

Introduction
This article is the newest addition to the article series of Azure Machine Learning which is Ensemble classifiers in Azure Machine Learning. During this article discussion, we have focused on data cleaning and feature selection techniques of Machine Learning. Further, we have discussed several machine learning tasks in Azure Machine Learning such as Classification, Clustering, Regression, Recommender System and Time Series Anomaly Detection. Further, we discussed AutoML features that are available with Azure Machine Learning Services. In the AutoML techniques, we have identified how to utilize Classification in AutoML. This article is an extension of the classification techniques that we discussed before.
What are Ensemble Classifiers in Azure Machine Learning
As you can see in the following figure, there are many two-class classification techniques that are available in Azure Machine Learning:

Every data modeler will have the question of how to select the best algorithms out of these available algorithms. In classification, we can use accuracy, Precision, Recall, F1 Measure, ROC curve in order to choose the best classification technique. This means that we will choose a single technique by comparing the evaluation parameters.
In ensemble Classifiers, we will look at how to perform predictions using multiple classification techniques so that it can produce better models with higher accuracy or they can avoid overfitting. This is equivalent to a patient that is referring multiple specialist doctors to diagnosis a disease rather than relies on one doctor.
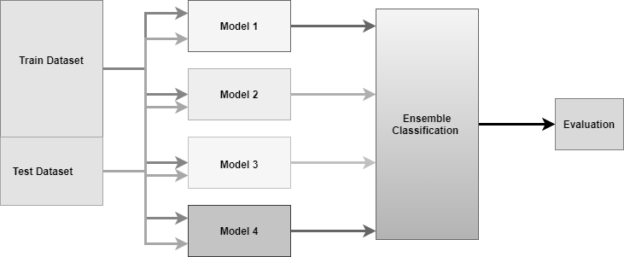
The following diagram shows how the ensemble classification is designed.

As you can see from the above diagram that multiple classifiers are combined in order to define an Ensemble classification.
Building the standard Classifier using Azure Machine Learning
Let us first build standard classification using Azure machine learning as we discussed in a previous article. Following is the experiment that was build to achieve the above said target and this experiment can be found at Classifiers with Two-Class Bayes Point Machine.

Let us quickly understand how the configurations are done to build the above classifier. First, we have selected the Adventureworks dataset which has been using during this article series. Then we have removed the unnecessary columns such as names and addresses by using the Select Columns in Dataset as those columns will not impact the prediction. Then the Salary and Age columns were normalized using the MinMax transformation method using the Normalize Data control. Next, the Edit Metadata control is used to indicate that CustomerKey should be removed from the classifier feature as the CustomerKey does not contribute to the classification but we need the Customer Key to join the dataset.
Then the data was split for 70/30 percentage in order to perform Training and Testing. Then the Train Model is used with the Two-Class classification technique. Then, the Score model and Evaluate model controls are used to measure the performance of the built models and the following are the evaluation parameters for the built models.

Configuring Ensemble Classifiers in Azure Machine Learning
Let us see how we can extend the standard classification to Ensemble Classifiers in Azure Machine Learning. Before we discuss the details of this configuration, you can view or download the experiment from Ensemble Classification
The following figure shows the complex layout of the Ensemble Classifiers in Azure Machine Learning.

Please note that due to the complex nature, the experiment layout may not be visible so you may have to view the experiment from the Azure AI Gallery.
Following are the Azure Machine Learning controls that we have used for Ensemble Classifiers in Azure Machine Learning.
|
Control |
Usage & Desription |
|
Dataset |
This control will start with the dataset and the adventure dataset will be used. |
|
Select Columns in Dataset |
This control will use to select columns from the existing dataset as all the attributes are not required for the next level. |
|
Normalize Data |
The MinMax normalization technique was used to normalize the annual income and age of the customers. |
|
Edit Metadata |
This control was used for two reasons.
|
|
Split Data |
Since this is a classification technique, we need two separate datasets to Train and Test the model. This control is used to split data for the Train/Test dataset with the 70/30 distribution. |
|
Two-Class Boosted Decision Tree |
These five classification algorithms are used for ensemble Classifiers in Azure Machine Learning. |
|
Two-Class Neural Network |
|
|
Two-Class Support Vector Machine |
|
|
Two-Class Logistic Regression |
|
|
Two-Class Decision Jungle |
|
|
Train Model |
Five controls of Train models were used to train the dataset from the above Classification techniques. |
|
Score Model |
Testing for each classification algorithms was done using the Score Model. |
|
Evaluate Model |
Evaluate model was used to evaluate accuracy for each classification technique. |
|
Join Data |
Join Data control is used to join the data streams that are streaming from five different classification training models. |
|
Apply SQL Transformation |
SQL Query is used to derive the classification of ensemble classification. This experiment has used two of these controls to define the classification for two different methods, voting and weighing. |
|
Execute Python Script |
A python script was written to calculate the different classification evaluation parameters such as accuracy, precision, recall and F1 measure for the ensemble Classification. |
Now let us look at how to create an experiment for Ensemble Classifiers in Azure Machine learning. In this experiment, five two-class classification techniques are used. One of the configurations (Two-Class Boosted Decision Tree) of five configurations is shown in the following figure.

