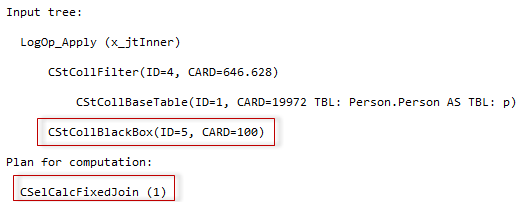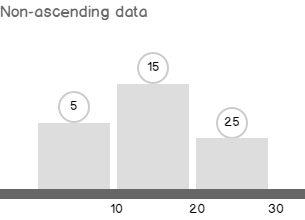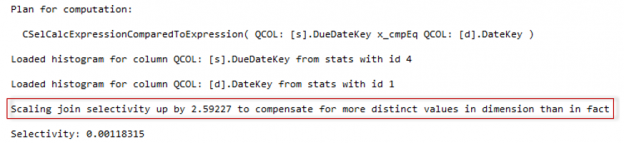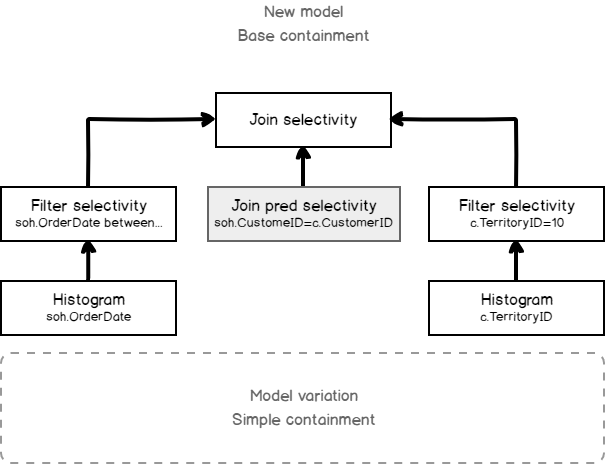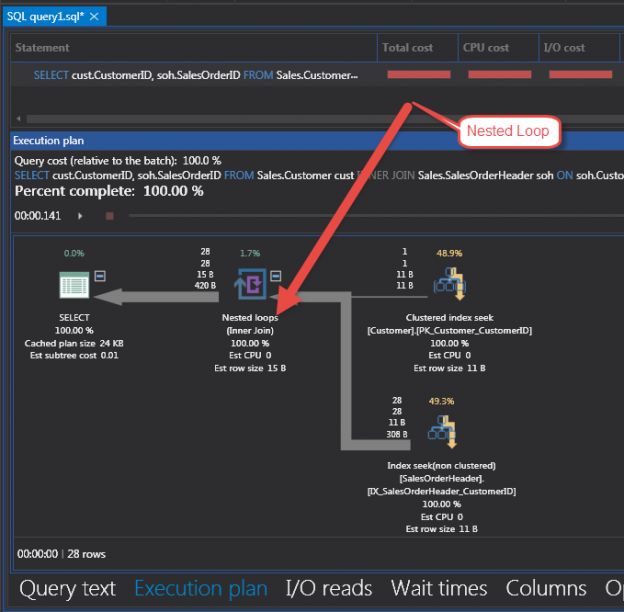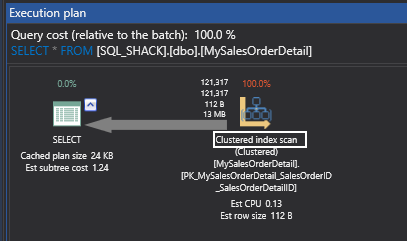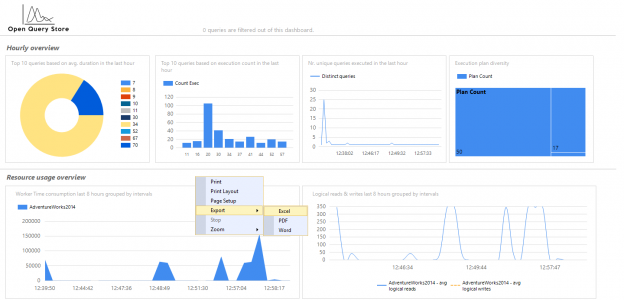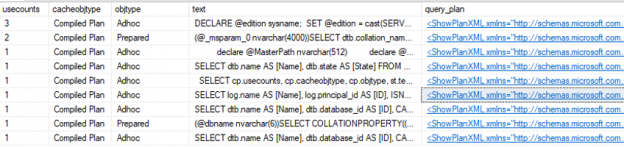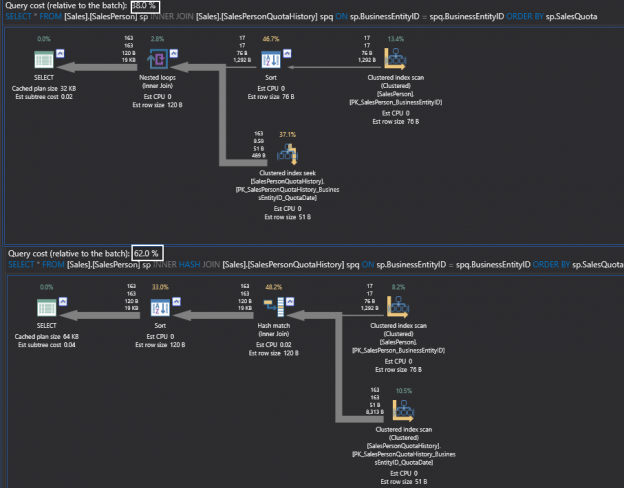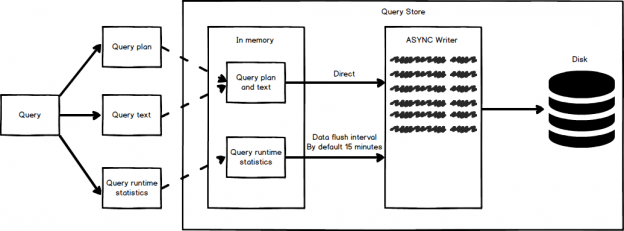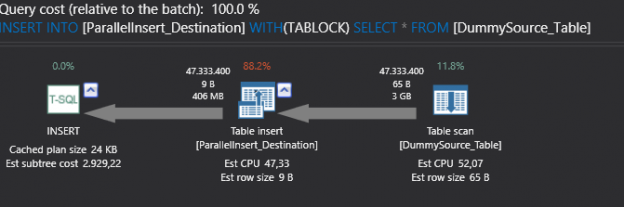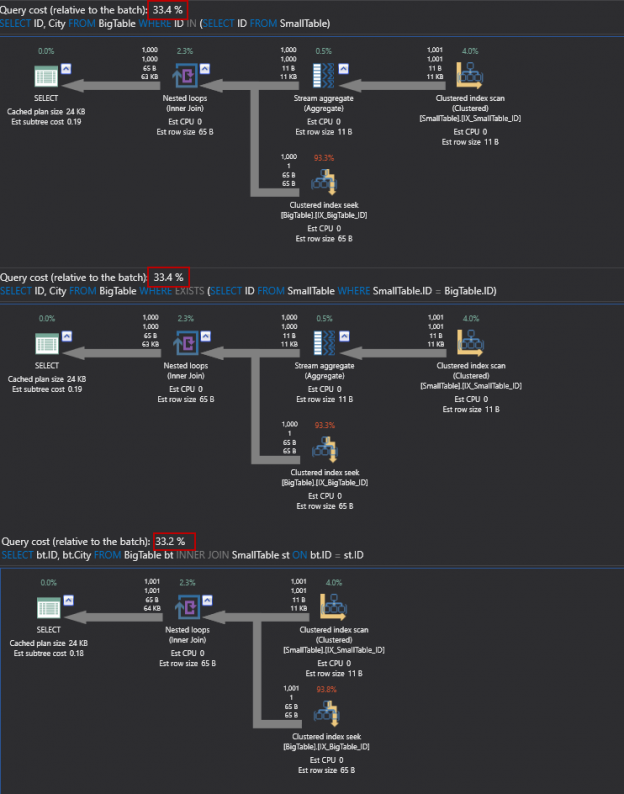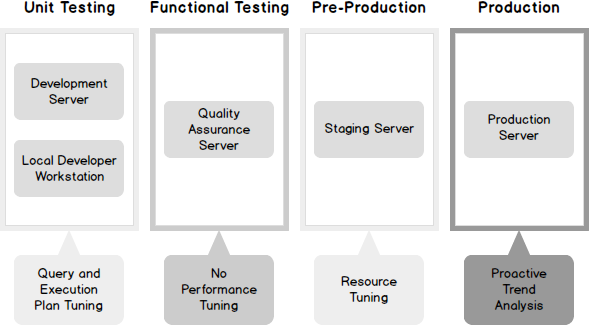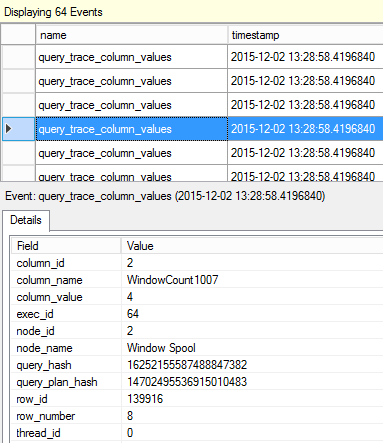
Sometimes, when I saw expressions like ‘Expr1002’ or ‘WindowCount1007’ or something similar in the columns Output List of a query plan, I asked myself, is there a way to project those columns into the final result to look at the values. That question first came to me out of curiosity when I was playing with window aggregate functions and a Window Spool plan operator in SQL Server 2012, I wanted to look into the Window Spool to understand, how it performs an aggregation.
Interestingly, that SQL Server 2016 CTP3.0 allows us to look deep inside into the iterator and observe the data flowing through it. Let’s turn on an “x-ray machine” and take a look.
Read more »