

Introduction
In my previous article, we went over the basics of Mercurial, as well as some arguments why using it is critical for database administrators. Among many reasons, it allows us to easily track history and changes to our scripts, which in turn makes it easier for us to experiment and enhance our toolkit, since we can do so safely without fear of permanently causing damage. In this installment, we are going to go into more depth on the specifics of two feature of Mercurial that, once harnessed, can add significant efficiency to our coding workflows.
Branching
First, let’s go over the concept of branching. Mercurial’s official documentation defines the term “branch” as follows: “Branches occur if lines of development diverge. The term ‘branch’ may thus refer to a ‘diverged line of development’. For Mercurial, a ‘line of development’ is a linear sequence of consecutive changesets.” In other words, we spawn off a new line of development from a base (or “parent”) state of the code. This in turn allows us to continue working on the new branch without disturbing the original.
A common use of this is to create a new branch on which development of a new feature can commence, while still leaving the main (or “default” in Mercurial’s own terminology) branch stable and untouched. The Mercurial wiki has a discussion of this approach which you should review; however I think this is best illustrated with an actual example, written down as it happens.
I have a stored procedure written which collects and displays blocking information in an easily consumable format. Currently, the functionality, while stable, is fairly limited. For example, the procedure only handles certain kinds of resource locks, namely those involving database files, objects (tables, procedures, triggers, functions, etc), extents (a 64kb block of data in SQL Server), pages (a smaller, 8kb block of data; an extent is made up of eight pages), and individual rows of data. However, there’s quite a few other resources that sessions can hold locks on. For example, by altering a database user, we will (for the duration of the session transaction) hold locks that prevent anyone else from further modifying the same principal (SQL’s terminology for user).
|
1 2 3 4 5 6 7 8 9 10 |
USE tempdb; GO CREATE USER [testuser] WITHOUT LOGIN; GO BEGIN TRAN ALTER USER [testuser] WITH DEFAULT_SCHEMA = sys; GO SELECT * FROM sys.dm_tran_locks dtl WHERE dtl.request_session_id = @@SPID; |
After running this command, you will see the following results. Note the highlighted section, which shows the locks held on the database principal (the fancy term for a user in a database).