The output of the above data stream after the Select Columns in Dataset is shown in the below figure.

CustomerKey is the key to identify the customer and the Bike buyer attribute is the actual value for the Bike buyer. DT_Labels indicate the prediction of bike buyers from the Decision Trees and DT_Probs indicate the probability of the prediction.
This was done for four other two-class classification techniques that are Two-Class Neural Network, Two-Class Support Vector Machine, Two-Class Logistic Regression and Two-Class Decision Jungle. After the prediction is completed for all the five classification techniques, all were joined together using the Join Data control and the output is following.

The next step is the application of Ensemble techniques after five classifications are done.
The first technique to define the Ensemble Classifiers is the voting technique. This means that out of the five classifications, the final classification will be dependent on the maximum votes. For example, out of five classifications, if three or more classifications are classified as Yes for the bike buyer, the ensemble classification would be yes.
The next technique is to define the ensemble classification depending on the weights for each technique. Different weights are assigned depending on the accuracy as shown in the below table.
|
Technique |
Accuracy |
Weightage |
|
Two-Class Boosted Decision Tree |
0.80 |
0.23 |
|
Two-Class Neural Network |
0.75 |
0.21 |
|
Two-Class Support Vector Machine |
0.62 |
0.17 |
|
Two-Class Logistic Regression |
0.65 |
0.18 |
|
Two-Class Decision Jungle |
0.76 |
0.21 |
The following image shows the last part of this experiment.

Both Apply SQL Transformation controls are used to convert existing values to ensemble classifiers. The first query is for the voting and the second query is for the weightage techniques.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT CustomerKey ,BikeBuyer ,(DT_Labels + NN_Labels + SVM_Labels + LR_Labels + DJ_Labels) / 5 AS Pred ,(DT_Prob + NN_Prob + SVM_Prob + LR_Prob + DJ_Prob) / 5 AS Prob FROM t1; SELECT CustomerKey ,BikeBuyer ,CASE WHEN ((DT_Labels * 0.23) + (NN_Labels * 0.21) + (SVM_Labels * 0.17) + (LR_Labels * 0.18) + (DJ_Labels * 0.21)) >= 0.5 THEN 1 ELSE 0 END AS Pred ,((DT_Prob * 0.23) + (NN_Prob * 0.21) + (SVM_Prob * 0.17) + (LR_Prob * .18) + (DJ_Prob * .21)) AS Prob FROM t1; |
After ensemble classification is defined the next option is the calculate different classification evaluation parameters in the below-listed python script.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import pandas as pd from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import f1_score def azureml_main(dataframe1 = None, dataframe2 = None): acc1 = accuracy_score(dataframe1["BikeBuyer"], dataframe1["Pred"]) pre1 = precision_score(dataframe1["BikeBuyer"], dataframe1["Pred"]) rec1 = recall_score(dataframe1["BikeBuyer"], dataframe1["Pred"]) f11 = f1_score(dataframe1["BikeBuyer"], dataframe1["Pred"]) acc2 = accuracy_score(dataframe1["BikeBuyer"], dataframe2["Pred"]) pre2 = precision_score(dataframe1["BikeBuyer"], dataframe2["Pred"]) rec2 = recall_score(dataframe1["BikeBuyer"], dataframe2["Pred"]) f12 = f1_score(dataframe1["BikeBuyer"], dataframe2["Pred"]) data = [["Voted",acc1,pre1,rec1,f11],["Weighted",acc2,pre2,rec2,f12]] df = pd.DataFrame(data,columns=['Type','Accuracy','Precision','Recall','F1']) return df, |
The following are the evaluation parameters for the different Ensemble Classification techniques.

Conclusion
Ensemble Classifiers in Azure Machine Learning is an improved technique of classification where it combines multiple classifications. This technique will introduce higher accuracy and avoid overfitting in classification. This article has introduced techniques of ensemble classifiers which are voted and weighted.
Table of contents


View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021