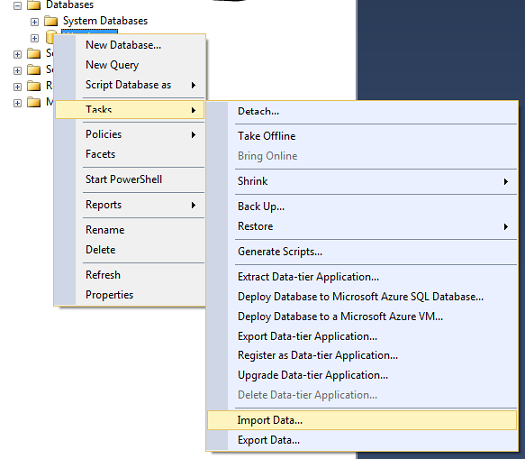
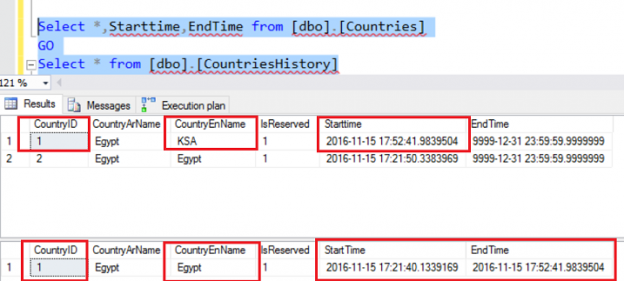
Receiving a comma delimited file is not new technology nor is it difficult to deal with in SQL Server. As a matter of fact, it is extremely easy. There are many cases as to why you would want to do this. For example, you have an external data source that needs to be imported into your database/table. There a couple ways to do this, however the quickest and easiest way is to use the native “import” feature within SQL Server Management Studio and you can even save it to an SSIS Package at the end of the process. The end result of using this method is that the external CSV file is loaded into a SQL Server table where columns are created and rows are populated.
Read more »