I would like to enhance my stored procedure to display this information as well, but I don’t want to do so on the main branch in case I discover issues that need to be corrected in the meantime.
The process to complete this operation can be summarized in the following steps.
- Create the new branch.
- Complete the work required for the feature, committing along the way as necessary (it’s a good idea to do frequent commits to have relatively stable save point of work).
- Merge the branch back to the main ( “default” ) branch when development is complete.
Let’s go through each of these.
Creating a branch in Mercurial is as simple as issuing a command.
PS C:\A_Workspace\sql-tools> hg branch block_db_principal
marked working directory as branch block_db_principal
(branches are permanent and global, did you want a bookmark?)
Congratulations, you have successfully created a new branch in your Mercurial repository! We can now safely proceed with messing around with things.
Note: there are those that would advocate simply cloning a completely separate copy of the existing Mercurial repository for this sort of thing, rather than creating a branch. My personal opinion is that is a little heavy handed, but might be useful in cases where you’re really tearing things up. For a really good discussion of the pros and cons of this approach (and several others), see this blog post. It’s a little out of date, but still very well written and useful.
Once the branch has been created, you can proceed to make your changes as you normally would. When they are complete and ready to be committed, simply use the “hg commit” command that we talked about in the previous article. There’s no need for any additional options to ensure that the change is committed to the specific branch we created, as Mercurial automatically switched to the new branch when it was created. We can verify this by running the “hg log”command.
PS C:\A_Workspace\sql-tools> hg log -l 1
changeset: 88:e13dd43f3a7e
branch: block_db_principal
tag: tip
user: yardbirdsax
date: Sun Jan 31 17:52:09 2016 -0500
summary: Finished enhancement to also show locks / blocks on database principals.
We can also see this in the graphical interface by right clicking in the folder where the file resides and selecting “Hg Workbench”.
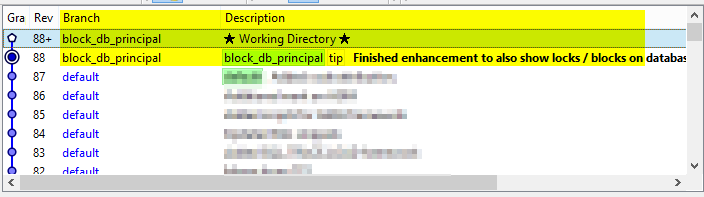
At this point we could continue to experiment on the modified code, or if we are at a good stopping point, we can proceed to merge the changes back into the main (or “default”) branch.
Merging in this context simply means that the changes made on the experimental branch will be applied to the relevant files in the main branch. In this case, this was a relatively simple change that only resulted in one revision, however it’s important to note that if multiple revisions were committed on the experimental branch they would all be merged in upon running the merge command. This is important to understand, since there may be times when we don’t want to incorporate all changes made on another branch; perhaps we’ve incorporated a number of experimental tweaks, but only want to merge in a few of them. In that case, rather than a merge, we would use the “graft” functionality, which allows for individual revisions to be moved into another branch.
It’s also important to note that if changes have been made in parallel to the main branch, it’s possible that conflicts will occur. In this case, Mercurial will let you know that this is the case, and present you with a graphical screen to manually resolve the conflicts. Generally this isn’t necessary, as Mercurial does an excellent job of merging on its own, however I’d recommend becoming familiar with how to do this so that when it happens, it doesn’t throw you off your game. For an excellent tutorial and explanation of this process, see this link.
In our case, neither of these situations will occur, so we can simply use the standard merge command. First, we need to move back into the main branch, which is accomplished using the “hg update” command. Then, we run the “merge”command, specifying the name of the branch we’d like to merge from. Finally, we commit the changes.
PS C:\A_Workspace\sql-tools> hg update default
5 files updated, 0 files merged, 0 files removed, 0 files unresolved
PS C:\A_Workspace\sql-tools> hg merge block_db_principal
1 file updated, 0 files merged, 0 files removed, 0 files unresolved
(branch merge, don’t forget to commit)
PS C:\A_Workspace\sql-tools> hg status
M sp_get_block_chain.sql
PS C:\A_Workspace\sql-tools> hg commit -m”Merge of database principal changes”
The changes are now present in the main branch. If there’s additional work to be done, we can continue to add revisions to the other branch (we merely have to ensure we are pointing to it first, using the “hg update” command again), or we can close the branch if you are done with it.
Child scripts
One of the more powerful conveniences afforded by the use of source control is the concept of child files. Here’s the basic idea: let’s say you have a generic script used to do some kind of work, perhaps applying some configurations to a server. This is done in the same way across all the servers in your environment. That is, it’s done the same until some specific requirement comes up for one server that necessitates a change. Let’s say the change is a small one, in that the other 90% of work done in the script stays the same. While you could simply copy the file and make the modification, by doing so outside of Mercurial you’ve effectively broken the link between the two files. This means that any changes / corrections made upstream to the original file will not get propagated down to the copy.
Instead, we can create the copy through Mercurial itself, thus keeping the two files tied together. Let’s expand out the example given above to see how this works.
Let’s say we have a simple script file that sets the cost threshold for parallelism value. For all the servers across your environment, you want this value set to 25. However, something comes up with one of the servers, and you decide that it would be best in this case to set it lower, say, 10.
Here’s exactly how to create the linked copy, and how to make alterations that can be merged into the copies with minimal effort.
First, make a copy of the file, using Mercurial’s built in “hg copy” command.
PS C:\A_Workspace\repo> hg copy .\serverconfig.sql .\serverconfig.db01.sql
PS C:\A_Workspace\repo> hg status
A serverconfig.db01.sql
As you can see, the file has already been added, but not committed. We can now make our changes to the file, shown below using the WinDiff tool.

Now we can commit the file.
PS C:\A_Workspace\repo> hg commit -m”Added copy of Server Config script for db01.”
Some time later, we decide that we need to change one of the other setting listed in the file, specifically the one that disables CLR integration. First, we need to determine the revision at which that line was added, using the aforementioned “hg blame” command.
PS C:\A_Workspace\repo> hg blame .\serverconfig.sql
6: EXEC sys.sp_configure
6: @configname = ‘show advanced options’,
6: @configvalue = 1;
6: RECONFIGURE;
6: EXEC sys.sp_configure
6: @configname = ‘cost threshold for parallelism’,
6: @configvalue = 25;
6: RECONFIGURE;
6: EXEC sys.sp_configure
6: @configname = ‘backup compression default’,
6: @configvalue = 1;
6: RECONFIGURE;
6: EXEC sys.sp_configure
6: @configname = ‘clr enabled’,
6: @configvalue = 0;
6: RECONFIGURE;
6:
6:
Now, we need to change our working folder to point to that revision, using the “hg update” command.
PS C:\A_Workspace\repo> hg update 6
0 files updated, 0 files merged, 1 files removed, 0 files unresolved
Then, we can make our change to the file, which you can see shown below in WinMerge.

