

This article explains different ways to change the location of the FILESTREAM data files. The FILESTREAM feature was introduced in SQL Server 2008 version. We can efficiently store the BLOBs in the SQL database using FILESTERAM.
When should we keep the FILESTREAM filegroup in a separate drive?
The location of the FILESTREAM filegroup should be kept different under the following circumstances:
- When we develop an application that interacts with images and files very frequently, we can keep the FILESTREAM data files of the SQL database in a separate drive to reduce the IO bottleneck and improve the performance.
- Sometimes we configure the FILESTREAM filegroup on the default location. Eventually, the drive on which the FILESTREAM has been configured starts filling up, and it becomes difficult to manage the FILESTREAM data. So, it is advisable to keep the FILESTREAM filegroup on a separate drive.
I recently worked on a project to move the FILESTREAM data to a separate drive of the server. As I mentioned above, the SQL database was not configured appropriately; therefore, the drive on which the FILESTREAM data is being stored was run out of space which broke the application’s functionality. We can use any of the following approaches to copy the FILESTREAM data file to a different location.
Method 1: Detach and attach database method
This method is very simple, but if we use this approach, the database remains offline until the location of the FILESTREAM datafile has been changed.
Method 2: Change the location by re-creating a clustered index of the FILESTREAM table.
We will drop and create the clustered index on the FILESTREAM table in this method. If we use this approach, the database will be online, but the FILESTREAM table will remain offline until the clustered index is created.
We evaluated both methods, and as we have downtime, we have used Detach and attach database method to move the FILESTREAM data files.
In this article, I am going to explain both approaches so you can determine the best approach to move the FILESTREAM filegroup of the SQL database.
Environment setup
For demonstration, I have created a database named EltechDB on my workstation. I have created a FILESTREAM filegroup named FG_EltechDB_Employee_Documents, and I have added a datafile named DF_EltechDB_Employee_Documents in the filegroup. We are saving the FILESTREAM data in the D:\EltechDB_Employee\Employee_Documents directory.
The script to create a FILESTREAM filegroup is following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE [master] go ALTER DATABASE [EltechDB] ADD filegroup [FG_EltechDB_Employee_Documents] CONTAINS filestream go USE [master] go ALTER DATABASE [EltechDB] ADD FILE ( NAME = N'DF_EltechDB_Employee_Documents', filename = N'D:\EltechDB_Employee\Employee_Documents' ) TO filegroup [EmployeeDoucment] go |
I have created a FILESTREAM table named tblEmployees to store the data in the table. I have copied a few documents in the D:\EmployeeDocuments directory.
Run the following query to create a table and insert data in tblEmployees.
Query to create table
|
1 2 3 4 5 6 7 8 9 10 |
Use [EltechDB] Go CREATE TABLE [tblEmployee] ( [FileId] UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL UNIQUE, [ID] int identity(1,1) Primary key clustered, [EmployeeID] varchar(10), [Documents] VARBINARY(MAX) FILESTREAM); GO |
Query to insert data
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
DECLARE @Document_1 VARBINARY(max); DECLARE @Document_2 VARBINARY(max); DECLARE @Document_3 VARBINARY(max); SELECT @Document_1 = Cast(bulkcolumn AS VARBINARY(max)) FROM OPENROWSET(BULK 'D:\EmployeeDocuments\Document_1.pdf', single_blob) AS [Document 1] SELECT @Document_2 = Cast(bulkcolumn AS VARBINARY(max)) FROM OPENROWSET(BULK 'D:\EmployeeDocuments\Document_2.pdf', single_blob) AS [Document 2] SELECT @Document_3 = Cast(bulkcolumn AS VARBINARY(max)) FROM OPENROWSET(BULK 'D:\EmployeeDocuments\Document_3.pdf', single_blob) AS [Document 3]; INSERT INTO [tblemployee] ([fileid], [employeeid], [documents]) VALUES ( Newid(), 'EMP0001', @Document_1), ( Newid(), 'EMP0002', @Document_2), ( Newid(), 'EMP0003', @Document_3) |
We want to change the location of the FILESTREAM datafile from D:\EltechDB_Employee\EmployeeDocuments to D:\EltechDB\Employee_Documents.
Now, let us understand how we can change the path of the FILESTREAM data file.
Detach and attach the database
In this method, we must first detach the database, copy the FILESTREAM data to a new location, and re-attach the database. Run the following statement to detach the database.
|
1 2 3 4 5 6 7 8 |
USE [master] go ALTER DATABASE [EltechDB] SET single_user WITH ROLLBACK immediate go EXEC Sp_detach_db [EltechDB] go |
Now, copy the FILESTREAM data to the D:\EltechDB\Employee_Documents directory. Once files are copied, attach the database.
Note: The sp_attach_db command is deprecated, so we use CREATE DATABASE FOR ATTACH statement to attach the database. We can specify the new location in the CREATE DATABASE ADD FILEGROUP statement.
