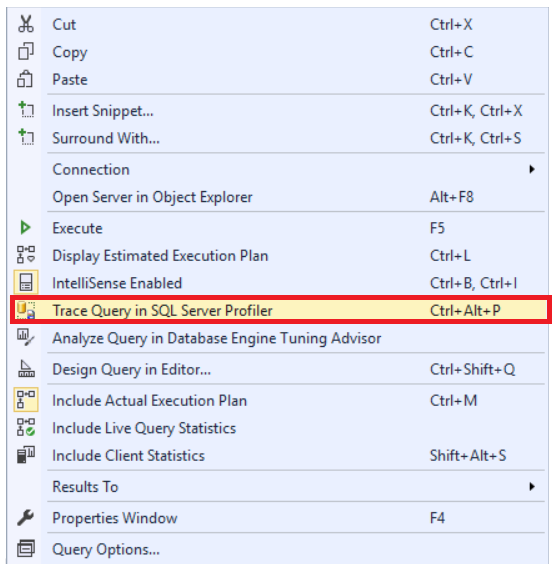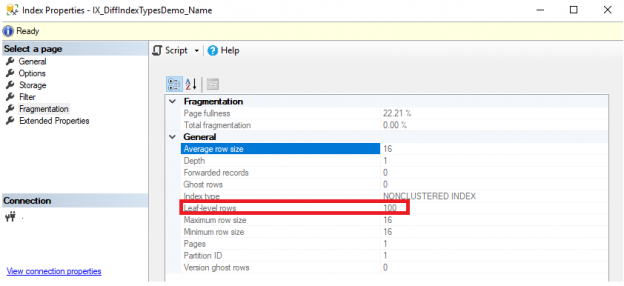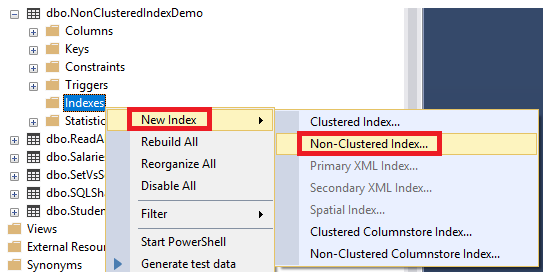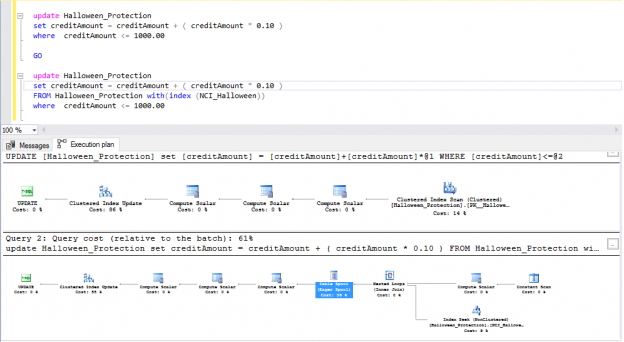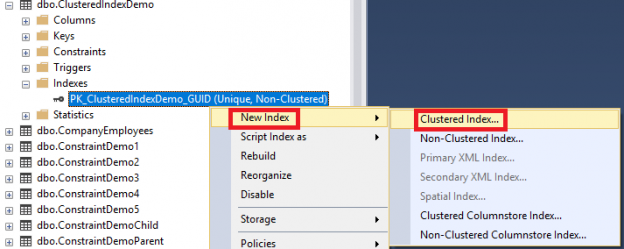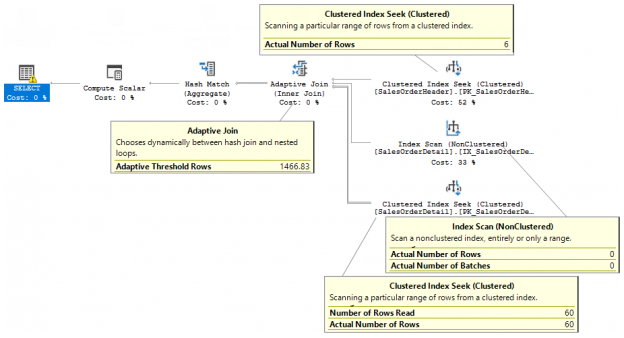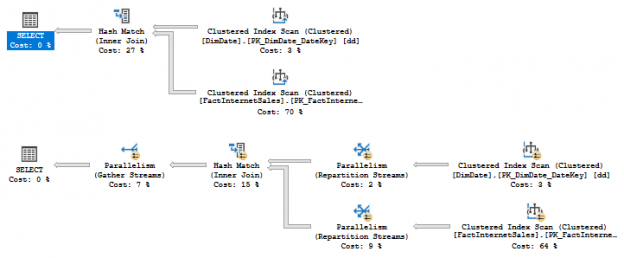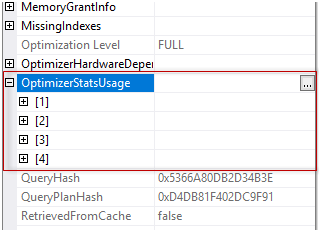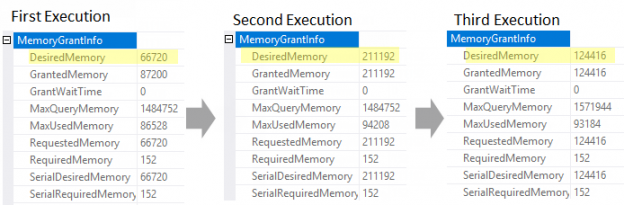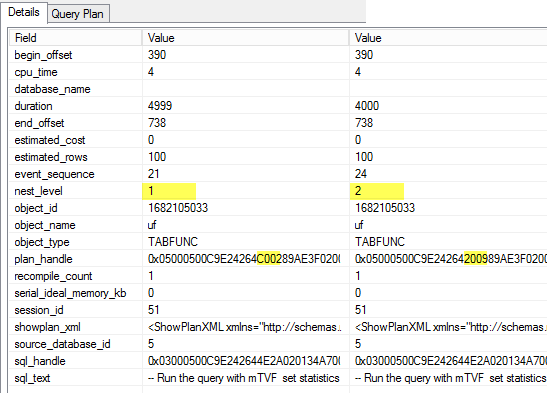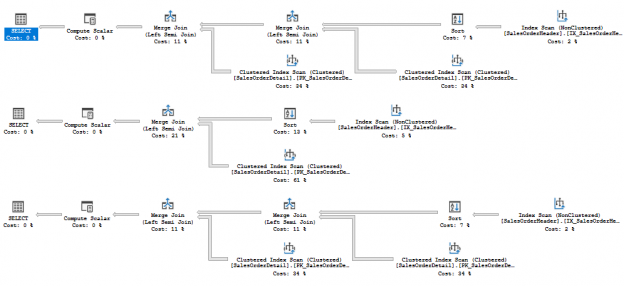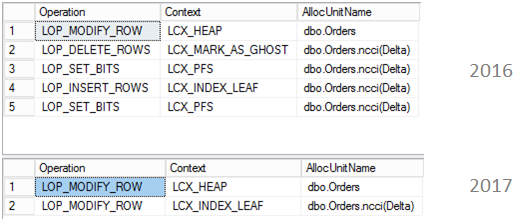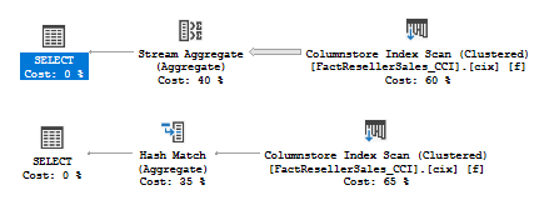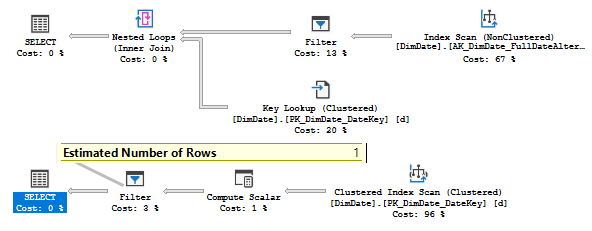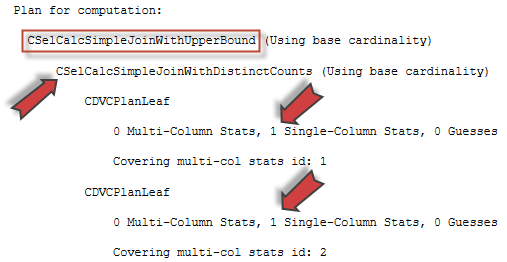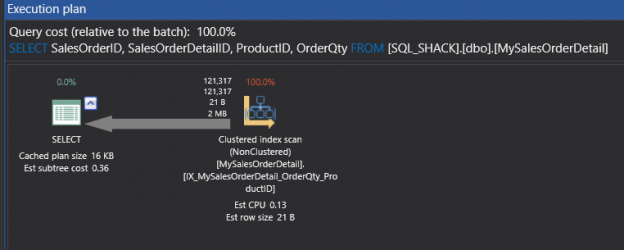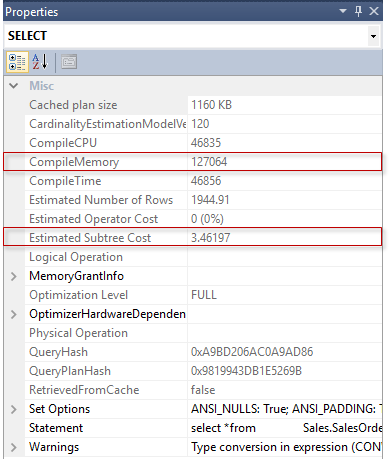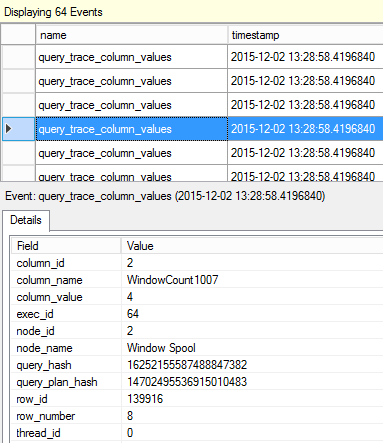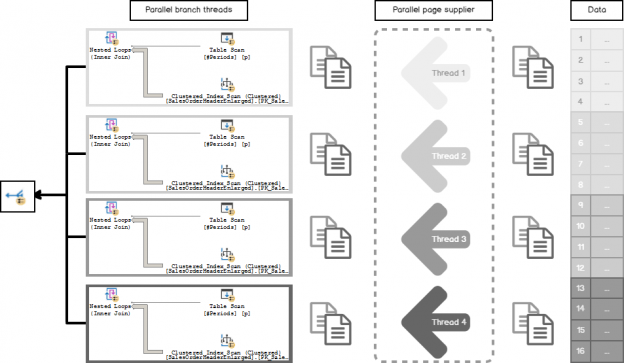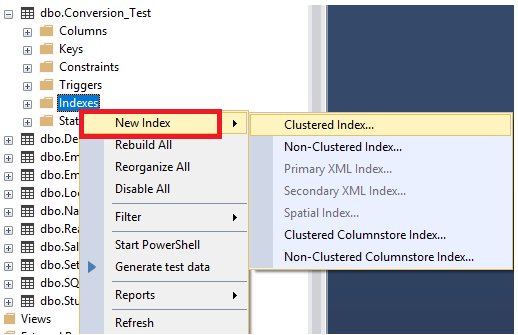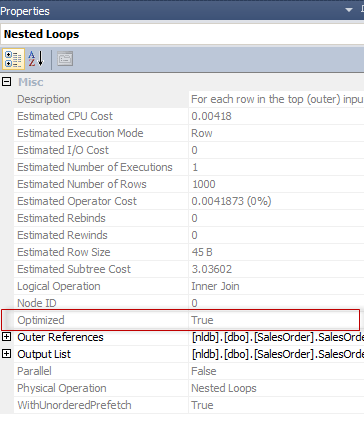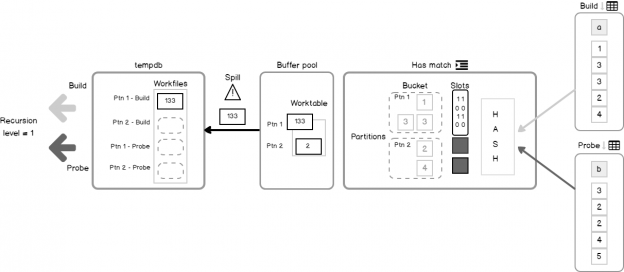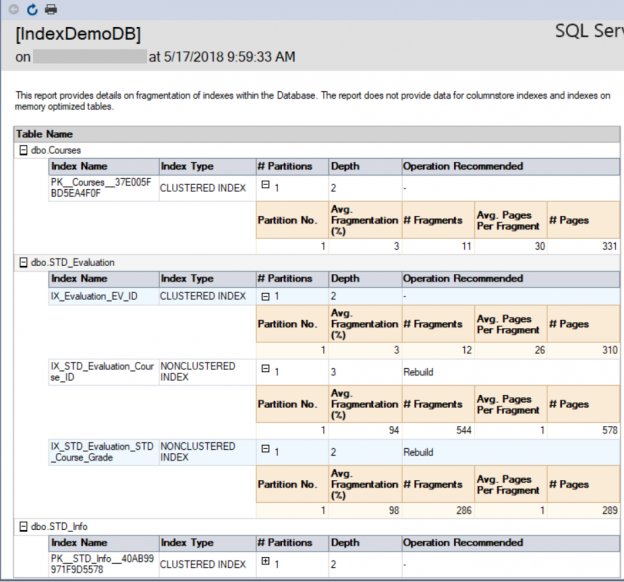
In the previous articles of this series (see the full article TOC at bottom), we discussed the internal structure of both the SQL Server tables and indexes, the best practices that you can follow in order to design a proper index, list of operations that you can perform on the SQL Server indexes, how to design effective Clustered and Non-clustered indexes, the different types of SQL Server indexes, above and beyond Clustered and Non-clustered indexes classification and finally how to tune the performance of the bad queries using the different types of SQL Server Indexes. In this article, we will discuss how to gather statistical information about the index structure and the index usage information.
Read more »