
In this article, we will explore some secrets about SQL Table Variables.
Introduction
Table variables are special variable types and they are used to temporarily hold data in SQL Server. Working with the table variables are much easier and can show remarkable performance when working with relatively small data sets. In spite of that, they have some unique characteristics that separate them from the temporary tables and ordinary data tables. In the next section of this article, we will take a glance at the unique characteristics of the SQL table variables.
Parallel processing
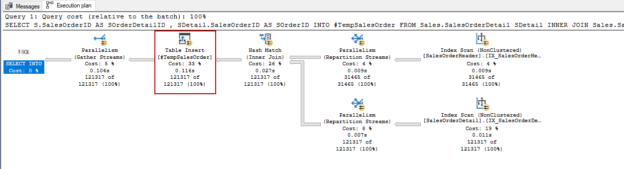
SQL Server can execute the queries using more than one thread in other words, it can process queries in a parallel manner. However, there is an exception for the table variables. The query optimizer can’t generate a parallel query plan when we want to populate data into the SQL table variables. At first, we look at the temporary table behavior pattern in an insert statement. The following query inserts all rows of the SalesOrderDetail table into the #TempSalesOrder temporary table.
|
1 2 3 4 5 6 7 8 9 10 |
IF OBJECT_ID(N'tempdb..#TempSalesOrder') IS NOT NULL BEGIN DROP TABLE #TempSalesOrder END GO CREATE TABLE #TempSalesOrder (SOrderDetailID INT ,SOrderID INT) INSERT INTO #TempSalesOrder SELECT S.SalesOrderID , SDetail.SalesOrderID FROM Sales.SalesOrderDetail SDetail INNER JOIN Sales.SalesOrderHeader S ON SDetail.SalesOrderID = S.SalesOrderID |
The graphical execution plan of the query shows us, the query optimizer has decided to use the parallel operators until the table inserts operation. The Index Scan operators have fulfilled their tasks in parallel. In this execution plan, we need to consider one point about the insert operation. The insert operation did not execute in a parallel manner. The reason we did not use the TABLOCK hints in the insert operator. When we use a TABLOCK hint in the insert query, the insert operations will be performed in parallel.
|
1 2 3 4 5 6 7 8 9 10 |
IF OBJECT_ID(N'tempdb..#TempSalesOrder') IS NOT NULL BEGIN DROP TABLE #TempSalesOrder END GO CREATE TABLE #TempSalesOrder (SOrderDetailID INT ,SOrderID INT) INSERT INTO #TempSalesOrder WITH(TABLOCK) SELECT S.SalesOrderID , SDetail.SalesOrderID FROM Sales.SalesOrderDetail SDetail INNER JOIN Sales.SalesOrderHeader S ON SDetail.SalesOrderID = S.SalesOrderID |

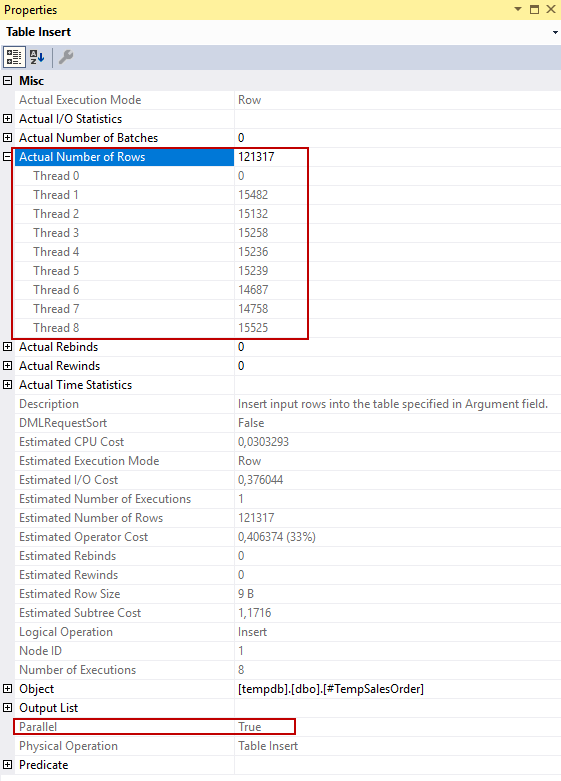
The Actual Number of Rows attribute shows the number of rows processed by each thread.
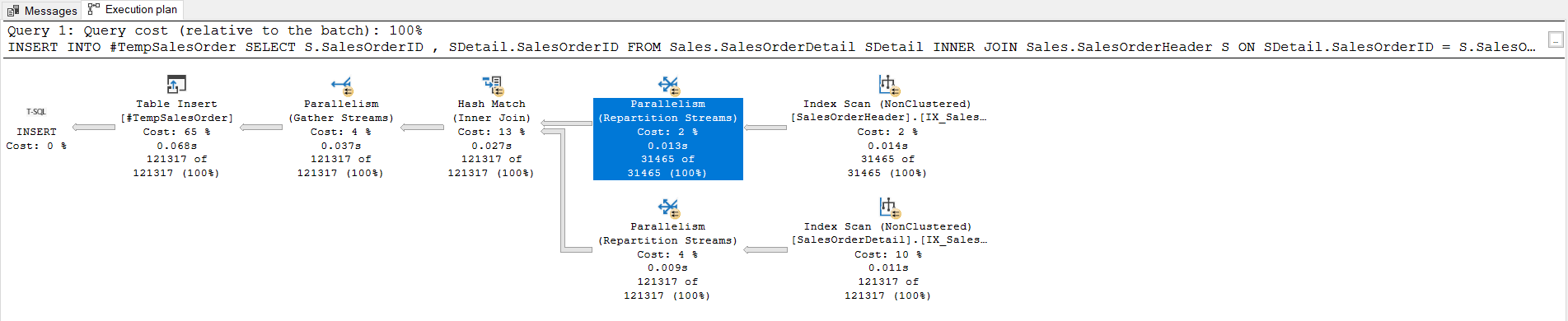
At the same time, the SELECT… INTO statement can enable parallel insertion operations. In this statement type, we don’t need to explicitly define the temporary table.
|
1 2 3 4 5 6 7 8 9 |
IF OBJECT_ID(N'tempdb..#TempSalesOrder') IS NOT NULL BEGIN DROP TABLE #TempSalesOrder END GO SELECT S.SalesOrderID AS SOrderDetailID , SDetail.SalesOrderID AS SOrderID INTO #TempSalesOrder FROM Sales.SalesOrderDetail SDetail INNER JOIN Sales.SalesOrderHeader S ON SDetail.SalesOrderID = S.SalesOrderID |

Now, we will use the table variable instead of the temporary table in the insert query and then observe its query plan output.
|
1 2 3 4 5 |
DECLARE @TableVarSalesOrder TABLE(OrderDetailID INT ,SOrderID INT) INSERT INTO @TableVarSalesOrder SELECT S.SalesOrderID , SDetail.SalesOrderID FROM Sales.SalesOrderDetail SDetail INNER JOIN Sales.SalesOrderHeader S ON SDetail.SalesOrderID = S.SalesOrderID |

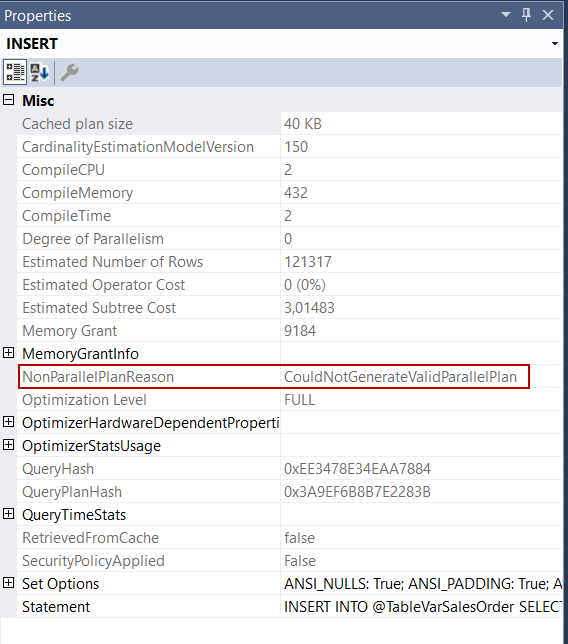
As we can see clearly, the query optimizer could not use parallel operators because of the SQL table variable. The reason for this issue is explained in the NonParallelReason attribute of the INSERT operator by the optimizer. This attribute value indicates CouldNotGenerateValidParallelPlan and it means that something is preventing generating a parallel plan. For our example, this problem is related to the SQL table variables.
Another point about the parallelism and table variables is related to the select queries. When we execute the following query the query optimizer will generate a serial plan for the query.
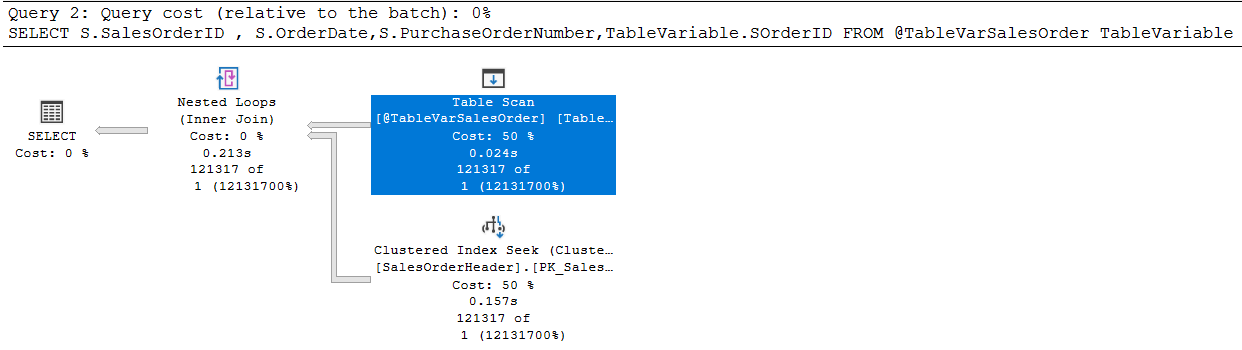
This issue is directly related to the estimated number of rows because the optimizer thinks the created table variable has only one row. Despite that, the actual number of rows is very far from this estimation.

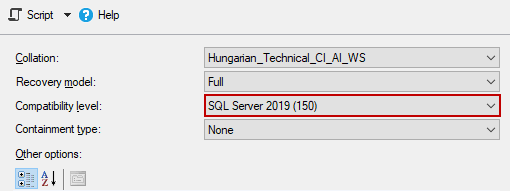
If we are using SQL Server 2019 version, there is no need to worry about this issue. The SQL Table Variable Deferred Complication feature resolves this problem without any changes. Only we need to change the database compatibility level to 150.
However, if our version is less than SQL Server 2019, we can add the RECOMPILE hint at the end of the query to overcome this problem. With the help of this hint, the query optimizer will make a more proper estimation because the optimizer will consider the accurate number of rows for the table variable.
|
1 2 3 4 5 6 7 8 9 |
DECLARE @TableVarSalesOrder TABLE(SOrderDetailID INT ,SOrderID INT) INSERT INTO @TableVarSalesOrder SELECT S.SalesOrderID , SDetail.SalesOrderID FROM Sales.SalesOrderDetail SDetail INNER JOIN Sales.SalesOrderHeader S ON SDetail.SalesOrderID = S.SalesOrderID SELECT S.SalesOrderID , S.OrderDate,S.PurchaseOrderNumber,TableVariable.SOrderID FROM @TableVarSalesOrder TableVariable INNER JOIN Sales.SalesOrderHeader S ON TableVariable.SOrderID = S.SalesOrderID OPTION (RECOMPILE) |
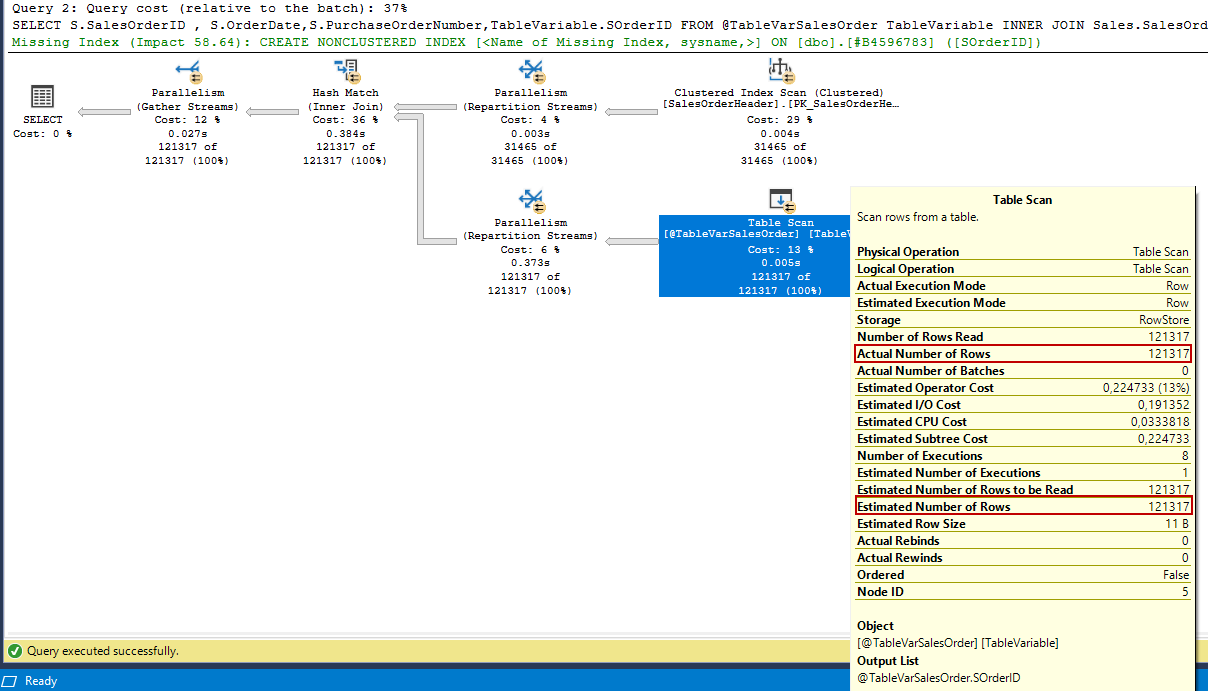
Looking at the image above, we can realize that the Actual Number of Rows value is equal to the Estimated Number of Rows so the optimizer makes the proper decisions.
At the same time, we can use TRACE FLAG 2453 to overcome the same problem. We enable the trace flag at the top of the query and then disable it again at the end of the query.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DBCC TRACEON(2453) DECLARE @TableVarSalesOrder TABLE(SOrderDetailID INT ,SOrderID INT) INSERT INTO @TableVarSalesOrder SELECT S.SalesOrderID , SDetail.SalesOrderID FROM Sales.SalesOrderDetail SDetail INNER JOIN Sales.SalesOrderHeader S ON SDetail.SalesOrderID = S.SalesOrderID SELECT S.SalesOrderID , S.OrderDate,S.PurchaseOrderNumber,TableVariable.SOrderID FROM @TableVarSalesOrder TableVariable INNER JOIN Sales.SalesOrderHeader S ON TableVariable.SOrderID = S.SalesOrderID DBCC TRACEOFF(2453) |
CHECK Constraints
The check constraints are used to enable control of any condition when a row of data is inserted or modified. In addition to this, the check constraints are effectively used by the query optimizer to avoid consuming unnecessarily I/O operations. Such as, the SalesOrderHeader table includes the CK_SalesOrderHeader_Status constraint and does not allow adding a row with a value not between 0 and 8 in the Status column. The following query execution plan does not generate any I/O because of this constraint.
|
1 |
SELECT SalesOrderID, Status FROM Sales.SalesOrderHeader WHERE Status =9 |

The query optimizer knows that there is no row in the table with the Status column value equal to 9 because of the check constraint. As a result, the optimizer does not perform any read operations.
We can create check constraints on the SQL table variables during the declaration of the table variable but these constraints can not be used by the optimizer. In the following query, we declare a table variable and we also add a check constraint that is similar to the SalesOrderHeader.
|
1 2 3 4 5 |
DECLARE @TableVarSalesOrder TABLE(SOrderID INT PRIMARY KEY , StatusCol tinyint , CHECK ((StatusCol>=(0) AND StatusCol<=(8)))) INSERT INTO @TableVarSalesOrder SELECT SalesOrderID, Status FROM Sales.SalesOrderHeader SELECT SOrderID, StatusCol FROM @TableVarSalesOrder WHERE StatusCol =9 |
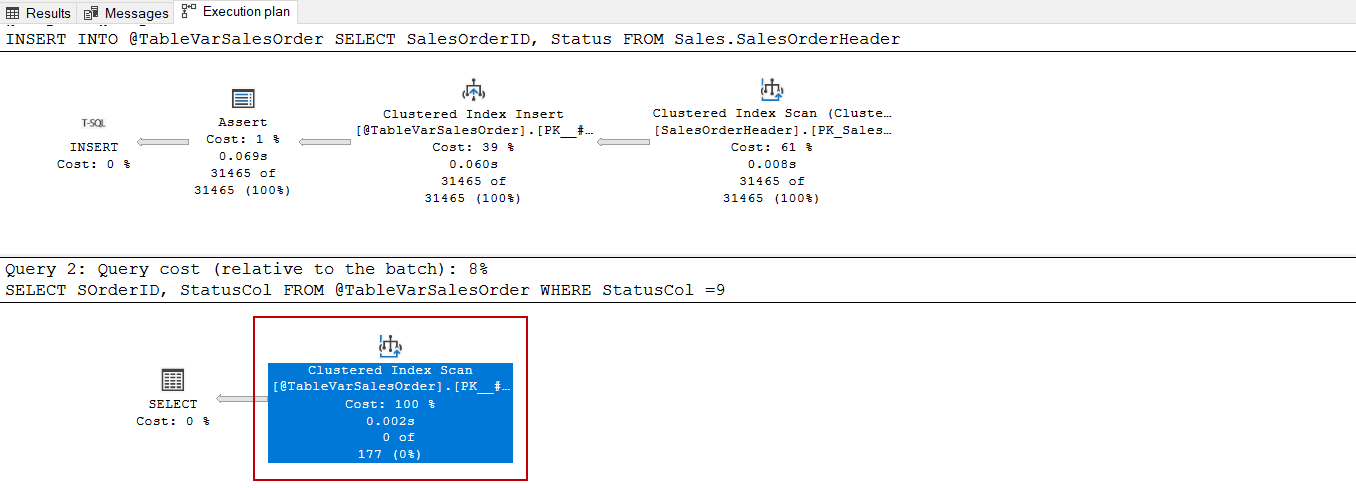
As we can see, the query optimizer did not consider the check constraint when deciding on the query plan.
Transactions
Transactions are the smallest logical unit that helps to manage the CRUD (insert, select, update and delete) operations in the SQL Server. However, the transaction operations are not possible for SQL table variables. In the following query, we will start an explicit transaction and then insert some rows into the table variable and then we will roll back the transaction. In this case, we think the query result set will be empty.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DECLARE @SpringMonthList TABLE(MonthNumber INT, NameofMonth VARCHAR(40)) BEGIN TRAN INSERT INTO @SpringMonthList VALUES (3,'March') , (4,'April') , (5,'May') ROLLBACK TRAN SELECT * FROM @SpringMonthList |
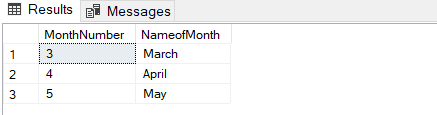
TRUNCATE TABLE statement and SQL table variables
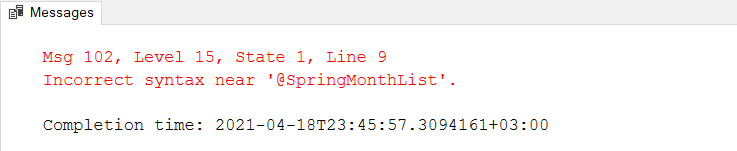
TRUNCATE table statements remove all rows of the data from a table and generate a minimal log in the transaction log. However, we can not use this statement for the table variables. In the following query, we try to truncate the @SpringMonthList table variable but the query will return an incorrect syntax error.
|
1 2 3 4 5 6 7 8 9 |
DECLARE @SpringMonthList TABLE(MonthNumber INT, NameofMonth VARCHAR(40)) INSERT INTO @SpringMonthList VALUES (3,'March') , (4,'April') , (5,'May') TRUNCATE TABLE @SpringMonthList |
Transaction Logging
The common misconception about the SQL table variables is that they are thought to be stored in memory. This knowledge is completely wrong because the table variables are stored in the tempdb database. At the same time, another wrong knowledge about the table variables is that they don’t generate any log activity. However, during the life-scope of the table variables, they generate log activity on the tempdb transaction log files. Let’s prove this working mechanism as an example.
As a first step, we will write the flush log buffer to the disk with help of the CHECKPOINT command. In the second step, we will declare a very simple SQL table variable and insert one row into it. The table variable is created and dropped implicitly at the start and the end of the query for this reason we will monitor the log activity during the same scope. The fn_dblog is a function that helps to retrieve information about the portion of the transaction log file. This function takes two parameters start and end Log Sequence Number (LSN) but if we pass these two parameters as NULL, we can retrieve all activities on the log file. When we execute the fn_dblog function after the CHECKPOINT statement only we will see the checkpoint start and end logged.
|
1 2 3 4 5 6 |
CHECKPOINT; GO SELECT [Current LSN],Operation,Context,[Checkpoint Begin],[Checkpoint End] ,[Transaction ID] FROM fn_dblog(NULL, NULL); GO |

The LOP_BEGIN_CKPT operation specifies the CHECKPOINT operation starts and the LOP_END_CKPT specifies the CHECKPOINT operation completes.
Now, we will bring the all parts together and execute the following query and try to understand its output.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
USE tempdb GO CHECKPOINT GO DECLARE @SampleTable TABLE(ColFA9044EE5CDB INT) INSERT INTO @SampleTable VALUES (0) SELECT Operation, Context, AllocUnitName, [Begin Time], [End Time], [RowLog Contents 0], [RowLog Contents 1], [RowLog Contents 2], [RowLog Contents 3], [RowLog Contents 4], [RowLog Contents 5], [Log Record Length], [Transaction ID] FROM fn_dblog(NULL, NULL) WHERE [Transaction ID] IN ( SELECT DISTINCT [Transaction ID] FROM fn_dblog(NULL, NULL) WHERE AllocUnitId = ( SELECT a.allocation_unit_id FROM sys.system_internals_allocation_units a INNER JOIN sys.partitions p ON p.hobt_id = a.container_id INNER JOIN sys.columns c ON c.object_id = p.object_id WHERE c.name = 'ColFA9044EE5CDB')) ORDER BY [Transaction ID] ASC |

The above image illustrates the generated logs during declaring and inserting a row into the table variable. The LOP_BEGIN_XACT operation indicates the transaction is opened and the LOP_COMMIT_XACT operation indicates the transaction is committed.
Conclusion
In this article, we have explored some secrets about the SQL table variables. Table variables have some unique limitation characteristics so we need to consider these attributes when we decide to use table variables in our queries.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023