Run the following query the attach the database
|
1 2 3 4 5 6 7 8 9 10 11 |
USE [master] GO CREATE DATABASE [EltechDB] ON ( FILENAME = N'D:\MS_SQL\Data\EltechDB_Data.mdf' ), ( FILENAME = N'D:\MS_SQL\Log\EltechDB_Log.ldf' ), FILEGROUP [FG_EltechDB_Employee_Documents] CONTAINS FILESTREAM DEFAULT ( NAME = N'DF_EltechDB_Employee_Documents', FILENAME = N'D:\EltechDB\Employee_Documents' ) FOR ATTACH GO |
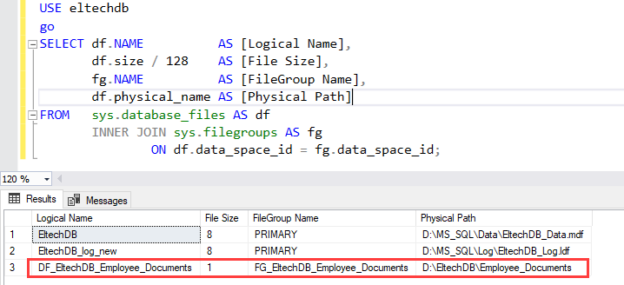
Once the database is attached, run the following statement to verify whether the FILESTREAM data file location has been changed.
Query
|
1 2 3 4 5 6 7 8 9 10 11 |
USE eltechdb go SELECT df.NAME AS [Logical Name], df.size / 128 AS [File Size], fg.NAME AS [FileGroup Name], df.physical_name AS [Physical Path] FROM sys.database_files AS df INNER JOIN sys.filegroups AS fg ON df.data_space_id = fg.data_space_id; |
Output
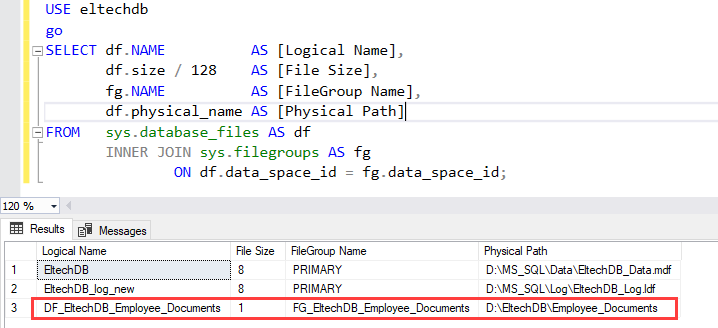
As you can see, the location has been changed. Now, let us jump to another method.
Drop and re-create clustered index of FILESTREAM table
In this method, first, we must create a new FILESTREAM filegroup named FG_EltechDB_Employee_Documents_New. Add a datafile named DF_EltechDB_Employee_Document_New in the FG_EltechDB_Employee_Document_New filegroup. The FG_EltechDB_Employee_Document_New must be the default filegroup for FILESTREAM data. Run the following query
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE [master] GO ALTER DATABASE [EltechDB] ADD FILEGROUP [FG_EltechDB_Employee_Documents_New] CONTAINS FILESTREAM GO USE [master] GO ALTER DATABASE [EltechDB] ADD FILE ( NAME = N'DF_EltechDB_Employee_Documents_New', FILENAME = N'C:\EltechDB\Employee_Documents' ) TO FILEGROUP [FG_EltechDB_Employee_Documents_New] GO ALTER DATABASE [EltechDB] MODIFY FILEGROUP [FG_EltechDB_Employee_Documents_New] DEFAULT GO |
Now, drop the clustered index on the tblemployee table by running the following query.
|
1 2 3 4 |
ALTER TABLE [dbo].[tblemployee] DROP CONSTRAINT [PK__tblEmplo__3214EC277F3CFB9E] |
Create the index. The new index will be created in the FG_EltechDB_Employee_Document_New filegroup, and the FILESTREAM data will be located in the new filegroup.
|
1 2 3 4 |
ALTER TABLE [dbo].[tblemployee] ADD PRIMARY KEY CLUSTERED ( [id] ASC ) |
The data will be stored in the new location when you insert a new record.
Note: This method can be used only when the table has a clustered index, and the clustered index must be created on a column other than the ROWGUID column.
Summary
The database capacity planning is the most important phase of the application development. Often, we do not consider the data growth trends, and eventually, we run into problems that break the application’s functionality.
In this article, we learned how to change the location of the FILESTREAM filegroup of the SQL Database. We learned the following methods that are used to move the FILESTREAM filegroup.
- Detach and attach SQL database method
- Change the location by re-creating a clustered index of the FILESTREAM table.
See more
ApexSQL Complete is a SQL code complete tool that includes features like code snippets, SQL auto-replacements, tab navigation, saved queries and more for SSMS and Visual Studio


He has expertise in database design, performance tuning, backup and recovery, HA and DR setup, database migrations and upgrades. He has completed the B.Tech from Ganpat University. He can be reached on nisargupadhyay87@outlook.com
- Different ways to identify and change compatibility levels in SQL Server - July 22, 2024
- Copy SQL Databases between Windows 10 and CentOS using SQL Server data tools - October 19, 2022
- Changing the location of FILESTREAM data files in SQL Database - October 14, 2022