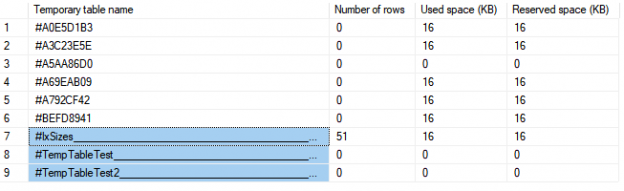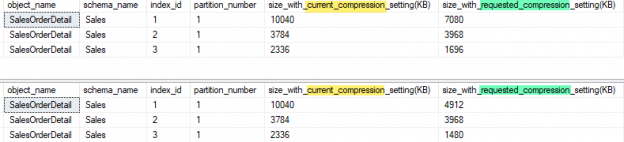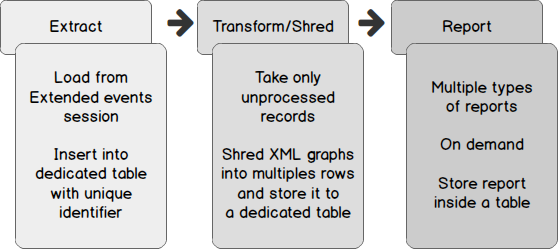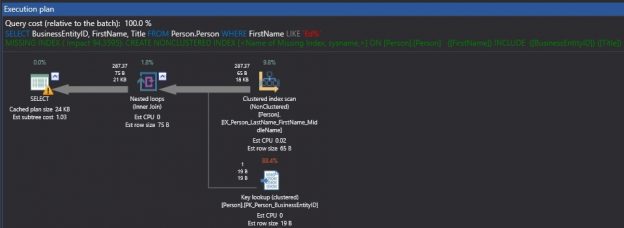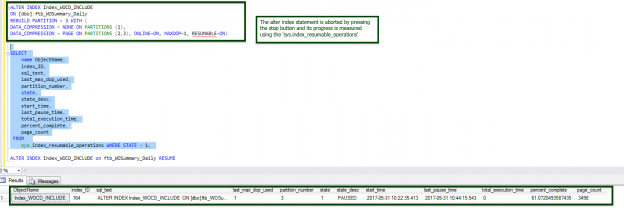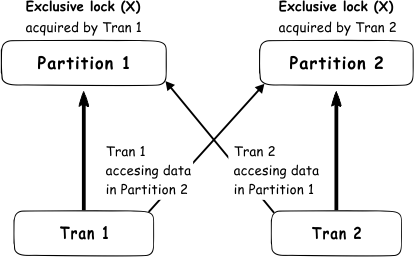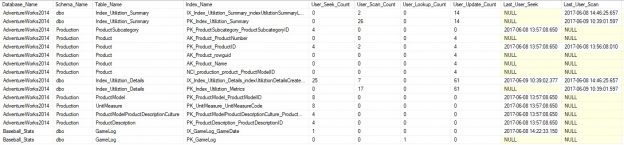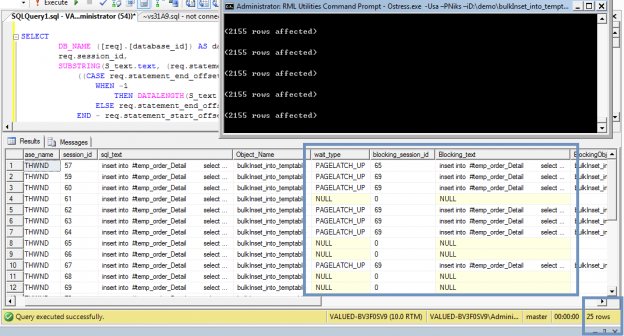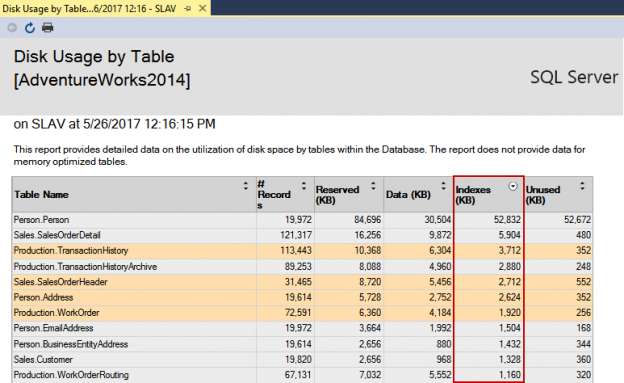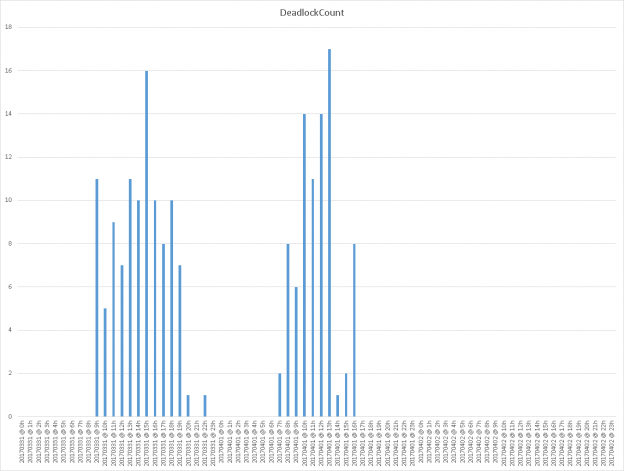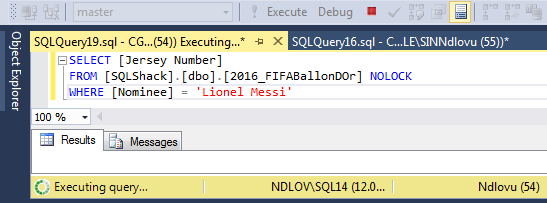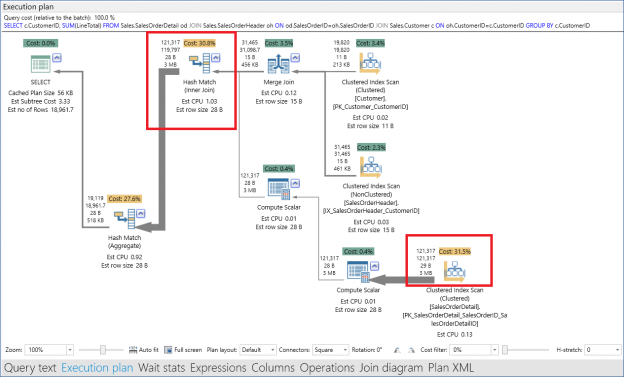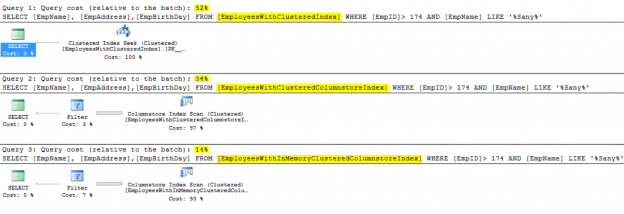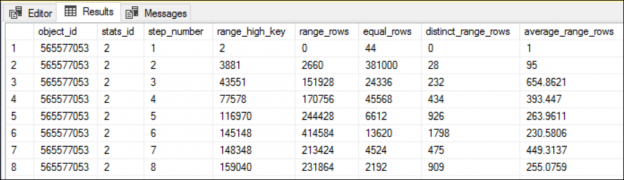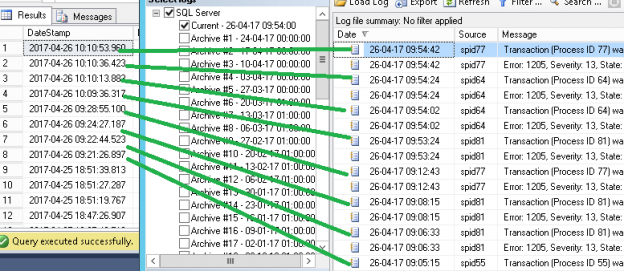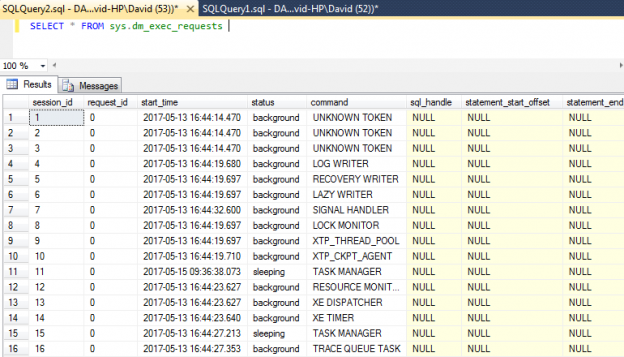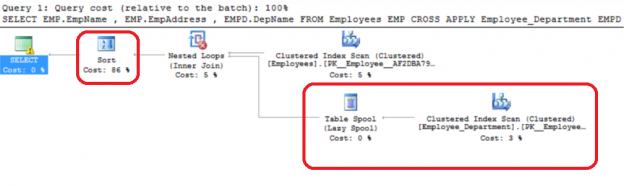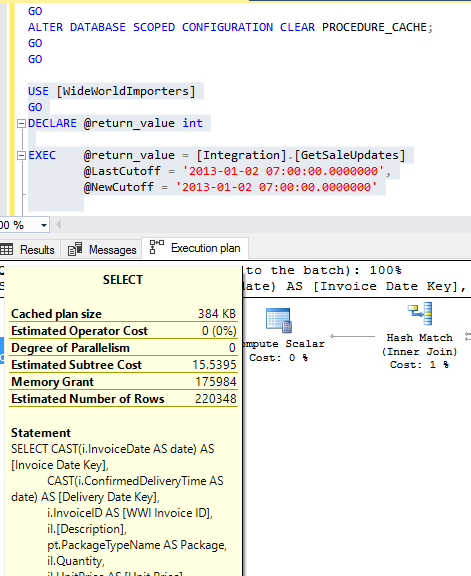
One of the recent tasks I undertook on configuring Transparent Data encryption (TDE) using asymmetric key protection with Azure Key Vault with Always On opened a different dimension on securing data for me. Even though it seems slightly complex, if you have the key details, the steps are in fact, really straight forward.
Read more »