Database design and Logical Asseveration play a vital role in database performance and SQL Query optimization. Both have different parameters to make your database and the query accurate.
Read more »
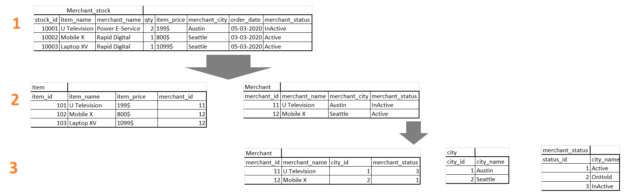
Database design and Logical Asseveration play a vital role in database performance and SQL Query optimization. Both have different parameters to make your database and the query accurate.
Read more »
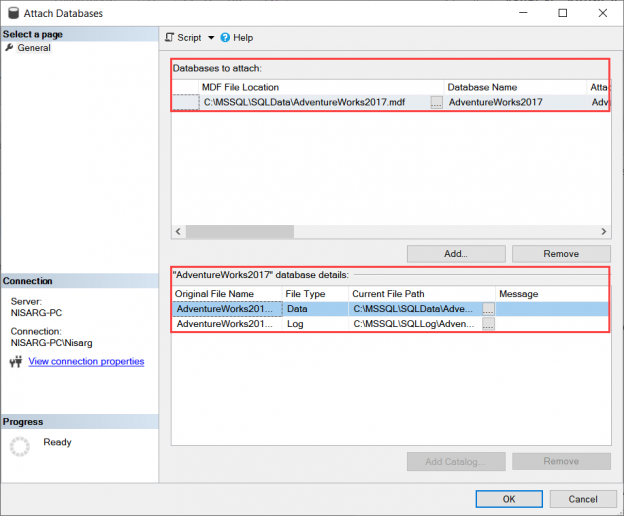
This article demonstrates different methods to attach SQL Server MDF files. First, let me explain about the database files.
Read more »
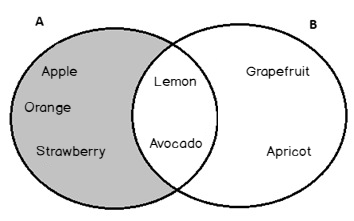
In this article, we will describe the relation between the Set Theory and SQL Server Set Operations
Read more »
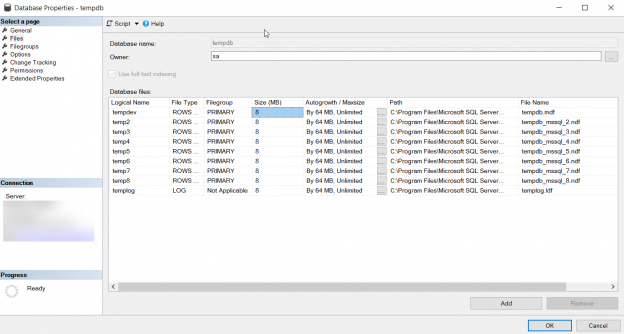
In this article, we will discuss the best practices that should be followed in order to keep the TempDB database in a healthy state and prevent any unexpected growth of the database, in addition to the procedure that can be followed to detect this unexpected growth once occurred.
Read more »
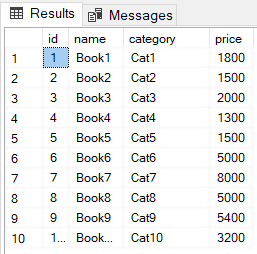
The SQL CREATE INDEX statement is used to create clustered as well as non-clustered indexes in SQL Server. An index in a database is very similar to an index in a book. A book index may have a list of topics discussed in a book in alphabetical order. Therefore, if you want to search for any specific topic, you simply go to the index, find the page number of the topic, and go to that specific page number. Database indexes are similar and come handy. Particularly, if you have a huge number of records in your database, indexes can speed up the query execution process. There are two major types of indexes in SQL Server: clustered indexes and non-clustered indexes.
