I would like to share one curios case that I recently came across.
Long story short:
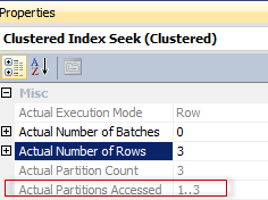
This bug may lead to incorrect results if you use a partitioned table and the FORCESCAN hint.
Bug
Consider the following example, let’s keep it simple.
Read more »
I would like to share one curios case that I recently came across.
Long story short:
This bug may lead to incorrect results if you use a partitioned table and the FORCESCAN hint.
Consider the following example, let’s keep it simple.
Read more »
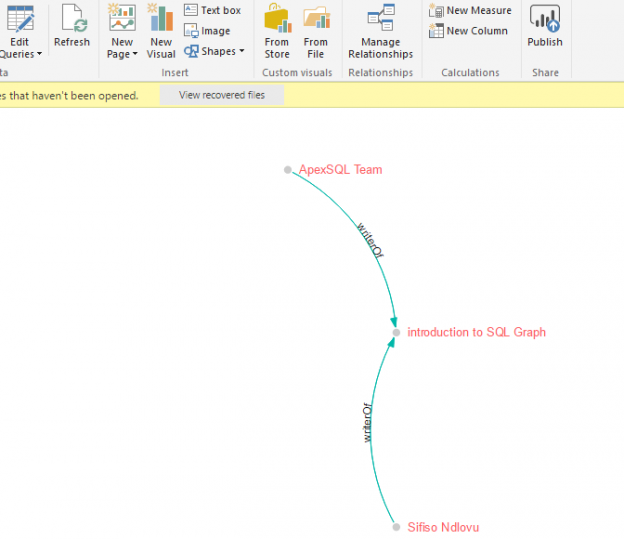
Just like in Santa’s Bag of Goodies, every release of SQL Server often has something for everyone – be it enhancements to DMVs for the DBAs, new functions for T-SQL developers or new SSIS control tasks for ETL developers. Likewise, the ability to effectively support many-to-many relationships type in SQL Graph has ensured that there is indeed something in it for the data warehouse developers in SQL Server 2017. In this article, we take you through the challenges of modelling many-to-many relationships in relational data warehouse environments and later demonstrate how data warehouse teams can take advantage of the many-to-many relationship feature in SQL Server 2017 Graph Database to effectively model and support their data warehouse solutions.
Read more »
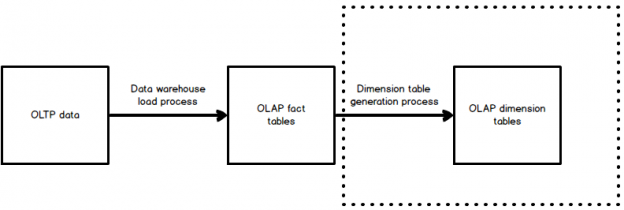
When building reporting structures, we typically have the need to build fact and dimension tables to support the apps that will consume this data. Sometimes we need to generate large numbers of dimension tables to support application needs, such as in Tableau, Entity Framework, or Power BI.
Creating this schema by hand is time-consuming and error-prone. Automating it can be a way to improve predictability, maintainability, and save a ton of time in the process!
Read more »
Dynamic management views (DMVs) and dynamic management functions (DMFs) are system views and system functions that return metadata of the system state. On querying the related system objects, database administrators can understand the internals of SQL Server. It allows us to monitor the performance of the SQL Server instance, and diagnose issues with it.
SQL Server 2017 ships with a number of new and enhanced dynamic management views and dynamic management functions that will help DBAs monitor the health and performance of SQL Server instances. A few existing DMV’s such as sys.dm_os_sys_info and sys.dm_db_file_space_usage have been enhanced. Some have also been newly built and available only for SQL Server 2017.
Read more »
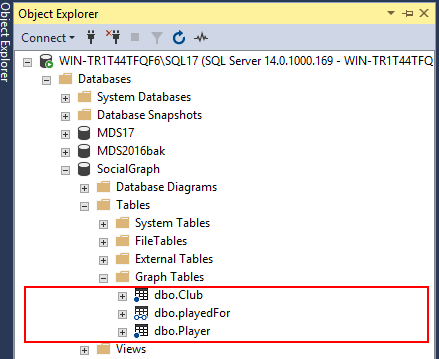
A few years ago, one common business case I came across in my professional career that required modelling of data into a many-to-many entity relationship type was the representation of a consultants and their projects. Such a business case became a many-to-many entity relationship type because whilst each project can be undertaken by several consultants, consultants can in turn be involved in many different projects. When it came to storing such data in a relational database engine, it meant that we had to make use of bridging tables and also make use of several self-joins to successfully query the data.
Read more »
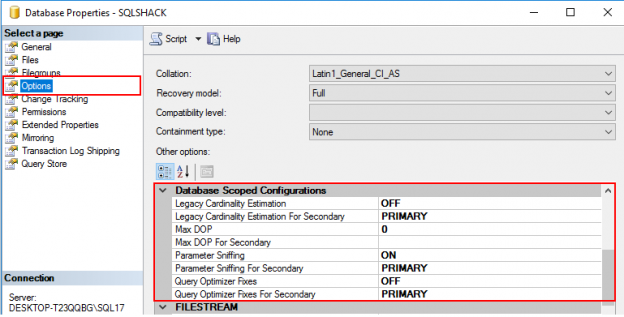
Every data warehouse developer is likely to appreciate the significance of having surrogate keys as part of derived fields in your facts and dimension tables. Surrogate keys make it easy to define constraints, create and maintain indexes, as well as define relationships between tables. This is where the Identity property in SQL Server becomes very useful because it allows us to automatically generate and increment our surrogate key values in data warehouse tables. Unfortunately, the generating and incrementing of surrogate keys in versions of SQL Server prior to SQL Server 2017 was at times challenging and inconsistent by causing huge gaps between identity values. In this article, we take a look at one improvement made in SQL Server 2017 to reduce the creation of gaps between identity values.
Read more »
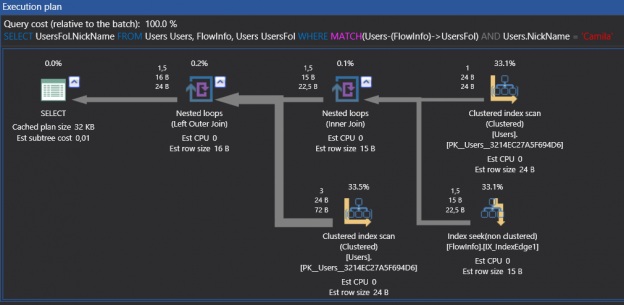
Graph database
A graph database is a type of database whose concept is based on nodes and edges.
Graph databases are based on graph theory (a graph is a diagram of points and lines connected to the points). Nodes represent data or entity and edges represent connections between nodes. Edges own properties that can be related to nodes. This capability allows us to show more complex and deep interactions between our data. Now, to explain this interaction we will show it in a simple diagram
Read more »
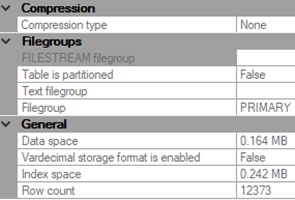
We recently inherited a database environment where we’re facing significant data growth with limits on the sizes we can allow our databases to grow. Since we maintain multiple development, QA and production environments and these environments must be sized appropriately. We set a few standards about tables that exceed certain sizes – rows, data or both, or have certain growth patterns and our standards force compression at thresholds we set for our different environments (including using page, row, or clustered columnstore index compression) We’re looking for how we can get information about data and compression in tables and options we have so that we can quickly determine candidates that don’t currently match our best practices design we’ve set for our environments.
Read more »
The graph database is a critically important new technology for data professionals. As a database technologist always keen to know and understand the latest innovations happening around the cutting edge or next-generation technologies, and after working with traditional relational database systems and NoSQL databases, I feel that the graph database has a significant role to play in the growth of an organization. Not only are traditional database systems generally inefficient in displaying complex hierarchical data, but even NoSQL lags a little. We usually see a degradation in performance with the number of levels of relationship and database size. Also, depending on the relationship, the number of joins may increase as well.
Read more »
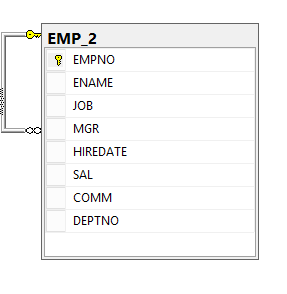
In the previous article Commonly used SQL Server Constraints: NOT NULL, UNIQUE and PRIMARY KEY, we described, in detail, the first three types of the SQL Server constraints; NOT NULL, UNIQUE and PRIMARY KEY. In this article, we will discuss the other three constraints; FOREIGN KEY, CHECK and DEFAULT by describing each one briefly and providing practical examples.
Read more »
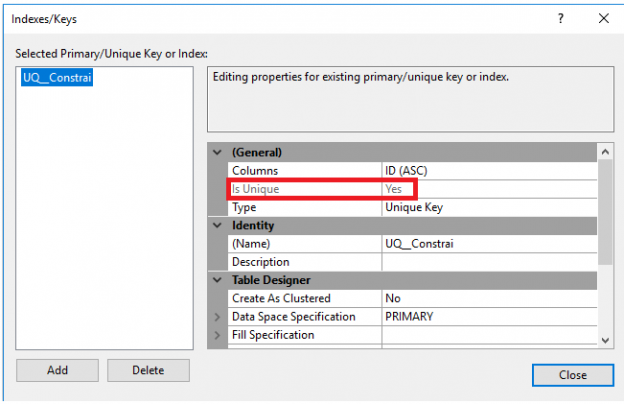
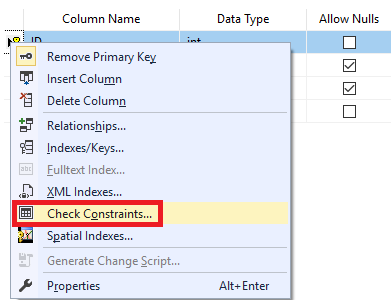
This article explains the SQL NOT NULL, Unique and SQL Primary Key constraints in SQL Server with examples.
Constraints in SQL Server are predefined rules and restrictions that are enforced in a single column or multiple columns, regarding the values allowed in the columns, to maintain the integrity, accuracy, and reliability of that column’s data. In other words, if the inserted data meets the constraint rule, it will be inserted successfully. If the inserted data violates the defined constraint, the insert operation will be aborted.
Read more »
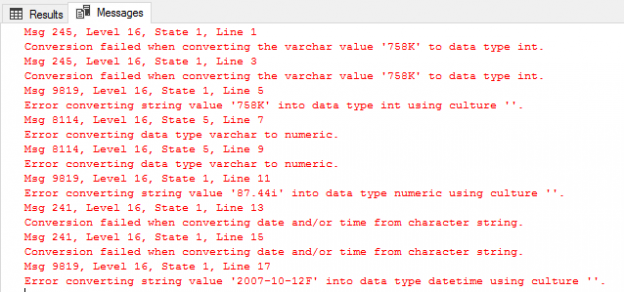
When you define SQL Server database tables, local variables, expressions or parameters, you should specify what kind of data will be stored in those objects, such as text data, numbers, money or dates. This attribute is called the SQL Server Data Type. SQL Server provides us with a big library of system data types that define all types of data that can be used with SQL Server, from which we can choose the SQL Server data type that is suitable for the data we will store in that object. You can also define your own customized user defined data type using T-SQL script. SQL Server data types can be categorized into seven main categories:
Read more »
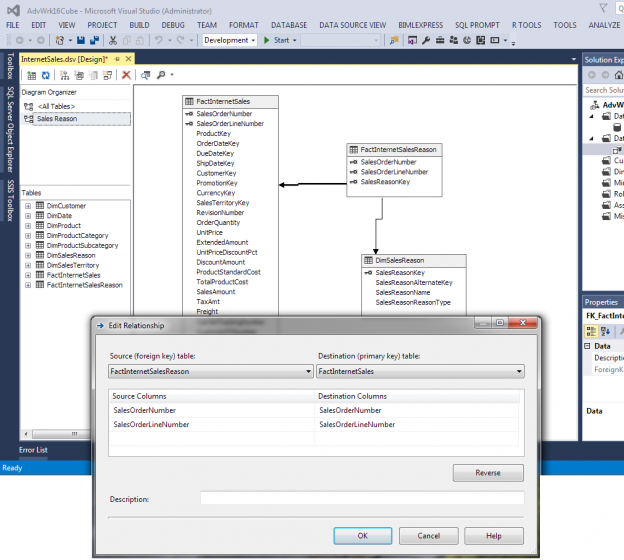
The Multidimensional Cube option of Analysis Services has handled many-to-many relationships with ease for many versions before 2016. The Tabular had a work around using DAX formulas until the release of SQL Server 2016. There are still some limitations to many-to many in Tabular but of course, there are some “tricks” to overcome the limitations. But, the many-to-many relationship will be in businesses data for many years to come. A solution has to be provided when it comes to Analysis Service databases.
Read more »
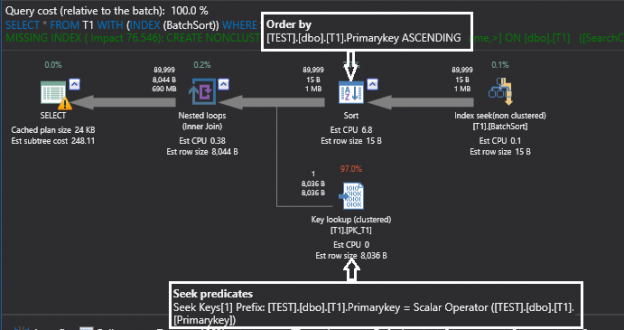
In SQL Server, it`s not always required to fully understand the internal structure, especially for performance and optimization, if the database design is good, because SQL Server is a very powerful Relational Database and, as such, it has many inbuilt optimization processes which assure a response to the users as fast as possible. But it is always beneficial for the SQL Server developers and administrators to understand the internal structure of the SQL Server so that they can understand and fix the problems that slowed the response of the Database.
Read more »
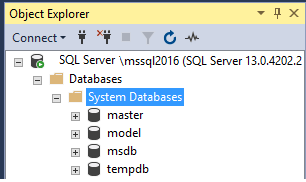
This is my fourth article about SQL Server system databases. In previous articles of the series, I wrote about the tempdb database, the master database and the msdb database.
Read more »
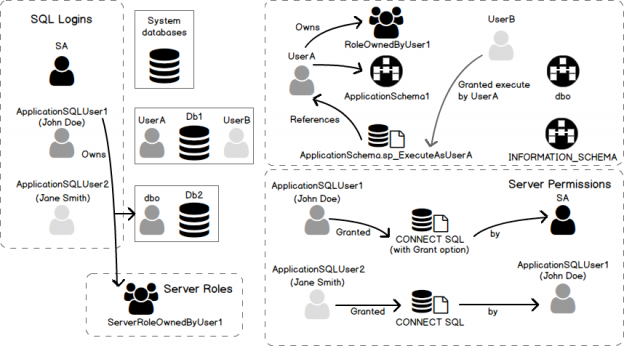
Sometimes, we need to drop a SQL Server Login because we gave an access to a person who left, this login was used by an application that has been decommissioned for example.
Read more »
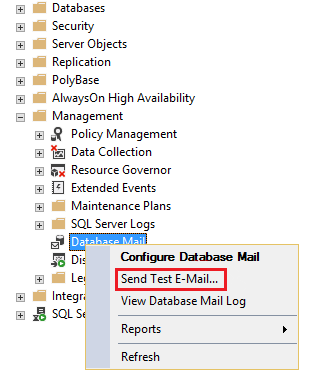
This article is the third I am writing about Microsoft SQL system databases.
In this article, I will focus only on the msdb database, one of the four system databases that exist in any MSSQL instance:
Read more »
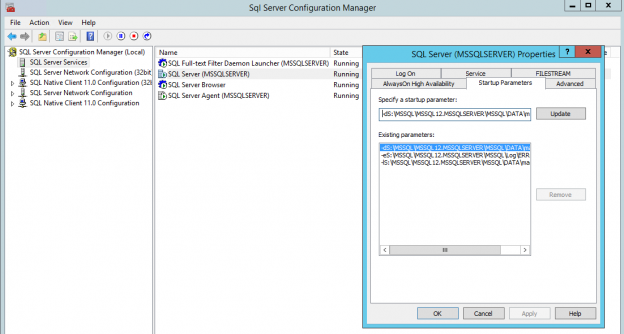
There are at least 4 system databases in any SQL Server instance as shown by the following SQL Server Management Studio (SSMS) screen capture:
Read more »
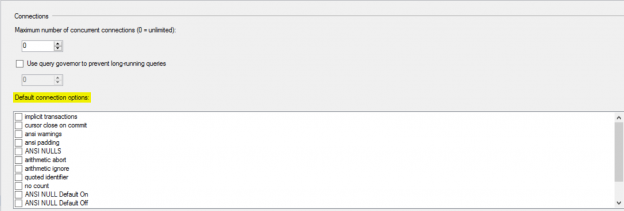
In the previous article of this two-part series SQL Server SET Options that Affect the Query Result – SET ANSI_NULLS, SET ANSI_PADDING, SET ANSI_WARNINGS and SET ARITHABORT, we described the first four SQL Server SET options and showed practically how setting these options ON and OFF affects the SQL Server Database Engine behavior and the query result. To recall, SQL Server SET options are a group of session-level options that control how the SQL Server behaves on the database session level, and the option value can be changed using the SET T-SQL command for the current session that you execute the SET command on.
In this article, we will describe another five SET options and see how turning it ON and OFF will change the SQL Server behavior and the query result.
Read more »
SQL Server provides us with a number of options to control SQL Server behavior on the connection level. These session-level options are configured using the SET T-SQL command that change the option value for the session on which the SET command is executed. Changing the default value of these session-level configuration affects how the session queries will be executed affecting the query result. The performed change on a session-level option will be applied to the current session until its value is reset or until the current user’s session is terminated.
Read more »
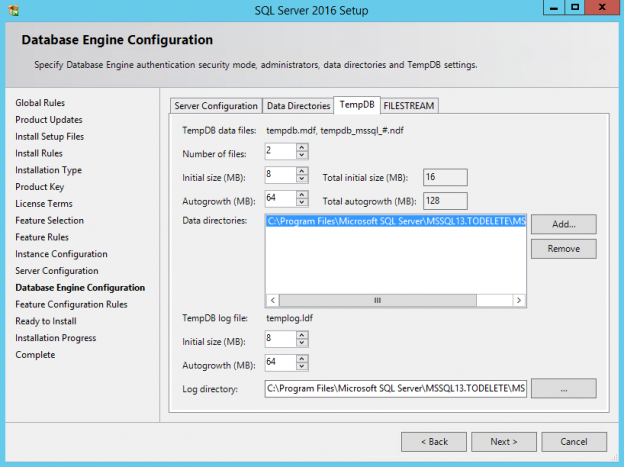
tempdb is one of the 4 system databases that exists in all SQL Server instances. The other databases are master, model and msdb. In case of using Replication, a fifth system database named distribution will also exist. You can find all existing system databases in SQL Server Management Studio (SSMS) under the Databases / System Databases folder:
Read more »
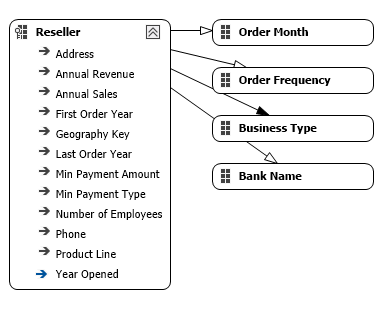
We have already discussed quite some design tips for building Analysis Services (SSAS) Multidimensional cubes and dimensions:
Read more »
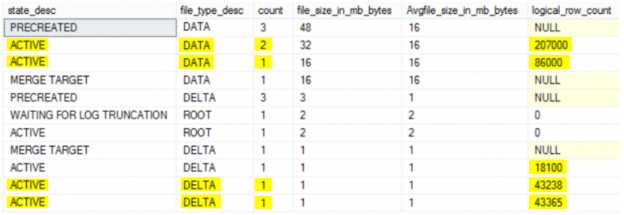
The SQL Server Database Engine stores data changes in the buffer pool, in memory, before applying it to the database files, for I/O performance reasons. After that, a special kind of background process, called Checkpoint, will write all of these not reflected pages, also known as Dirty Pages, to the database data and log files periodically.
Read more »
Identifying the SQL Server database state and how a database can be moved between these different states is considered an important aspect of SQL Server database administration . A good understanding of this will help us in troubleshooting and fixing many database problems and issues.
Read more »
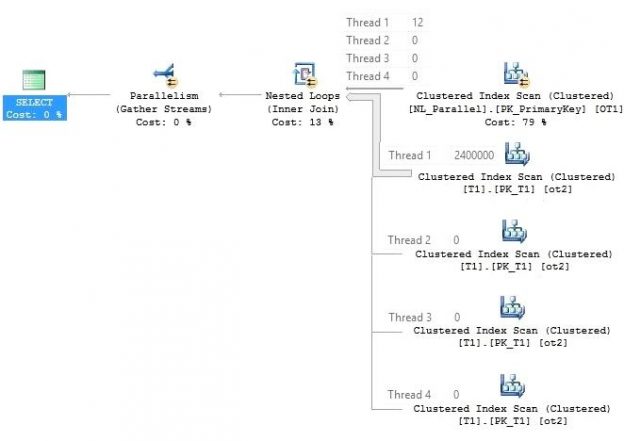
This article is the second part of the Nested Loop Join Series. In the first part, Introduction of Nested Loop Join, we gave a brief introduction to Native, Indexed and Temporary Index Nested Loop Joins along with CPU cost details.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy