

One of the most important roles of a database administrator is to constantly protect the integrity of the databases and maintain the ability to recover quickly in case of a failure. In light of this, it’s critically important to have a backup-and-recovery strategy in place in order to be ready for an emergency.
A key responsibility of a database administrator is to ensure that a database is available whenever it’s needed, and prepare for various scenarios wherein the availability or the performance is impacted. Therefore, if a database, for whatever reason, gets corrupted, gets dropped, gets accidentally deleted, or goes into an unusable state, it is a database administrator’s responsibility to bring the database back up in a working state with little to no loss as per the defined service level agreements or government policies.
Database administrators must be prepared to deal with disaster recovery scenarios. One way of doing that is by testing SQL Server backup and restore strategies at regular intervals. This ensures seamless recovery of data. And seamless recovery means quick recovery of systems with minimal or no data loss. Of course, a database administrator’s responsibility is also to safeguard data from the various data failures.
While designing the backup and restore plan, we need to consider the disaster recovery planning with reference to specific needs of business and the environment. For example, how do we recover from a case of multiple data failures across three prime locations in the environment? How long would it take to recover the data and how long would the system be down? What amount of data loss can the organization tolerate?
Another important point that database administrators have to concentrate on is the nature of the storage of data. This directly impacts the usefulness as well as the efficiency of the backup-and-restore process.
There are plenty of advanced techniques available such as Clustering, AlwaysOn, LogShipping and Mirroring that help ensure higher availability but still disaster recovery is all about having a well-defined and tested backup-and-restore process.
Points to consider defining good backup strategy including the:
- frequency at which data changes
- online transaction processing
- frequency of the schema changes
- frequency of change in the database configuration
- data loading patterns
- nature of the data itself
In this article, we will touch upon the aforementioned points, and take a look at the requirements as well, based on attributes such as the size of the databases, their internal details, and the frequency of changes. Let us now go ahead and look at the considerations that are important to building a solid backup strategy.
SQL Server backups include all database objects: tables, indexes, stored procedures and triggers. These backups are commonly used to migrate databases between different SQL Server instances running on-premises or in the cloud. They can be used for data ingestion, disaster recovery, and so forth as well, though. Native backups simplify the process of importing data and schemas from on-premises SQL Server instances, and they will be easy for SQL Server administrators to understand and use. We use backups to:
- migrate databases
- refresh development environments
- recover from accidental deletes
- move a database to a different drive
- import and export data
- offload reporting needs using high-availability Log Shipping
- Handle single or multiple database instances
- create database copies for testing, training and demonstrations
- transfer backup files into and out of cloud storage to give an added layer of protection for disaster recovery
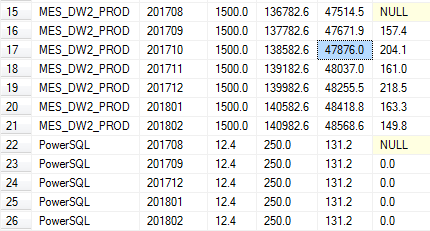
The following transact-SQL script can be used to fetch the growth trend of the database using the backup_history table. The backup information is always stored in the msdb database. In some cases, you may get a limited data, based on the maintenance tasks or clean up tasks created to purge data. The backup size details can be found in the dbo.backupset table which contains a row for every successful backup operation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
DECLARE @endDate datetime=getdate(), -- last six month trends @months smallint=6 SELECT [database_name] AS DatabaseName, MAX(YEAR(backup_start_date) * 100 + MONTH(backup_start_date)) AS YearMonth , CONVERT(numeric(10, 1), AVG([backup_size]/1024/1024)) AS BackupSizeMB, CONVERT(numeric(10, 1), AVG([compressed_backup_size]/1024/1024)) AS Compressed-BackupSizeMB, CONVERT(numeric(10, 1), AVG([backup_size]/[compressed_backup_size])) AS Compres-sionRatio FROM msdb.dbo.backupset WHERE [database_name] = N'MES_DW2_PROD' AND [type] = 'D' and backup_start_date BETWEEN DATEADD(mm, - @months, @endDate) AND @endDate GROUP BY [database_name],DATEPART(mm,[backup_start_date]) Order by YearMonth desc |
The above query can be modified to get an overview of the backup sizes on a daily or weekly basis depending on the granularity you want.
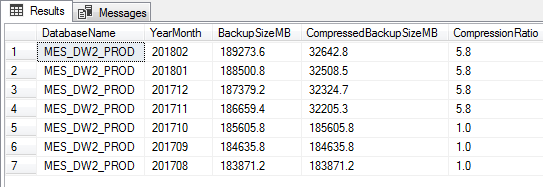
The following T-SQL uses msdb.dbo.backup_history table to analyze the growth of the database over a given period. The metrics are useful for capacity planning and forecasting with reference to backup
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
-- Transact-SQL script to analyse the database size growth using backup history. DECLARE --Define the range to fetch growth metrics @months smallint=6 @endDate datetime=getdate(), ;WITH HISTORY AS (SELECT DBS.database_name AS DBName ,YEAR(DBS.backup_start_date) * 100 + MONTH(DBS.backup_start_date) AS YearMonth ,CONVERT(numeric(10, 1), MIN(DBF.file_size / 1048576.0)) AS MinMB ,CONVERT(numeric(10, 1), MAX(DBF.file_size / 1048576.0)) AS MaxMB ,CONVERT(numeric(10, 1), AVG(DBF.file_size / 1048576.0)) AS AvgMB FROM msdb.dbo.backupset as DBS INNER JOIN msdb.dbo.backupfile AS DBF ON DBS.backup_set_id = DBF.backup_set_id WHERE NOT DBS.database_name IN ('master', 'msdb', 'model', 'tempdb') AND DBF.file_type = 'D' AND DBS.backup_start_date BETWEEN DATEADD(mm, - @months, @endDate) AND @endDate GROUP BY DBS.database_name ,YEAR(DBS.backup_start_date) ,MONTH(DBS.backup_start_date)) SELECT H.DBName ,H.YearMonth ,H.MinMB ,H.MaxMB ,H.AvgMB ,H.AvgMB - (SELECT TOP 1 H1.AvgMB FROM HISTORY AS H1 WHERE H1.DBName = H.DBName AND H1.YearMonth < H.YearMonth ORDER BY H1.YearMonth DESC) AS DBGrowthMB FROM HISTORY AS H ORDER BY H.DBName ,H.YearMonth |
Summary
One of the key aspects of safeguarding or protecting the data is performing backups.
To define the right backup and recovery strategy, one should understand:
- The type and nature of the data
- The frequency of backup
- The nature and speed of the underlying hardware
- The backup media: tape drive, local disc, network share, remote share or cloud services
- The network bandwidth
We should also consider testing the backups frequently because knowing the best-suited way to restore the data is equally important.
In reality, most of the organizations can absorb some sort of data loss, along with unavailability of the database for a few minutes or hours.
A zero-data-loss backup solution strategy may require special design and that may attract additional cost to manage the resource required to ensure that the data streams are backed up to multiple destinations regularly.
The other important aspect is the Recovery-Time-Objective, or RTO. This takes into consideration the amount of time that the system can be down for, in order to balance the cost of the system being offline against the cost of restoring the system quickly and maintaining the infrastructure and personnel to do this at a moment’s notice.
Let’s calculate the time required for the backup and restoration process that meets the objectives of the RTO (Recovery Time Objective). Assume that the size of database “X” is 32 GB, (or 32*1024=32768 MB). Let’s assume that the backup throughput is 120 MB/minute. Therefore, the time required to backup database “X” would be 32768/120 = 273 minutes (which is ~ 4 hours 33 minutes). Let’s assume that the restore throughput 100 MB/minute, therefore, the time it takes to restore database”X” would be 32768/100 which is 327 minutes (or ~5 hours 27 minutes).
As we can see, the time taken to create a backup is about ~4.5 hours, and the restoration process takes ~5.5 hours. This is the RTO (Recovery Time Objective) for this database. This is the calculation we need to base our RTO timelines on, which we need to keep in mind while planning our backup-and-restore strategy.
The frequency of the backups defines the dimension of the data when a disaster occurs. The more the backups, better is the restore process and able to meet the RPO (Recovery Point Objective)

Backup and storage are complimentary to each other. If the frequency of the database backup is higher, more storage is needed, which therefore brings in some budgetary constraints on just how practical it is to backup more frequently. The storage location is another point that is important for the strategy. The onsite and offsite storage have determined significance on Recovery-Point-Objective. If you store all the backup data on premises and some physical disaster occurs at your location, it will not only destroy the servers but also destroy all the backup media, meaning there is no way to restore the lost data. If you’re storing some of the backup off site, it may lead to an increase in the restoration time. So in most of the designs, during the initial few weeks, the data is stored locally. The backups are later moved offsite. Storing data offsite requires mandatory measures to protect the data using proper encryption and security policies. Once a backup has left your physical control, you have given up some amount of security.
Multiple rounds of testing will help us identify most of the problems.
Tape media is fragile and has a finite lifespan. It would be less than desirable if we proceeded to do a restore and found that the tapes were unreadable. If you’re testing them on a regular basis, hopefully, you will catch this problem during one of your tests rather than during a real disaster. If you’re testing the restore on a regular basis, then you should be very comfortable performing it and should be able to perform it quickly.
The larger the database, the more time it will take to restore the database. The only way to be sure about how long it’s going to take is to do some trial runs and share the results with your organization’s leadership so that the decision-makers know what to expect when it comes to the time required for a restore.
Table of contents
References
- SQL Server Database Recovery Process Internals – database STARTUP Command
- Best Practice recommendations for SQL Server Database Backups
- Backup History and Header Information (SQL Server)
- Database and Transaction Log Files
See more
For High-speed SQL Server backup, compression and restore see Quest LiteSpeed, an enterprise tool to schedule, automate and backup SQL databases


My specialty lies in designing & implementing High availability solutions and cross-platform DB Migration. The technologies currently working on are SQL Server, PowerShell, Oracle and MongoDB.
View all posts by Prashanth Jayaram
- Stairway to SQL essentials - April 7, 2021
- A quick overview of database audit in SQL - January 28, 2021
- How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server - January 20, 2021