Read more »
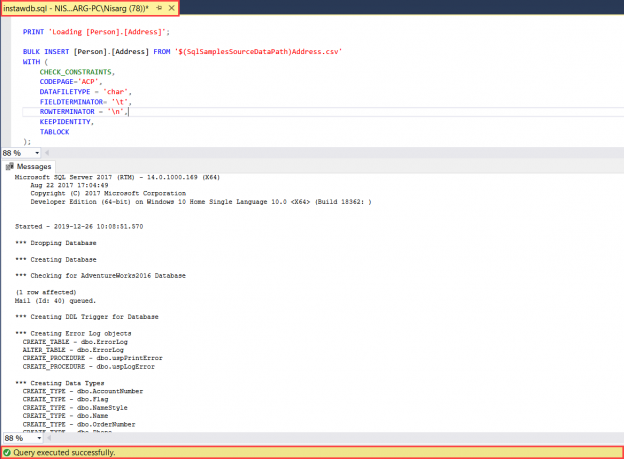
This article explains the process of installing the AdventureWorks2016 and AdventureWorksDW2016 sample database on a stand-alone instance of SQL Server and Azure SQL Server. The sample databases were published by Microsoft to demonstrate how to design a database using SQL Server. Microsoft has also published another lightweight database named AdventureworksLT, which can be used as a sample database on Azure SQL Server.
Read more »
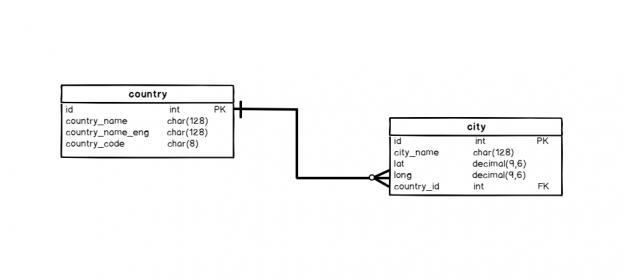
Welcome to the first article in the Learn SQL series. In this part, we’ll start with two essential commands in SQL: Create Database and Create Table. While both are pretty simple, they should be used first before you start working on anything with data (unless you use some template database).
Read more »
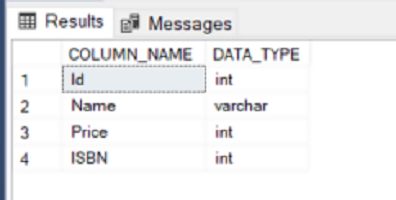
This article explains SQL DDL commands in Microsoft SQL Server using a few simple examples.
Read more »
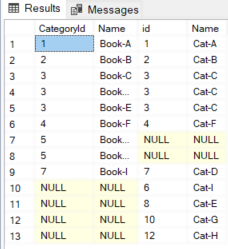
In this article, you will see how to use different types of SQL JOIN tables queries to select data from two or more related tables.
Read more »
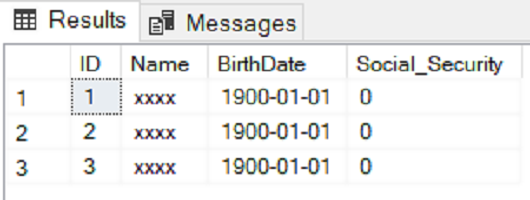
Security has been one of the prime concerns of database developers since the inception of database management systems. Various data protection schemes have been introduced to provide secure access to sensitive data.
Read more »
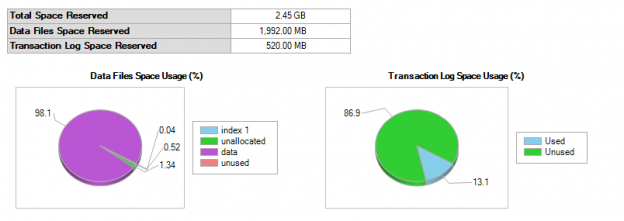
In this article, we will explore SQL Server ALTER TABLE ADD Column statements to add column(s) to an existing table. We will also understand the impact of adding a column with a default value and adding and updating the column with a value later on larger tables.
Read more »
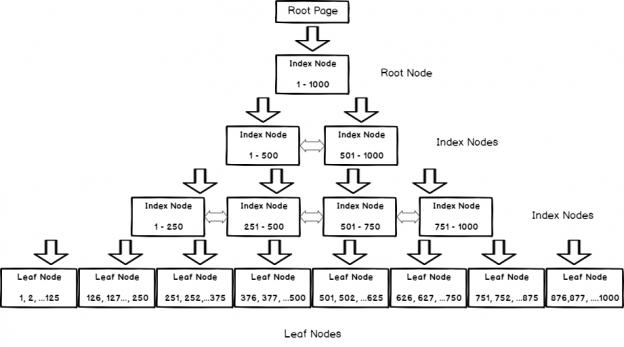
There are few topics so widely misunderstood and that generates such frequent bad advice as that of the decision of how to index a table. Specifically, the decision to use a heap over a clustered index is one where misinformation spreads quite frequently.
Read more »
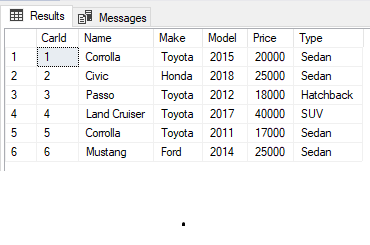
Nested Triggers in SQL Server are actions that automatically execute when a certain database operation is performed, for example, INSERT, DROP, UPDATE etc.
Read more »

SQL Server trace flags are configuration handles that can be used to enable or disable a specific SQL Server characteristic or to change a specific SQL Server behavior. It is an advanced SQL Server mechanism that allows drilling down into a hidden and advanced SQL Server features to ensure more effective troubleshooting and debugging, advanced monitoring of SQL Server behavior and diagnosing of performance issues, or turning on and off various SQL Server features

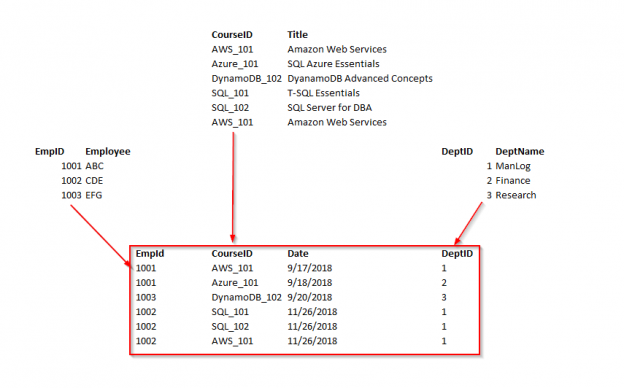
In addition to specifically addressing database normalization in SQL Server, this article will also address the following questions:
Read more »
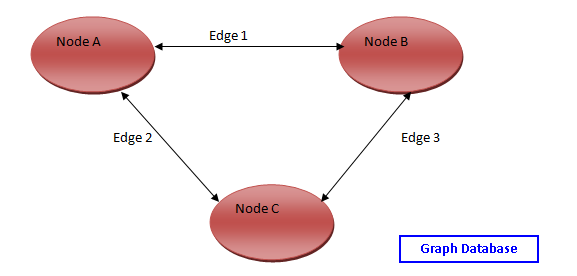
SQL Server 2017 introduced Graph database features where we can represent the complex relationship or hierarchical data. We can explore the following articles to get familiar with the concept of the Graph database.
Read more »
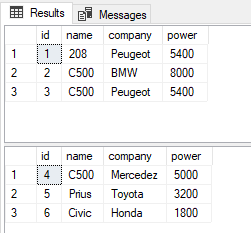
In SQL Server, both the SEQUENCE object and IDENTITY property are used to generate a sequence of numeric values in an ascending order. However, there are several differences between the IDENTITY property and SEQUENCE object. In this article, we will look at these differences.
