In this article let us review different ways to create a SQL foreign key, rules on updates and deletes, enabling foreign key constraints, disabling foreign key constraints and not for replication in foreign keys.
Read more »
In this article let us review different ways to create a SQL foreign key, rules on updates and deletes, enabling foreign key constraints, disabling foreign key constraints and not for replication in foreign keys.
Read more »
SQL Server FILETABLE provides benefits over SQL FILESTREAM available from SQL Server 2012. We can manage unstructured objects in the file system using SQL Server. It stores metadata in particular fixed schema tables and columns. It provides compatibility between an object in SQL Server table and Windows.
Read more »
Nested Triggers in SQL Server are actions that automatically execute when a certain database operation is performed, for example, INSERT, DROP, UPDATE etc.
Read more »
SQL Server FILETABLE is a next generation feature of SQL FILESTREAM. We can use it to store unstructured objects into a hierarchal directory structure. SQL Server manages SQL FILETABLE using computed columns and interacts with the OS using extended functions. We can manage SQL FILETABLEs similar to a relational table.
Read more »
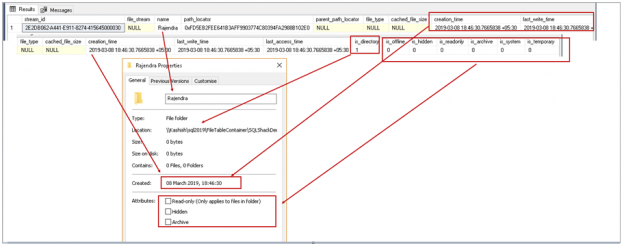
This SQL Server FILETABLE article is the continuation of the SQL Server FILESTREAM series. The SQL Server FILESTREAM feature is available from SQL Server 2008 on. We can store unstructured objects into FILESTREAM container using this feature. SQL Server 2012 introduced a new feature, SQL Server FILETABLE, built on top of the SQL FILESTREAM feature. In this article, we will explore the SQL FILETABLE feature overview and its comparison with SQL FILESTREAM.
Read more »
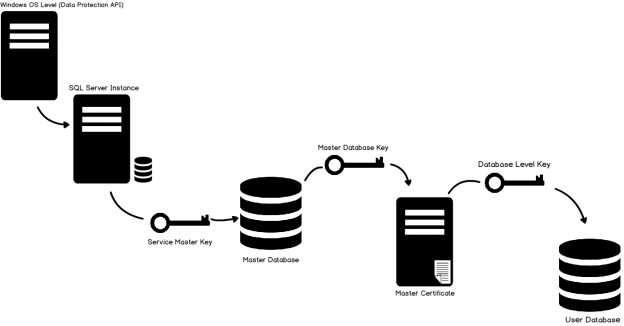
This article is the continuation of the SQL FILESTREAM series.
Read more »
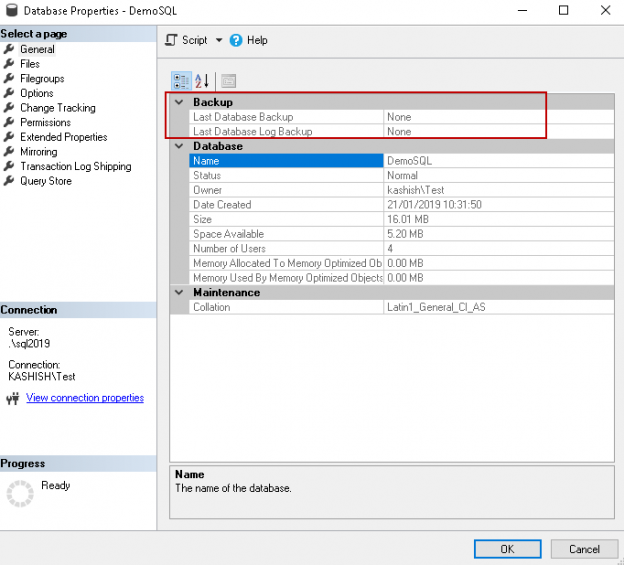
In the continuation of our SQL FILESTREAM article series, we’ll be covering transaction log backups
In SQL Server, we take transaction log backups regularly to have a point-in-time recovery of a database. It is essential to define the backup policy with the combination of full, differential and transaction log backups. A standard configuration of backups for large databases in the production database environment is as follows.
Read more »

SQL Server trace flags are configuration handles that can be used to enable or disable a specific SQL Server characteristic or to change a specific SQL Server behavior. It is an advanced SQL Server mechanism that allows drilling down into a hidden and advanced SQL Server features to ensure more effective troubleshooting and debugging, advanced monitoring of SQL Server behavior and diagnosing of performance issues, or turning on and off various SQL Server features

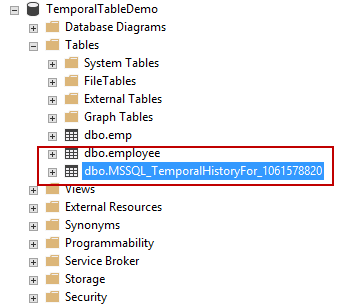
Temporal tables have been a feature of SQL Server since version 2016. SQL Server professionals have historically had several options to track data change events. The evolution of the data tracking mechanism started with Change tracking (CT), Change Data Capture (CDC) and now Temporal Tables.
Read more »
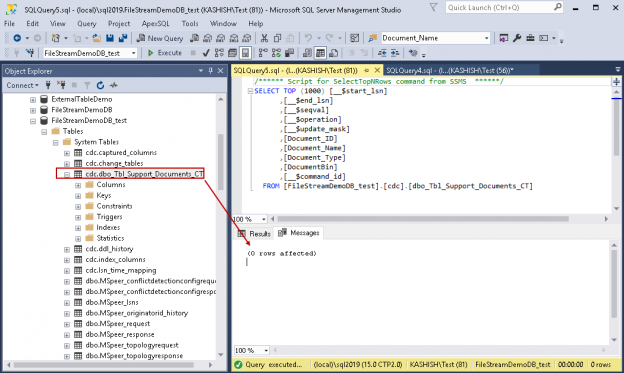
Sometimes we require tracking data change activity (Insert, update and deletes) in SQL Server tables. SQL Server 2008 introduced Change Data Capture (CDC) to track these changes in the user-defined tables. SQL Server tracks the defined table with a mirrored table with same column structure; however; it adds additional metadata fields to track these changes. We can use table-valued function to access this changed data.
Read more »
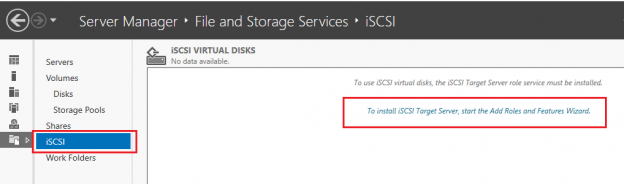
In this article, we will continue our journey to configuring a SQL Server AlwaysOn High availability configuration and failover nodes, by setting up iSCSI including an iSCSI initiator, setting up disk drives on notes, configuring our Quorum and finally installing the SQL Server cluster.
Read more »
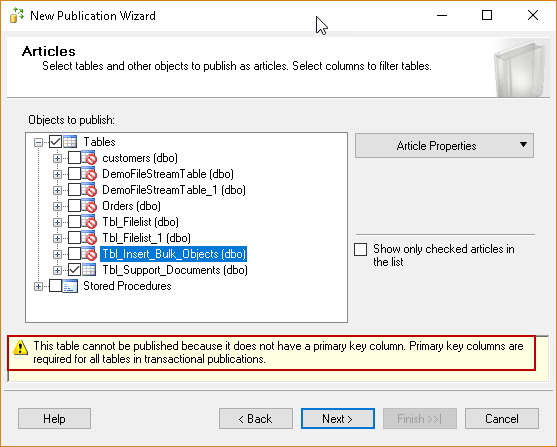
In the previous articles in this series (see TOC at bottom), we wrote about the various feature of the SQL Server FILESTREAM. In SQL Server, we use replication to replicate the articles to the destination server. Consider a scenario in which we have the FILESTREAM database in our environment. We would also have the requirement to configure this database for SQL Server replication.
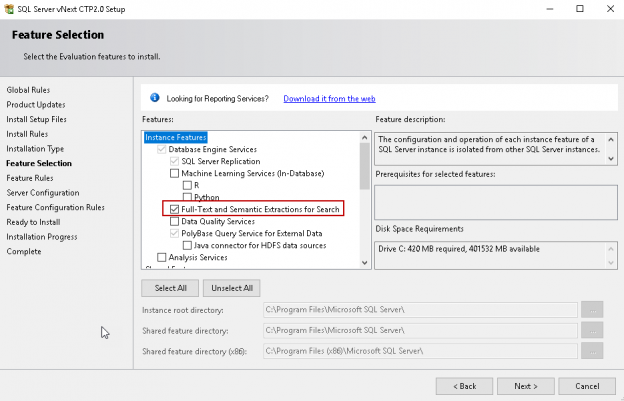
In this article, the latest in our series on the SQL FILESTREAM feature, we are going to look at the synergy and interoperability with SQL Server Full Text search, another powerful SQL Server feature
Read more »
In this series of articles on SQL Server FILESTREAM (see TOC at bottom), we explored various ways to store unstructured data in the file system with the metadata in SQL Server tables. If we have a large number of objects in the file system, it is advisable to use the fast disk for storage purpose. It is faster and provides better IO in comparison with the traditional file system.
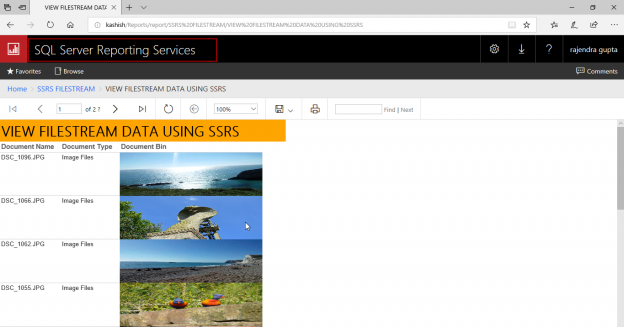
This article will cover corruption and recovery scenarios in the context of SQL Server FILESTREAM including missing data, incompatible files types, DBCC checks, orphan files and garbage collection
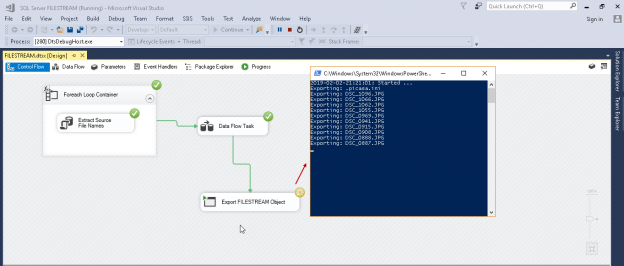
SQL Server FILESTREAM stores objects into the file system and applications can retrieve these objects to benefit from the IO streaming capability of the Windows OS. In my earlier articles we used the SSIS package to import and export data from the a FILESTREAM table
Read more »
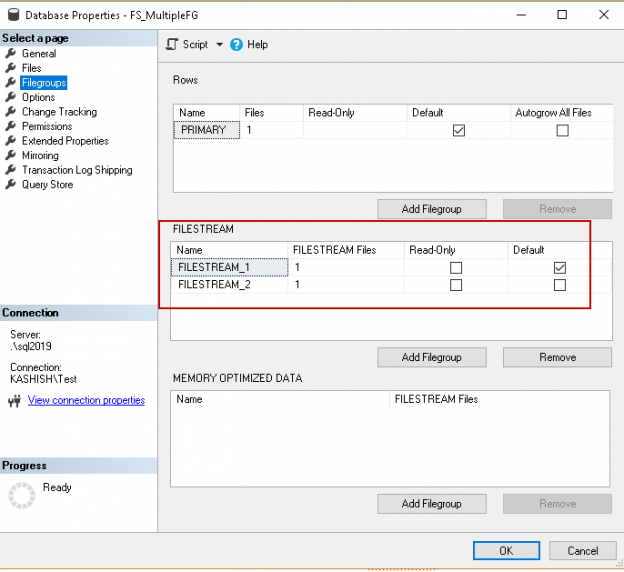
In this series of the SQL Server FILESTREAM (see TOC at bottom), We have gone through various aspects of this feature to store large size objects into the file systems.
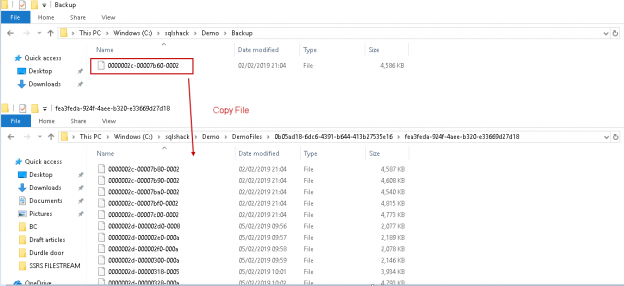
We have been exploring the SQL Server FILESTREAM feature in this ongoing series of articles. In this previous article, Managing data with SQL Server FILESTREAM tables, we wrote about inserting FILESTREAM data into a FILESTREAM table and performing DML activities on it. Suppose we have created the FILESTREAM database in our instance and now we want to insert a large number of files into a FILESTREAM container. It is easy to write out the insert queries for a small number of files, but if the numbers of files were in huge quantity, it would be difficult to write out the code and insert data into it. It is difficult to manage such kind of requests regularly in the environment.
Read more »
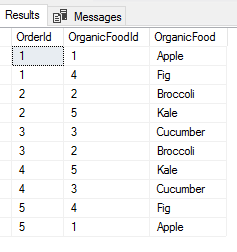
Since we know that the SQL CTE (common table expression) offers us a tool to group and order data in SQL Server, we will see an applied example of using common table expressions to solve the business challenge of re-basing identifier columns. We can think of the business problem like the following: we have a table of foods that we sell with a unique identifier integer associated with the food. As we sell new foods, we insert the food in our list. After a few years, we observe that many of our queries involve the foods grouped alphabetically. However, our food list is just a list of foods that we add to as needed without any grouping. Rather than re-group or re-order through queries using a SQL CTE or subquery, we want to permanently update the identifier.
Read more »
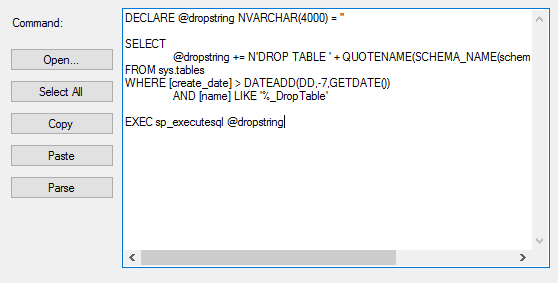
In this article, the latest in our series on Common table expressions, we’ll review CTE SQL Deletes including analyzing the operation before the delete, actually removing the data as well as organizing and ordering the deletes with CTEs.
Read more »
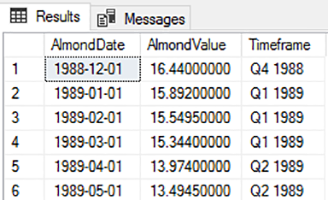
In CTEs in SQL Server; Querying Common Table Expressions the first article of this series, we looked at creating common table expressions for select statements to help us organize data. This can be useful in aggregates, partition-based selections from within data, or for calculations where ordering data within groups can help us. We also saw that we weren’t required to explicitly create a table an insert data, but we did have to ensure that we had names for each of the columns along with the names being unique. Now, we’ll use our select statements for inserts and updates.
Read more »
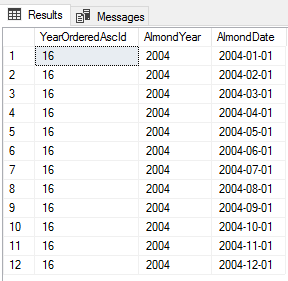
Common table expressions (CTEs) in SQL Server provide us with a tool that allows us to design and organize queries in ways that may allow faster development, troubleshooting, and improve performance. In the first part of this series, we’ll look at querying against these with a practice data set. From examples of wrapped query checks to organization of data to multiple structured queries, we’ll see how many options we have with this tool and where it may be useful when we query data.
Read more »
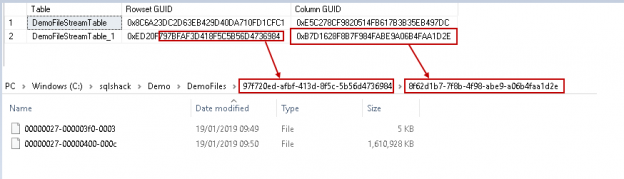
In the article FILESTREAM in SQL Server, we provided a SQL Server FILESTREAM overview with a focus on internal functionality. In this article, we will cover various additional aspects of the FILESTREAM feature.
Read more »
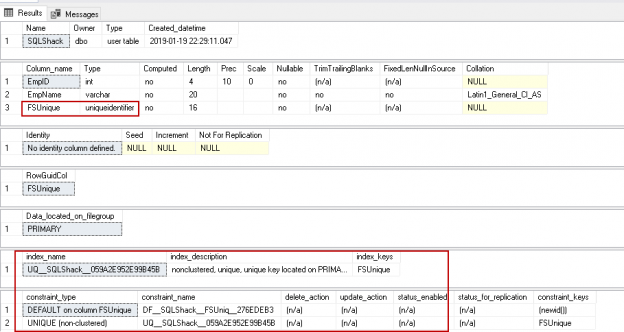
SQL Server FILESTREAM is a great feature to store unstructured data into the file system with the metadata into
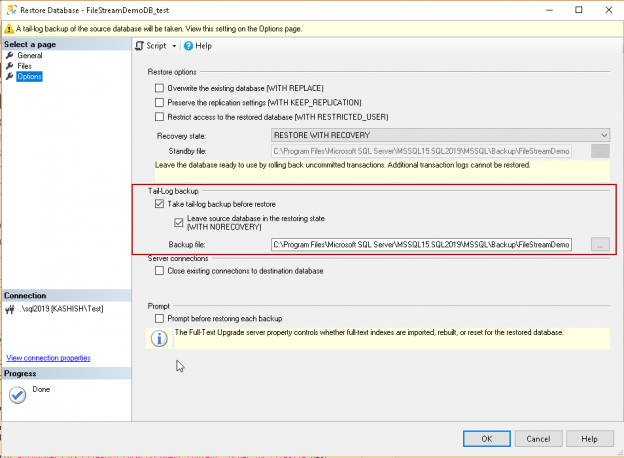
The SQL Server FILESTREAM feature is available from SQL Server 2008 onwards. This feature allows the large BLOB objects to store into the file system and keeps metadata in the database tables. Before you go further in this article, let us have a quick overview of the FILESTREAM series articles.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy