zero values of the PriceTax column. To overcome this solution, we can use the NULLIF function for the divisor column. The NULLIF function takes two parameters and if these parameters are equal it returns a NULL value. So that, the zero division results will equal to the NULL instead of returning an error.
|
1 2 3 4 5 6 |
SELECT ProductName , Price , (Price / NULLIF(PriceTax,0)) * 100 AS [PriceTaxRatio] FROM Products |
Don’t use the “+” operator to concatenate the expressions
The plus sign might be used to combine string columns values but if any row of these columns includes a NULL value the result will be NULL. This case is seen clearly in the following query result, some long product name results are NULL because of the NULL product’s name.
|
1 2 3 4 5 |
SELECT ProductName, ProductColor , ProductName + '-' + ProductColor AS [Long Product Name] FROM Products |

We need to use the CONCAT function instead of using the “+” operator to combine the strings. The CONCAT function takes a set of the string parameter and returns the combined form of these parameters.
|
1 2 3 4 5 |
SELECT ProductName, ProductColor , CONCAT(ProductName , '-' , ProductColor) AS [Long Product Name] FROM Products |

As we can see, the CONCAT function is ignoring the NULL values when combining the string expressions. At the same time if we want to separate the combined expressions with a separator we can use the CONCAT_WS function.
|
1 2 3 4 5 |
SELECT ProductName, ProductColor , CONCAT_WS( '-',ProductName , ProductColor) AS [Long Product Name] FROM Products |

Define the column names explicitly in a T-SQL query
The asterisk symbol (*) can use to return the whole columns of a table or joined tables. Needless usage of the asterisk symbol causes some performance problems in the queries:
- Causes more network traffic
- Causes redundant I/O operations
Besides these performance problems, reading and maintaining the T-SQL code will become more struggle and required more time because interpreting which columns are required by the applications could not be easily understandable.
In the context of not defining the column names clearly, the second incorrect usage that we will mention is using the position numbers of the columns after ORDER BY. The column position numbers may be used after the ORDER BY clause in the T-SQL queries. In this usage type, SQL Server sorts the result set of the query according to the column or columns that are specified by the position number.
|
1 2 3 4 |
SELECT ProductCode, Price FROM Products ORDER BY 2 |
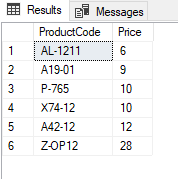
The query result is sorted according to the Price column in an ascending manner because this column is placed in the second position of the query result. The main disadvantage of this usage type is to reduce the code readability. Because of this issue, explicitly defining the column names after the ORDER BY clause will be gain more readability to the queries.
|
1 2 3 4 |
SELECT ProductName, Price FROM Products ORDER BY Price ASC |
Not use the NOT IN operator for the nullable columns
The NOT IN operator is used to filter out unmatched record values from a list or a subquery dataset. However, the NULL values cannot be correctly handled by the NOT IN operator because the NULL comparison with any value results will be always NULL. We can think to use the following query when we want to get the list of rows that do not have size codes in the products table.
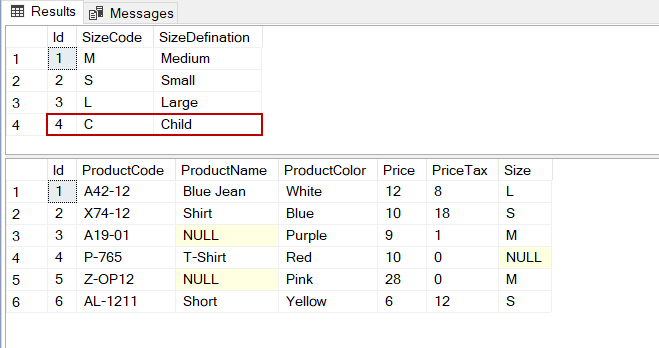
|
1 2 3 4 5 |
SELECT * FROM Products WHERE Size NOT IN (SELECT SizeCode FROM SizeTable) |
The query did not return any rows but we have expected that it returns the painted row in the image. The reason for this problem is related to the Size!= NULL expression result is always NULL, therefore the entire WHERE clause is always FALSE.
|
1 2 3 4 |
SELECT * FROM SizeTable WHERE SizeCode!= NULL |
We can use the NOT EXIST operator to overcome this problem.
|
1 2 3 4 5 6 |
SELECT * FROM SizeTable AS S WHERE NOT EXISTS (SELECT * From Products AS P WHERE S.SizeCode = P.Size) |
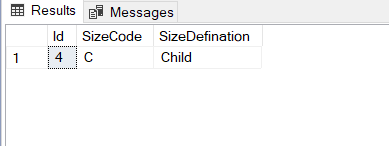
Avoid the implicit conversions in T-SQL queries
During the execution of a T-SQL query SQL Server can convert one data type to another one when it compares the different data type values. This operation is called implicit conversion and implicit conversion affects the query performance negatively because data conversion operation performs for all rows of the query and requires some resource. The following example query is comparing a column with data type varchar and a column with data type int.
|
1 2 3 |
SELECT ProductCode, Price FROM Products WHERE Price>'1' |
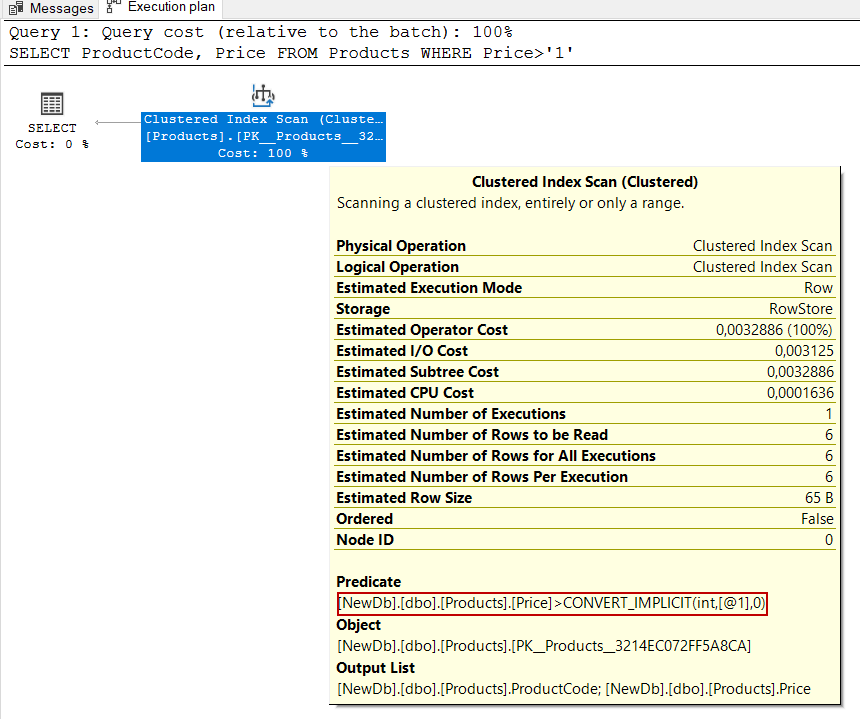
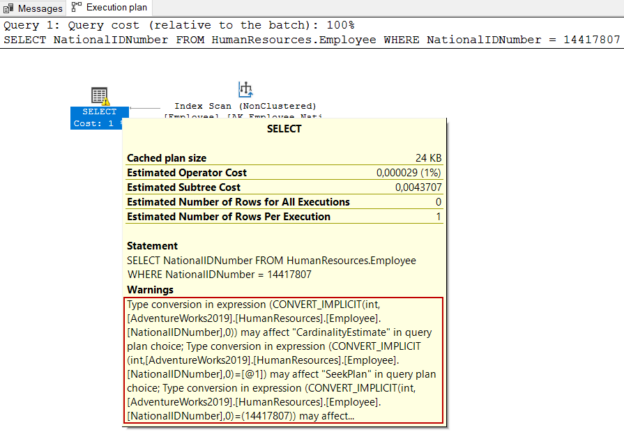
We can see the implicit conversion on the details of the execution plan of the query.
Effects of implicit conversion on the query plans
The SQL Server query optimizer is cost-oriented. Firstly, the optimizer estimates how many rows can return from a query using the statistics and then generates various query plan candidates for the executed T-SQL query. In the last step, it uses the query plan which has the cost lowest execution of the query. The implicit conversion can lead to generating non-optimal query plans by the optimizer because the optimizer cannot accurately predict the number of rows that can be returned from a query. Now, we will analyze the following query execution plan.
|
1 2 3 4 |
SELECT NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = 14417807 |
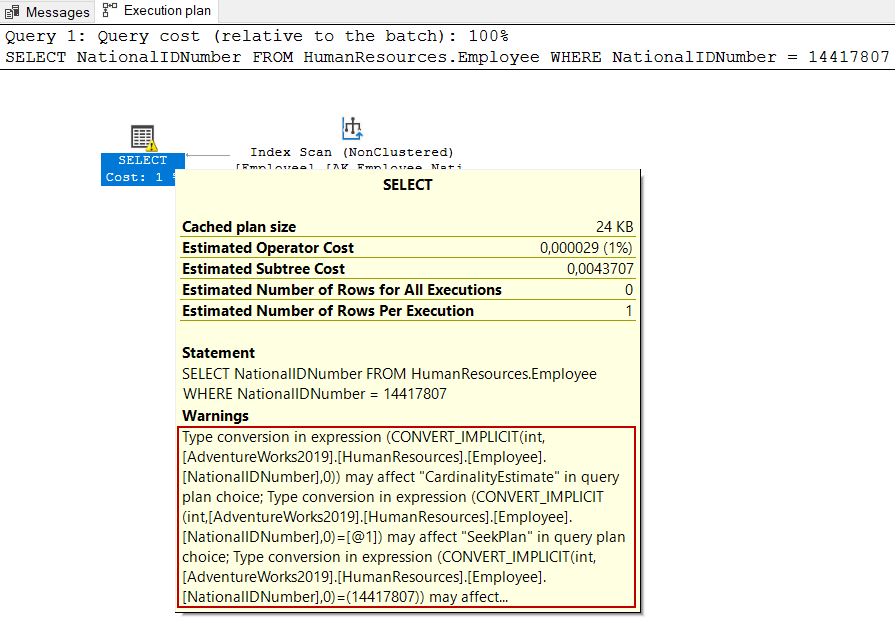
The warning sign indicates that there is an implicit conversion in the query, which can cause a non-optimal query plan to be used. Now, we will convert the WHERE expression to the proper data type and execute the same query again.
|
1 2 3 4 |
SELECT NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = N'14417807' |
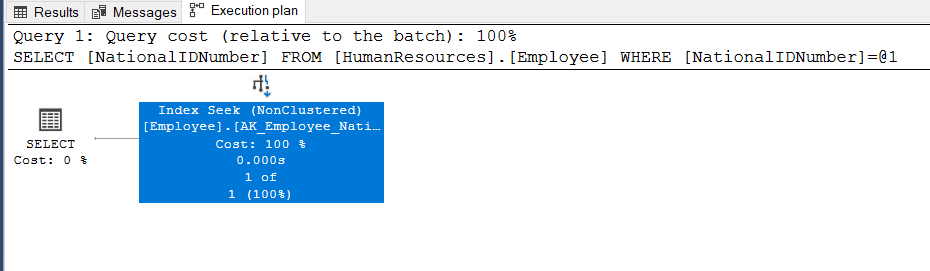
After the data type changes the optimizer generates the optimum query plan because the index seeks operation allows to directly access the matching rows.
Beware side effects of the non-sargable predicates
SQL Server can access the rows matching the filter criteria more efficiently through the index seek operator. However, if a function is inside the WHERE clause, the query optimizer can not decide to use index seek operation even if a suitable index exists. These types of queries are called non-sargable queries. The following query is non-sargable.
|
1 2 3 4 |
SELECT SalesOrderDetailID ,ModifiedDate FROM Sales.SalesOrderDetail WHERE YEAR(ModifiedDate)=2011 |
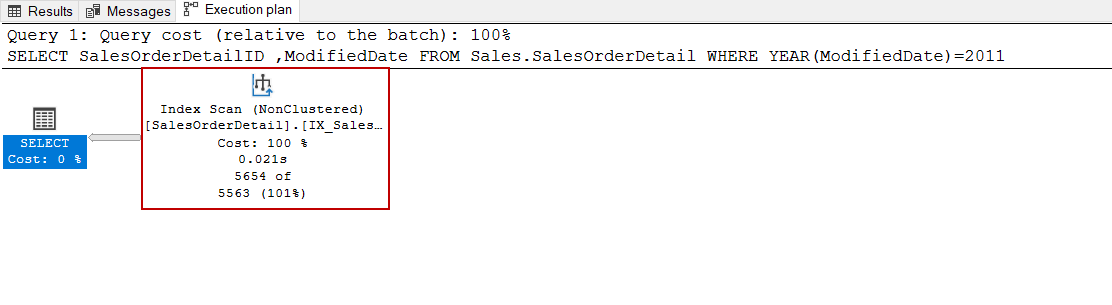
Creating an index for this query will not change its performance but let’s try it anyway.
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_ModifiedDate ON [Sales].[SalesOrderDetail] ([ModifiedDate]) |
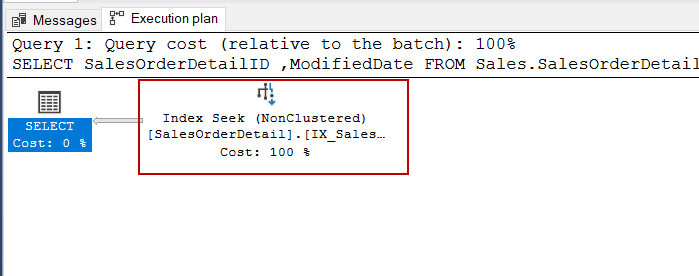
After creating the index, we re-executed the same query but the execution plan is not changed.
|
1 2 3 4 |
SELECT SalesOrderDetailID ,ModifiedDate FROM Sales.SalesOrderDetail WHERE YEAR(ModifiedDate)=2011 |
To get rid of this problem, we can make a little transformation in the WHERE clause of the query. Instead of using the YEAR function, we will set a date range for the specified year.
|
1 2 3 4 5 |
SELECT SalesOrderDetailID ,ModifiedDate FROM Sales.SalesOrderDetail WHERE ModifiedDate >= '01-01-2011' AND ModifiedDate < '01-01-2012' |
Summary
In this article, we learned 7 common mistakes that can be made when writing T-SQL queries. At the same time, we discovered these mistakes in solution methods.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023