

Introduction
In SQL Server there are several kinds of SQL partitions. However, in general, we can say that a partition is a way to divide a table (sometimes a view) into smaller pieces for performance purposes. In this article, we will explain what partition does mean for a table partition and SSAS. We will also provide some guidance to automate the partition process.
What does SQL partition mean?
Let’s start with the Table partition. If we have a big table with TB or GB of information, a select to search a single row may take forever to be executed. To solve the problem, a classic partition is to split the table into smaller pieces divided by month for example. You can partition by month, day, year. It depends on your needs.
It is like a thick book. Searching a single page for something will take too much time. Even with indexes. However, if we divide the book into smaller books, it will be faster and easier to search for a page. It will be faster to backup and recover the data.
Let’s start with table partitions scenarios and then we will talk about other types of partitions.
What does SQL partition mean in a table?
Table partition means to split the data across multiple tables to get better performance when the tables handle a considerable amount of data.
There are 2 main types of partitions in a table. Horizontal partition and vertical partition.
In a vertical partition, you could, for example, split the data into 2 tables:
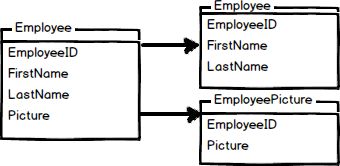
In the previous image, we split the Employee table into 2 tables. The Employee table contains the first name and last name and the other table is EmployeePicture. The images take a lot of resources, so it is a good idea to handle the data separately. It is a good practice to store the images in a separated Filegroup and hard disk.
On the other hand, we have the Horizontal partitioning
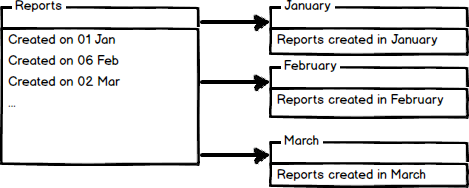
In horizontal partitioning, we divide a big table into smaller tables. The image above shows a partition of a report in tables per month.
For more detailed information about table partitioning and how to do it step by step, refer to our article related:
What does partition mean for automation?
We explained this before and provide a link to create horizontal partitions. We can automate the table partition process using scripts and monitor the partitions missed using T-SQL queries. To monitor partitions, you can use system tables like the following:
- Sys.indexes
- Sys.objects
- Sys.system_internals_allocation_units
- Sys.partition_schemes
- Sys.partition_functions
- Sys.partition_range_values
The following link provides a tutorial to maintain automatically your partitions.
What does SQL partition mean in SSAS Azure Tabular?
Previously, we talked about the Table partitions used in the SQL Server Database Engine. We worked with the famous and traditional OLTP Databases (Online Transactional Processes). Transactional databases are traditional databases to insert, update, delete data in transactions.
SQL Server included the OLAP databases later as a new concept of database to handle reports with a lot of data. The traditional OLTP databases are pretty slow to generate reports when several joins are required and several GB are used in the database. That is why Microsoft created the OLAP databases (Online Analytical Process) by buying the OLAP technology from Panorama Software from Canada first and then Microsoft improved the technology.
Microsoft created the SSAS (SQL Server Analysis Services) which was the technology used to create OLAP databases. Microsoft started with the Multidimensional Databases. This technology is very powerful, but a little difficult to understand for OLTP DBAs or Developers because it handles different architecture, structures, and components.
To simplify the process to create reports, Microsoft introduced a new feature named Tabular Models. Which is a technology easier to understand and to create reports and queries. To create a new Multidimensional database from scratch, refer to the following link:
If you want to create a tabular database, refer to the following link:
These technologies started being On-premises technologies. However, Microsoft is moving all the efforts in the Cloud.
Now, these technologies are in Azure, then, the SQL partitions for the Tabular and Multidimensional databases are in Azure.
When you use SSDT, creating columns, DAX (Data Analysis Expressions) queries, MDX (Multi-Dimensional Expressions) queries, XMLA (XML for Analysis), and TMLS (Tabular Model Scripting Language) it is transparent if the model is On-premises or in Azure.
In this article, we will explain what partition does mean in Azure Tabular Models. However, the concept is the same for Tabular Models On-Premises.
In a Tabular Model, what does a partition mean?
We can say that it is the same concept to divide the table into smaller pieces using queries. A partition in a Tabular Model is Part of a Table divided into smaller pieces using a query.
In this example, we will show how to do it. I am assuming that you already have a Tabular Instance installed and that you are using the AdventureWorks Tabular Project (take a look at the Implementing an SSAS Tabular Model article if not).
In the Adventureworks Tabular project, select the Internet Sales table.
In the Menu, go to Extensions>Table>Partitions.
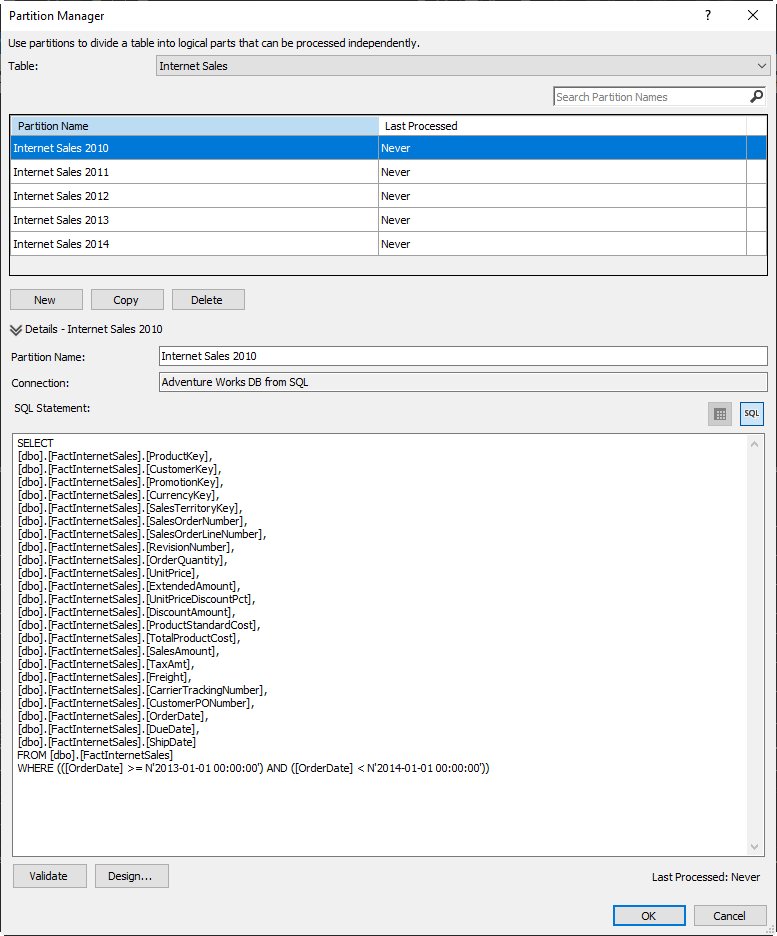
You will see the different partitions for Internet Sales. The partition in this example is per year.
Internet sales 2010, 2011,..2014.
The main difference between partitions is in the where clause. The range of dates of each partition is different. For example, for the Internet Sales 2011 partition the where clause is the following:
WHERE (([OrderDate] >= N’2011-01-01 00:00:00′) AND ([OrderDate] < N’2012-01-01 00:00:00′))
On the other hand, for the Internet Sales 2012 is the following:
WHERE (([OrderDate] >= N’2012-01-01 00:00:00′) AND ([OrderDate] < N’2013-01-01 00:00:00′))
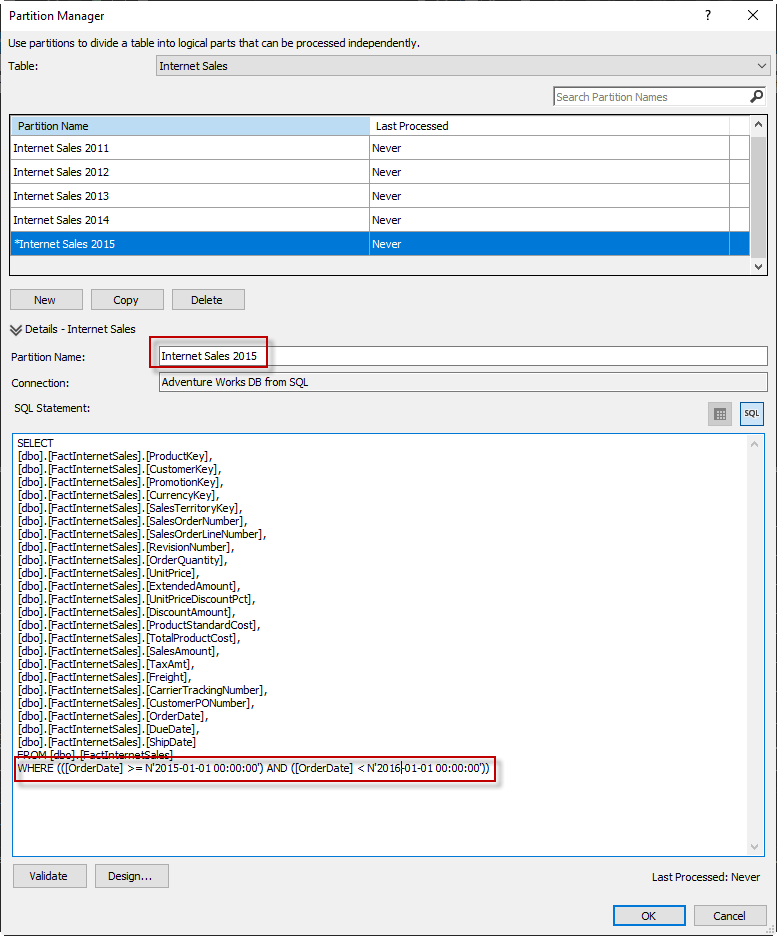
As you can see the difference is very simple. Let’s create a new partition.
Press the New button and in the Partition Name text box write Internet Sales 2015 and, in the query, modify the WHERE Clause to the following and press OK
WHERE (([OrderDate] >= N’2015-01-01 00:00:00′) AND ([OrderDate] < N’2016-01-01 00:00:00′))
The SQL partition will improve not only the queries that apply to specific partitions but also will reduce the time to process information. If you have a query that belongs to the 2012 partition only, the query will be faster than a model without partitions, because when you have partitions only the query that belongs to the range of the query is used to search.
What does partition mean in terms of automation for Azure Tabular models?
If you want to automate partitioning in Azure Analysis Services tabular models, we strongly recommend reading this link:
Conclusion
In this article, we learned what does SQL partition mean in two different scenarios. In a table partition, we explained what is a horizontal and vertical partition. We need to create filegroups, add files and create partitions and partition schemes.
On the other hand, we have partitions in SSAS which is a special technology for reports. We learned how to create partitions in Tabular models using an SSAS Tabular project.
We finally presented our article related to Dynamic Partition in Azure SSAS.
See more
ApexSQL Complete is a SQL code complete tool that includes features like code snippets, SQL auto-replacements, tab navigation, saved queries and more for SSMS and Visual Studio


He has worked for the government, oil companies, web sites, magazines and universities around the world. Daniel also regularly speaks at SQL Servers conferences and blogs. He writes SQL Server training materials for certification exams.
He also helps with translating SQLShack articles to Spanish
View all posts by Daniel Calbimonte
- PostgreSQL tutorial to create a user - November 12, 2023
- PostgreSQL Tutorial for beginners - April 6, 2023
- PSQL stored procedures overview and examples - February 14, 2023