Read more »
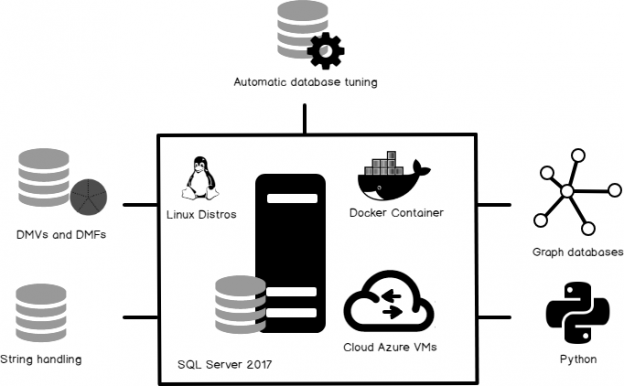
SQL Server 2017 is considered a major release in the history of the SQL Server life cycle for various reasons. From my personal point of view, SQL Server 2017 is indeed an interesting release. After writing lot about it and testing various features of SQL Server 2017, I’d like to walk you through some of its interesting features.
Read more »
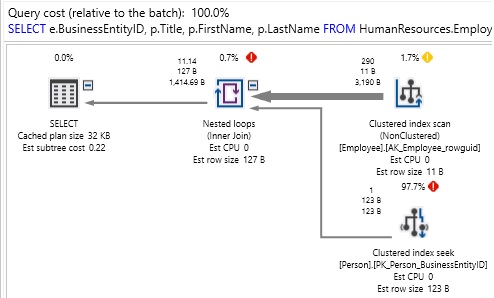
One of the best ways to optimize performance in a database is to design it right the first time! Making design and architecture decisions based on facts and best practices will reduce technical debt and the number of fixes that you need to implement in the future.
Read more »
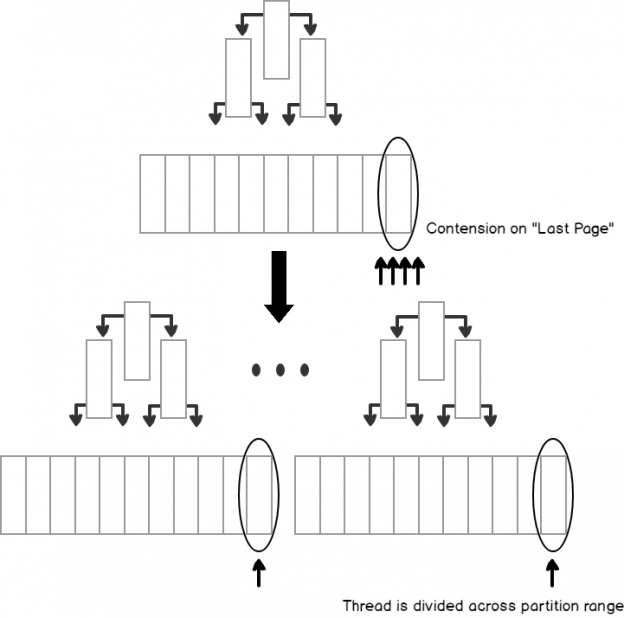
In SQL Server, when talking about table partitions, basically, SQL Server doesn’t directly support hash partitions. It has an own logically built function using persisted computed columns for distributing data across horizontal partitions called a Hash partition.
Read more »
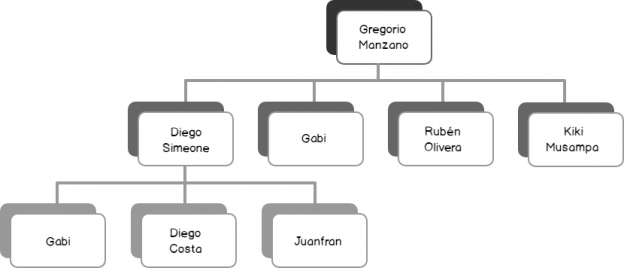
Earlier this year, I published several articles on SQLShack with an aim of demonstrating tools available for visualising SQL Server 2017 graph databases. I was so caught up in the excitement of having SQL Server finally support graph databases that I forgot that some people still do not have a good grasp of how graph databases work let alone consider replacing their relational databases models in favour of graph. Although there are several ways that one can go about explaining the usefulness of graph databases over its relational counterpart, I have opted to focus on the benefits and strengths of graph databases by demonstrating the differences in which graph and relational databases deal with hierarchical datasets.
Read more »
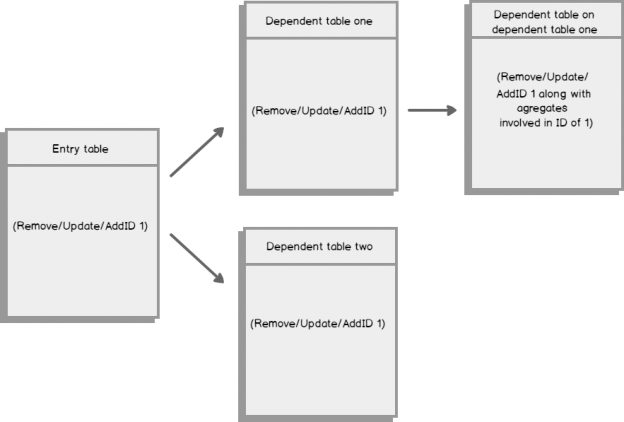
We receive many database alerts with many of the alerts logging some of these same alerts or information to files or tables. What we’ve found over time is that the logging is now costing us quite a bit of resource. Our logging server (where both files and table logging are stored) has had a few outages related to conflicts from messages for other servers. We’ve considered scaling the alerting by environment type, but we’ve also considered that we may be logging too much information about our databases. In addition, since we receive so many alerts each day, it’s impossible for us to resolve them and assist with other issues that arise. What are some techniques that we can use to help us with the issue of too much logging information and too many alerts? Read more »
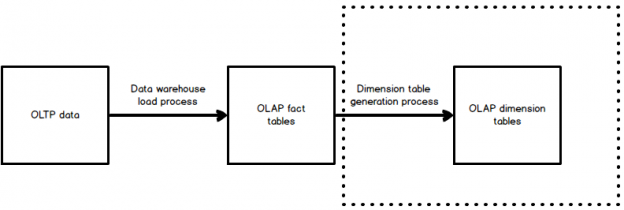
When building reporting structures, we typically have the need to build fact and dimension tables to support the apps that will consume this data. Sometimes we need to generate large numbers of dimension tables to support application needs, such as in Tableau, Entity Framework, or Power BI.
Creating this schema by hand is time-consuming and error-prone. Automating it can be a way to improve predictability, maintainability, and save a ton of time in the process!
Read more »
Every data warehouse developer is likely to appreciate the significance of having surrogate keys as part of derived fields in your facts and dimension tables. Surrogate keys make it easy to define constraints, create and maintain indexes, as well as define relationships between tables. This is where the Identity property in SQL Server becomes very useful because it allows us to automatically generate and increment our surrogate key values in data warehouse tables. Unfortunately, the generating and incrementing of surrogate keys in versions of SQL Server prior to SQL Server 2017 was at times challenging and inconsistent by causing huge gaps between identity values. In this article, we take a look at one improvement made in SQL Server 2017 to reduce the creation of gaps between identity values.
Read more »
Graph database
A graph database is a type of database whose concept is based on nodes and edges.
Graph databases are based on graph theory (a graph is a diagram of points and lines connected to the points). Nodes represent data or entity and edges represent connections between nodes. Edges own properties that can be related to nodes. This capability allows us to show more complex and deep interactions between our data. Now, to explain this interaction we will show it in a simple diagram
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy