
Power BI is a business analytics solution provided by Microsoft. It helps you to create data visualizations from various data sources. We can import data from these data sources, create a data model, and prepares reports, visuals. These data sources are as below:
- File data sources: Excel, flat files, XML, JSON, PDF, Sharepoint
- Database data sources: SQL Server, Oracle, MySQL, IBM Db2, IBM Informix, SAP HANA, Teradata, Snowflake, MariaDB, Google BigQuery and Amazon Redshift
- Power Platform data sources: Power BI datasets, workflows, Microsoft Dataverse
- Azure data sources: Azure SQL Database, Azure Analysis Services database, Azure Data Explorer, Azure HDInsight (HDFS), Azure Databricks and Azure Blob Storage
- Online Services data sources: Salesforce, GitHub, LinkedIn Sales Navigator, Dynamics 365, Microsoft Exchange Online, Emigo Data Source, Smartsheet, Google Analytics and Adobe Analytics
- Other data sources: Web, ODBC, OLE DB, Active Directory, SharePoint, Python, R scripts, Hadoop File (HDFS) TIBCO
In this article, we will explore the following topics:
- How do we connect these data sources?
- What are the different kinds of data models?
- Note: In this article, I will use the following abbreviations to keep things easier
- PBD: Power BI Desktop
- PB: Power BI
Different data models in Power BI
We have the following models for connecting either on-premise or cloud-based data sources.
- Import data
- Direct Query
- Composite mode
- Live Connection
In this tip, let’s explore these data models and the difference between them.
Importing a data model in Power BI Desktop
In the Import mode, we import data into the PB cache. It is the default and standard method for developing models and creating visualizations. Once we save the PBD solution, it saves the imported data into the disk. Data is loaded into its cache, and you can query data or prepare visuals. Suppose you are importing data from a 1 GB excel sheet. In that case, your data model does not acquire a 1 GB file size. It uses the VertiPaq compression engine based on the column-store in-memory technology. If you check the solution file size of PBD after data import, you might see it in a few MBs due to data compression.
In the Import data mode, you can use one or more data sources for importing your data, as shown below.

We import 5m Sales Records from a CSV file – 595 MB size (Reference file: Sample CSV File) for the demonstration.
Load data into PBD and save the data model. It creates a PBIX file in your local system.
Note the difference in file sizes:
- CSV file size: 595 MB
- Data model PB size using data import model: 122 MB
As discussed earlier, PB uses the VertiPaq storage engine for the compressed data.

The import data model provides the following benefits.
- The import data model delivers speedy performance for data visualizations
- It supports all features such as Q&A, Quick Insights
The import data model has the following disadvantages as well.
- This model requires sufficient memory and resources on your system for both loading data and refresh data
- Generally, the model per dataset size cannot exceed 1 GB. PB premium offers more dataset storage
- Data refresh requires reloading the entire table. You can use Power BI premium for the incremental load; however, it is a preview feature
DirectQuery model in Power BI
In the DirectQuery model, PB does not import the data. It retains only metadata that defines the model structure. When we query the data model, it uses native queries against the data source and fetches data.
For example, let’s say data is stored in tables of a SQL Server database. In the data connectivity mode, you get two options.
- Import
- DirectQuery

The DirectQuery mode is suitable for cases where data is stored in relational databases. For example, you can use it for Microsoft SQL Server, Oracle, Amazon Redshift, Azure Data Bricks, Azure SQL Database, Impala, Google BigQuery, Snowflake, Teradata, SAP HANA.

DirectQuery provides the following benefits.
- The main benefit of the DirectQuery data model is metadata storage. You might have a large database table(TB’s) required for your model. It might not be feasible to import such massive data in the Power BI model. Therefore, you avoid the chances of model size limitations in the PB
- You can easily create visualizations over the large volume of data
- In the DirectQuery model, PB sends queries to the data source. Therefore, it gets read-time data. You do not require data refresh manually that loads all tables data similar to a data import model
- Report users get the latest data while interacting with report filters and slicers
- You can use the Automatic page refresh feature for real-time reports
- The DirectQuery model requires minimal memory for metadata load
The disadvantages of the DirectQuery model is as below.
- It does not support the integration of data from multiple data sources
- The model performance depends on the underlying data source. Suppose you have SQL Server as an underlying data source. DirectQuery sends the query to SQL Server for data execution, but there is a resource crunch on the SQL Server instance. In this case, your query might not return data quickly, impacting PBD model performance
- It supports limited DAX function support, especially for measure and time intelligence expressions
- You cannot have any calculated tables in this data model
- It does not support Q&A and Quick Insights features
- The DirectQuery model does not have a 1 GB limitation for a dataset
Composite model in the Power BI
In the Composite mode, you can combine both Import and DirectQuery models.

It can deliver the best performance from both import and DirectQuery mode. You can configure the table storage mode as Import, DirectQuery, or Dual mode. If you configure a table as Dual storage, it can use both Import and DirectQuery. The PB service determines the efficient way between these modes.
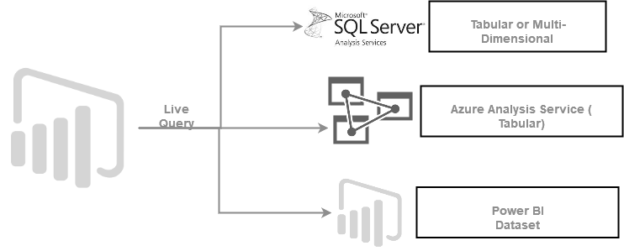
Live Connection mode
The Live connection mode in PB do the following:
- It does not import data into the cache like a data import mode
- It does not store a copy of metadata like a direct query mode
In this case, PBD has used a visualization tool for your data model. The live connection is suitable for the case where a model already exists. It is supported for the following data sets.
- SQL Server Analysis Service ( SSAS) tabular or multi-dimensional
- Azure Analysis Service (tabular model)
- PB dataset
-
Note:
- We cannot have a live connection for the SQL Server database
- It can connect only one data source for live connection

For example, if you try to connect with the SQL Server Analysis Service Database, you get two import options.
- Import
- Connect live

The advantage of the live connection mode is as below:
- The live connection works faster in comparison with DirectQuery. You get the performance benefit of the analytical engine performance
- The data model, calculations, and processing are done at the analytics engine that is much more efficient than the Power BI engine
- The SSAS tabular model can use DAX that can create complex calculations for your dashboards
- The compressed data is stored in a tabular format in the Azure Analysis service
The disadvantage of the live connection is as below.
- Similar to a DirectQuery mode, the live connection supports a single data source. In case you have multiple connections, you need to combine them into the SSAS model
- You cannot use the Power Query Transformations in the live connection mode
- In a live connection, the Power BI acts as a visualization tool. Therefore, you must handle all data transformation in the analysis service model
- You cannot define relationships in this model
- It does not support a multi-dimensional model for Azure Analysis Service
Conclusion
In this article, we explored different data models for the Power BI service. Each data model has its pros and cons. It would be best to choose the appropriate data model based on the data source and its performance requirements.
Table of contents
| An overview of Power BI data models |
| Azure Analysis Services and Power BI Live connections |
| Direct Query Mode in Power BI for Azure Analysis Services |

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023