Now, we commit the change.
PS C:\A_Workspace\repo> hg commit -m”Updated server config script to enable CLR.”
created new head
As you can tell from that familiar “created new head” message, we now have two lines of code that need to be merged together. Since the changes here are fairly simple, we can run the “hg merge” command and Mercurial will take care of the rest.
PS C:\A_Workspace\repo> hg merge
merging serverconfig.sql and serverconfig.db01.sql to serverconfig.db01.sql
0 files updated, 1 files merged, 0 files removed, 0 files unresolved
(branch merge, don’t forget to commit)
After a merge operation, it’s important to review all the changed files before actually committing the merge. After all, perhaps the changes you applied might override a change you made in one of the linked scripts on purpose. For example, let’s say we decide to make the default Cost Threshold for Parallelism value 20, rather than 25. Following the steps above, here is what we would do.
PS C:\A_Workspace\repo> hg blame .\serverconfig.sql
6: EXEC sys.sp_configure
6: @configname = ‘show advanced options’,
6: @configvalue = 1;
6: RECONFIGURE;
6: EXEC sys.sp_configure
6: @configname = ‘cost threshold for parallelism’,
6: @configvalue = 25;
6: RECONFIGURE;
6: EXEC sys.sp_configure
6: @configname = ‘backup compression default’,
6: @configvalue = 1;
6: RECONFIGURE;
6: EXEC sys.sp_configure
6: @configname = ‘clr enabled’,
8: — Changed to 1 to enable CLR across all servers.
8: @configvalue = 1;
6: RECONFIGURE;
6:
6:
PS C:\A_Workspace\repo> hg update 6
1 files updated, 0 files merged, 1 files removed, 0 files unresolved
…make our changes…
PS C:\A_Workspace\repo> hg commit -m”Updated default cost threshold value to 20.”
created new head
When we issue the ‘merge’ command, Mercurial is smart enough to realize that we’ve modified a line that we touched in a downstream version of the file, and pops up WinMerge to show you the difference.

Since we want to keep the line setting Cost Threshold to 10, we right click on that line and select “Copy to Right”.

Then, click the ‘Save’ button (or just press Control-S).
Note, if we don’t do the same for the second change highlighted above (the change to enable CLR by default), we’ll get an odd result, namely that the change we first made (to set the CLR enable bit) is gone. Why? I don’t want to get into too much detail, but in brief the reason for this behavior has to do with the current revision of our working folder. Since we are currently at a revision based off the earlier one (revision 6), the “merge” command treats that revision as the “gold” one. We could reverse this, however, by first updating to the last revision we worked on before deciding to make this change, which we can see by running the “hg heads” command.
PS C:\A_Workspace\repo> hg heads
changeset: 10:fb84cc84e80a
tag: tip
parent: 6:0b6bcb8816c8
user: yardbirdsax
date: Sun Feb 14 14:51:26 2016 -0500
summary: Updated default cost threshold value to 20.
changeset: 9:093aeb9a93c9
parent: 8:01c3dd64fa0f
parent: 7:5a36eb8916a9
user: yardbirdsax
date: Sun Feb 14 14:50:33 2016 -0500
summary: Merge of CLR enable change.
The key to determining this is noting that the revision we need to target is not tagged as the “tip”, or most forward head.
Let’s say we already ran the merge command, but luckily we reviewed our changes before committing and noticed. In order to undo the merge and get to a clean state of the proper revision (9), we need to use the “hg update” command with the “-C” switch specified.
PS C:\A_Workspace\repo> hg update 9 -C
2 files updated, 0 files merged, 0 files removed, 0 files unresolved
PS C:\A_Workspace\repo> hg merge
WinMerge will now display, and we can clearly see the changes highlighted, which are the opposite of what we saw earlier. For easy comparison, I’ll present both screenshots below.

Original
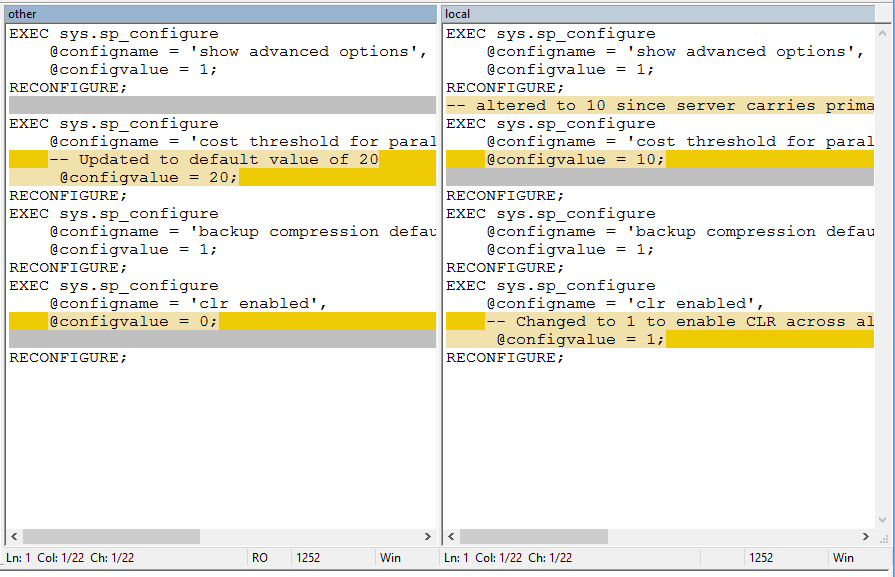
New
In this case, we can clearly see that no changes need to be made (one incoming change overrides something specific to our script, the second overwrites a change we know we later made). All we need to do is close the window, and Mercurial will kindly let us know that no changes have been made.
merging serverconfig.db01.sql and serverconfig.sql to serverconfig.db01.sql
output file serverconfig.db01.sql appears unchanged
was merge successful (yn)? y
merging serverconfig.sql
0 files updated, 2 files merged, 0 files removed, 0 files unresolved
(branch merge, don’t forget to commit)
Now, we can commit the changes and move forward!
Conclusion
In this article, we’ve introduced two key benefits of using Mercurial to track your scripts and files as a DBA: first, the use of branches as a means to harmlessly experiment or work on enhancements to your code library while keeping a stable version readily available; second, the use of related (or “linked”) copies to make the process of ensuring changes get pushed down into all related files. If this is at all confusing to you, don’t worry. Understanding the nuances of how source control behaves takes time and experience. For example, that whole last section on the differences in behavior of merging two revisions came about after I discovered this very problem writing this article. The end result (a controlled record of changes and ensuring changes are pushed to related files) is surely worth it however. Above all else, don’t be afraid to experiment! Simply make a copy of your existing repository (a simple Copy and Paste of the folder will do fine), and mess around until you get it right.
In a future article, I plan on going over some specifics around best practices for various kinds of scripts, such as those for creating SQL Agent jobs, setting up SQL Agent Alerts, and others. For now, I hope you have been convinced that source control (and Mercurial in particular) is a valuable and necessary part of the DBA’s toolbox.
See more
To seamlessly integrate SQL source control directly into SSMS, check out ApexSQL Source Control, a SQL source control SSMS add-in that allows you to view conflicts and resolve directly in the UI, lock objects to prevent overwrites, apply changes with dependency aware scripts and more


In what was originally a temporary job creating reports for clients of a financial company, he decided we would rather write some VBA macro code than repeatedly push the same buttons on a keyboard .
After working in low level development and support roles, he transitioned to the role of a full time SQL Server DBA, supporting both production and development systems, and has never looked back.
He currently works as a senior DBA for Gateway Ticketing Systems, advising customers on maximizing SQL Server performance and availability. He also recently co-founded the independent software startup Do It Simply Software. He loves learning about what makes SQL Server tick, and how to make it go faster. For more information, follow him at sqljosh.com
View all posts by Joshua Feierman
- A DBAs Introduction to Mercurial – Branching and merging - February 19, 2016
- A DBAs introduction to Mercurial – Working with files and changes - January 28, 2016
- A DBA’s introduction to Mercurial – When and why we should use version control - December 18, 2015