
In this article, we will explore the details of what happens behind the scenes when a SQL delete statement is executed.
Introduction
SQL delete statement is one of the database manipulation commands (DML) that is used to remove rows from a table. When we execute a delete statement, many activities will be performed by the database engine but some factors affect the locking and performance behavior of SQL delete statements:
- Number of indexes in the table
- Poor indexed foreign keys
- Lock escalation mode
- Isolation levels
- Batch sizes of the delete statement
- Trigger(s)
- Temporal tables
For this reason, understanding what is going on backstage of the delete statement will take advantage to uncover the lock and performance issues about delete operations.
Effect of SQL delete statements on heap tables
The tables without a clustered index are called heap tables. The heap tables structure does not allow sorting stored rows in any particular order. On the other hand, when we delete a row from the clustered indexed table the empty pages will be deallocated and given to the database but this working mechanism works a bit different for the heap tables. Let’s look at the backstage of the delete operations for the heap tables with an example. At first, we will create a heap table and insert some rows into it.
|
1 2 3 4 5 6 7 8 |
CREATE TABLE HeapTable_Test ( ColId INT NOT NULL , Col1 CHAR(8000) NOT NULL DEFAULT ('Heap table test data') ); DECLARE @I AS INT=1 WHILE @I <=8000 BEGIN INSERT INTO HeapTable_Test VALUES(@I,DEFAULT) SET @I=@I+1 END |
After inserting some data into the table we will check how many pages are allocated by this table. We can use the sys.dm_db_database_page_allocations dynamic management function to return the data pages that are associated with a table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT page_id = allocated_page_page_id, index_id, page_type_desc ,page_free_space_percent,is_allocated , previous_page_page_id,next_page_page_id FROM sys.dm_db_database_page_allocations ( DB_ID(), OBJECT_ID(N'dbo.HeapTable_Test'), NULL, NULL, N'DETAILED' ) WHERE is_allocated = 1; |
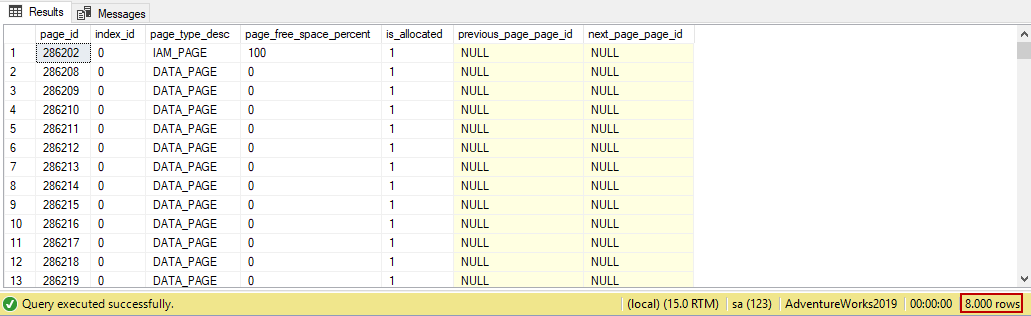
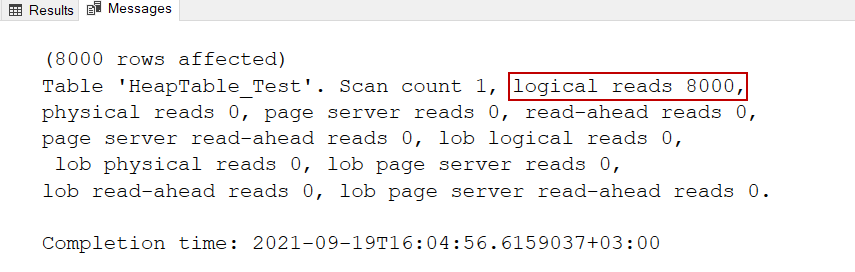
As we can see 8000 pages are directly allocated by this table. Such as, when we execute the following query the IO statistics report will show 8000 pages read operation are performed.
|
1 2 3 |
SET STATISTICS IO ON GO SELECT * FROM HeapTable_Test |
 Now, let’s delete 1/3 of our sample table and re-check how many pages are allocated after this delete operation.
Now, let’s delete 1/3 of our sample table and re-check how many pages are allocated after this delete operation.
|
1 |
DELETE HeapTable_Test WHERE ColId % 3 = 0; |
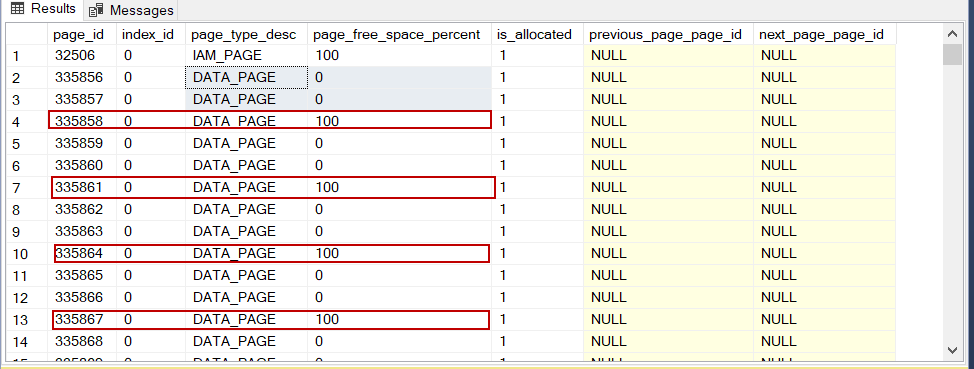
As we can see the deleted row’s pages are still allocated by the heap table. To resolve this issue, we can use the following methods:
- Using TABLOCK hint with the SQL delete statements
- Using ALTER TABLE “heap table name” REBUILD command
- Creating and dropping a clustered index on the heap table
Tip: Creating and dropping a clustered index is a very costly and inadvisable technique to remove the empty pages in the heap tables. In this technique, if the heap table contains the non-clustered index the following operations will be performed:
- Creating a clustered index will update all the non-clustered indexes pointers to the clustering key.
- Dropping a clustered index will update all the non-clustered indexes pointer to the heap table row identifier (RID)
SQL delete statement execution plan
When we execute a SQL delete statement the query optimizer generates an execution plan but this execution can be more complicated than we expected because of the triggers, foreign keys, temporal tables, etc. The following query deletes a row from the WorkOrder table. This table primary key column is referenced foreign key from the WorkOrderRouting table.
|
1 |
DELETE FROM Production.WorkOrder WHERE WorkOrderID = 1 |
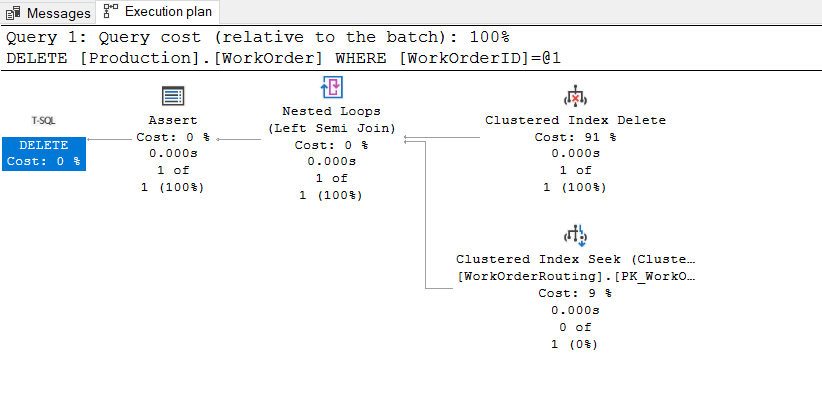
In the upper right corner of the execution plan, a clustered index delete operator is seen, and the task of this operator is to delete rows from a clustered index.
The second operator is the clustered index seek operator and this operator has been performed because there is a parent-child relationship between the WorkOrder and WorkOrderRouting table. Because of the parent-child relation, SQL Server needs to perform deleted row(s) existence check in the child table. The nested left semi-join returns all rows from the left input (deleted rows), whether or not a match exists in the right input.
The Assert Operator’s task is to verify the condition(s) and when it returns a value different than NULL, the query will return an error. For our example, the assert operator returns NULL because there is no row in the WorkOrderRouting table that matches the deleted row.
SQL delete statement execution plan
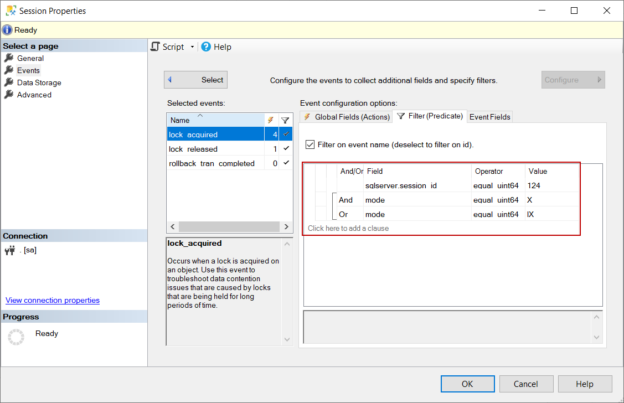
The lock mechanism is used by the database engine to ensure data integrity when multiple users want to access the same data at the same time. During a delete operation, the lock manager locks the necessary objects and the taken lock types depend on the isolation level of the transactions. Now, let’s analyze which objects will be locked during the execution of a sample SQL delete statement. Extended Event is a very beneficial tool to monitor the events in SQL Server and we will use this tool to monitor which objects are acquired lock during the execution of our sample query.
At first, we will create an event session and select the lock_acquired, lock_relased, and rollback_tran_completed events.
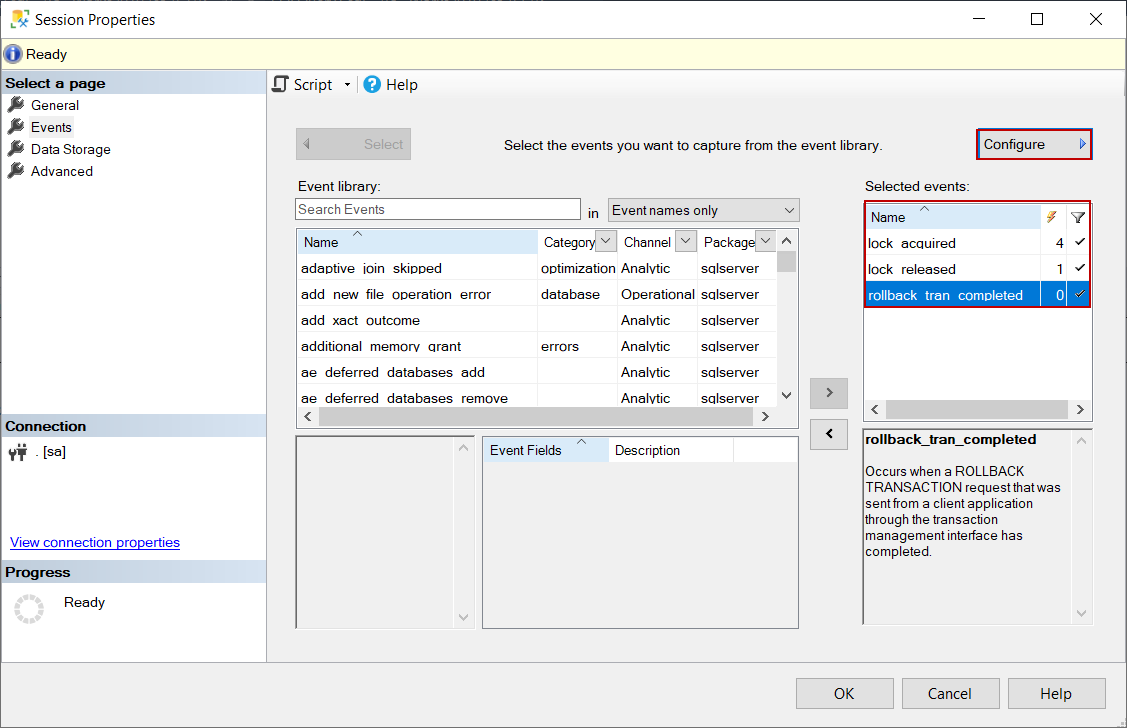
In the second step, we will click Configure button and filter the event data. For our session, we will only filter exclusive (X) and intend exclusive (IX) locks and also filter the session id.
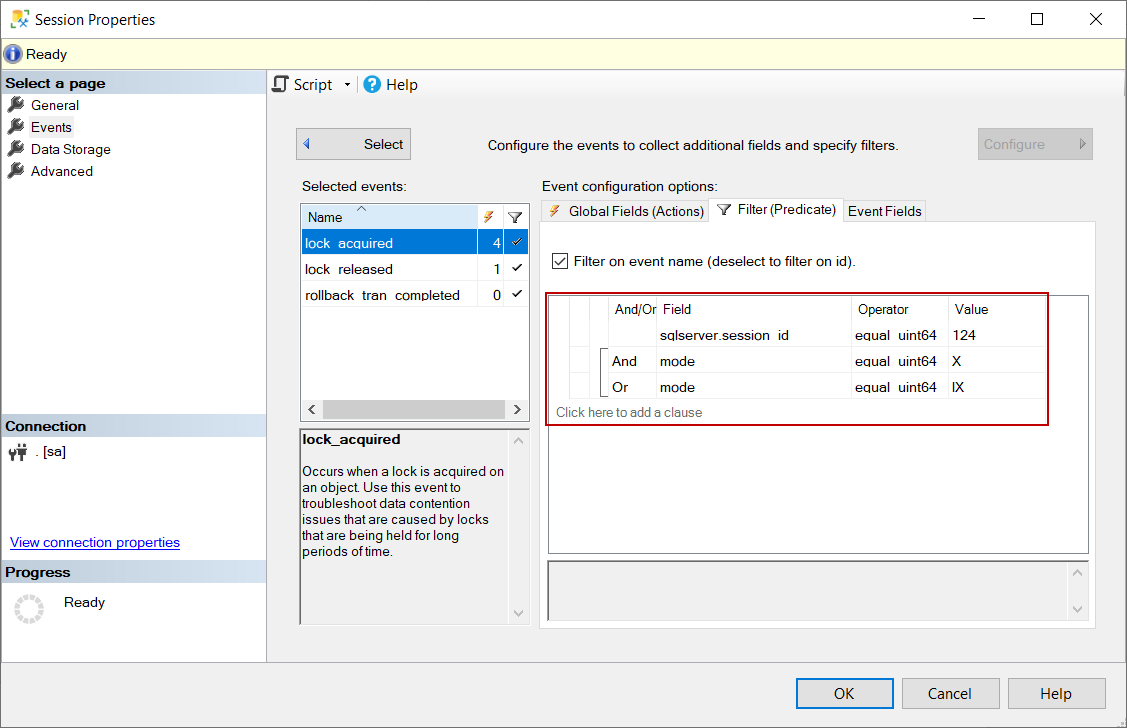
In the final step, we will configure the target storage where the event data will be stored. For this sample, we will choose event_file so the event data will be stored in a physical file.
After creating the session it will appear under the Extended Events sessions. Right-click on this event and select the Watch Live Data menu.
Now, we will execute the following query and try to analyze which objects will acquire locks during the execution of the delete statement.
|
1 |
DELETE FROM Production.WorkOrder where WorkOrderID =2 |
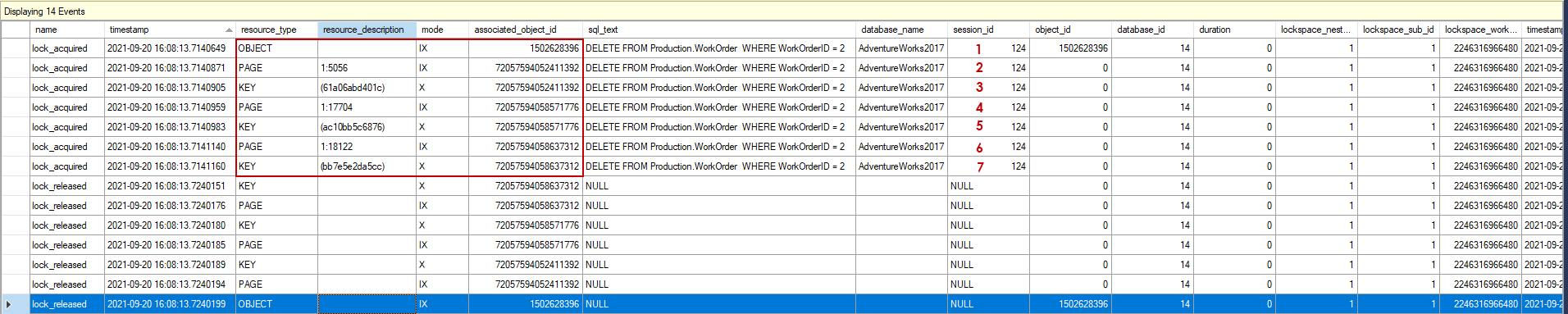
Now let’s understand the captured event data line by line.
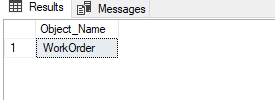
1- The resource_type column of the event data indicates the WorkOrder table. The WorkOrder table acquires an intent exclusive lock.
|
1 |
SELECT OBJECT_NAME(1502628396) As Object_Name |
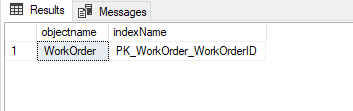
2- The clustered index page acquires an intent exclusive lock.
|
1 2 3 4 5 6 7 |
SELECT OBJECT_NAME(p.object_id) AS objectname, (SELECT name FROM sys.indexes AS i WHERE i.object_id = p.object_id AND i.index_id = p.index_id) AS indexName FROM sys.partitions AS p WHERE p.hobt_id = 72057594052411392; |
3- The clustered index row acquires an exclusive lock. At this point, we need to take into account one issue, after this event lock manager does not release the locks because of the non-clustered indexes. Due to the structure of non-clustered indexes, when a clustered index is modified in a table the non-clustered indexes must be updated. For this reason, the next 4 steps are performed by the SQL Server.
4- The non-clustered index (IX_WorkOrder_ScrapReasonID) page acquires an intent exclusive lock.
5- The non-clustered index (IX_WorkOrder_ScrapReasonID) page acquires an exclusive lock.
6- The non-clustered index (IX_WorkOrder_ProductID) page acquires an intent exclusive lock.
7- The non-clustered index (IX_WorkOrder_ProductID) page acquires an exclusive lock.
After all lock activities, all locks are released and lock_relased events identify this activity.
SQL delete statement and temporal tables
SQL Server system-versioned temporal tables were introduced in SQL Server 2016 and its purpose is to store the history of the modifications of a table. So, temporal tables a solution to:
- Data Auditing
- Enable to row-level restore
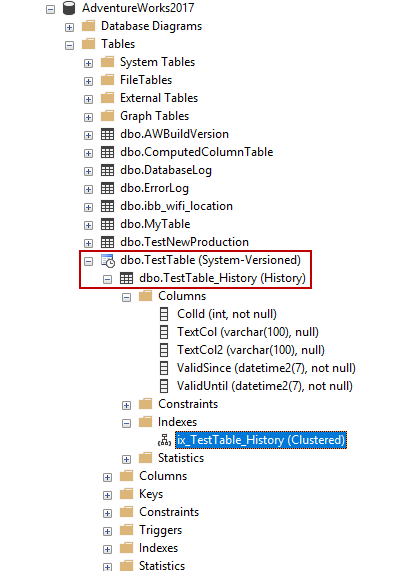
When we enable a temporal table to create, two tables will be created.
When we enable a table with a temporal table feature, two copies of the table will be created. The first one is the original table and the second one is the history table.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TABLE dbo.TestTable (ColId INT PRIMARY KEY IDENTITY(1,1) NOT NULL, TextCol VARCHAR(100), TextCol2 VARCHAR(100), ValidSince datetime2(7) GENERATED ALWAYS AS ROW START NOT NULL, ValidUntil datetime2(7) GENERATED ALWAYS AS ROW END NOT NULL, PERIOD FOR SYSTEM_TIME(ValidSince, ValidUntil) ) WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.TestTable_History)); GO INSERT INTO TestTable (TextCol,TextCol2) VALUES('Test Text' ,'Test Text2') |
In order to delete a row in the TestTable, we will execute the following query and analyze its execution plan.
|
1 |
DELETE FROM TestTable WHERE ColId=3 |
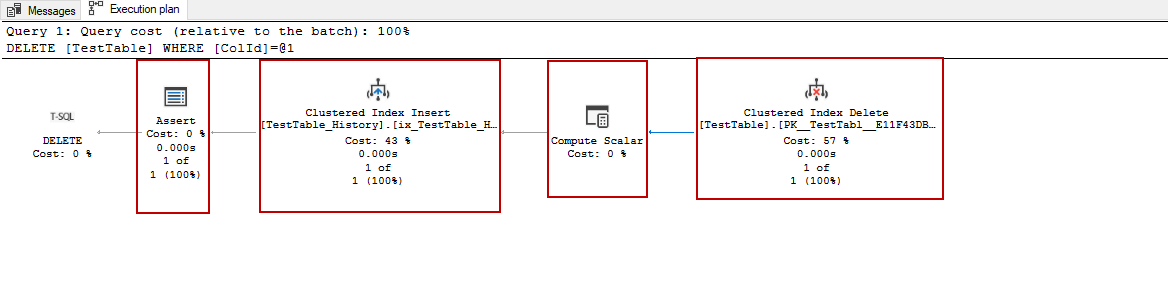
As shown in the above execution plan, three operators have been added because of the temporal table feature. Now we will explain all operators’ tasks one by one.
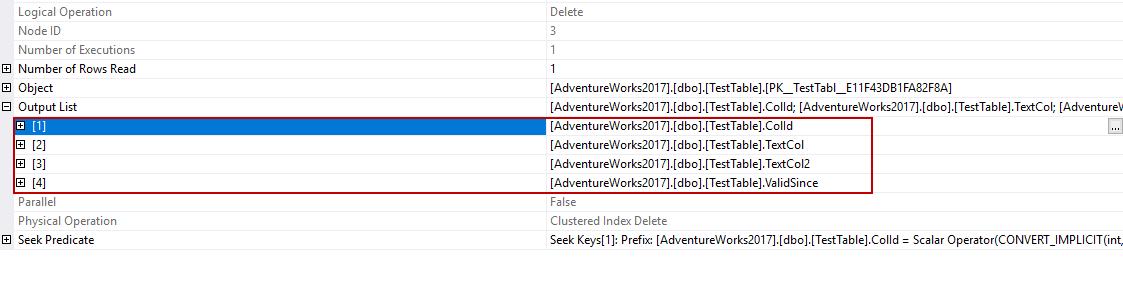
Clustered Index Delete operator indicates a row is deleted from the TestTable and passes the 4 columns to the next operator.
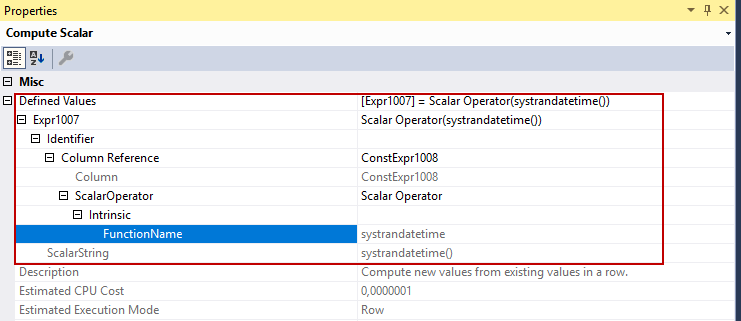
The Compute Scalar calls to systrandatetime() function to get ValidUntil value for the history table.
The Clustered Index Insert adds a new row to the temporal table history table.
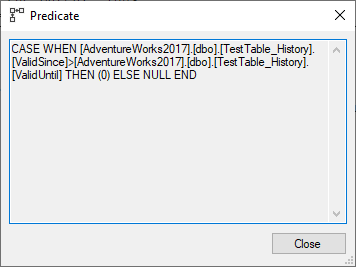
Assert operator validates a condition between ValidSince and ValidUntil columns.
Conclusion
In this article, we have made an exploration trip to understand what goes behind the scenes when we execute a SQL delete statement. On this journey, we have learned which activities are performed by the database engine when we execute a delete command.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023