
This article explains the SQL NOT NULL, Unique and SQL Primary Key constraints in SQL Server with examples.
Constraints in SQL Server are predefined rules and restrictions that are enforced in a single column or multiple columns, regarding the values allowed in the columns, to maintain the integrity, accuracy, and reliability of that column’s data. In other words, if the inserted data meets the constraint rule, it will be inserted successfully. If the inserted data violates the defined constraint, the insert operation will be aborted.
Constraints in SQL Server can be defined at the column level, where it is specified as part of the column definition and will be applied to that column only, or declared independently at the table level. In this case, the constraint rules will be applied to more than one column in the specified table. The constraint can be created within the CREATE TABLE T-SQL command while creating the table or added using ALTER TABLE T-SQL command after creating the table. Adding the constraint after creating the table, the existing data will be checked for the constraint rule before creating that constraint.
There are six main constraints that are commonly used in SQL Server that we will describe deeply with examples within this article and the next one. These constraints are:
- SQL NOT NULL
- UNIQUE
- PRIMARY KEY
- FOREIGN KEY
- CHECK
- DEFAULT
In this article, we will go through the first three constraints; SQL NOT NULL, UNIQUE and SQL PRIMARY KEY, and we will complete the rest three constraints in the next article. Let us start discussing each one of these SQL Server constraints with a brief description and practical demo.
NOT NULL Constraint in SQL
By default, the columns are able to hold NULL values. A NOT NULL constraint in SQL is used to prevent inserting NULL values into the specified column, considering it as a not accepted value for that column. This means that you should provide a valid SQL NOT NULL value to that column in the INSERT or UPDATE statements, as the column will always contain data.
Assume that we have the below simple CREATE TABLE statement that is used to define the ConstraintDemo1 table. This table contains only two columns, ID and Name. In the ID column definition statement, the SQL NOT NULL column-level constraint is enforced, considering the ID column as a mandatory column that should be provided with a valid SQL NOT NULL value. The case is different for the Name column that can be ignored in the INSERT statement, with the ability to provide it with NULL value. If the null-ability is not specified while defining the column, it will accept the NULL value by default:
|
1 2 3 4 5 6 7 8 9 |
USE SQLShackDemo GO CREATE TABLE ConstraintDemo1 ( ID INT NOT NULL, Name VARCHAR(50) NULL ) |
If we try to perform the below three insert operations:
|
1 2 3 4 5 6 7 8 |
INSERT INTO ConstraintDemo1 ([ID],[NAME]) VALUES (1,'Ali') GO INSERT INTO ConstraintDemo1 ([ID]) VALUES (2) GO INSERT INTO ConstraintDemo1 ([NAME]) VALUES ('Fadi') GO |
You will see that the first record will be inserted successfully, as both the ID and Name column’s values are provided in the INSERT statement. Providing the ID only in the second INSERT statement will not prevent the insertion process from being completed successfully, due to the fact that the Name column is not mandatory and accepts NULL values. The last insert operation will fail, as we only provide the INSERT statement with a value for the Name column, without providing value for the ID column that is mandatory and cannot be assigned NULL value, as shown in the error message below:

Checking the inserted data, you will see that only two records are inserted and the missing value for the Name column in the second INSERT statement will be NULL, which is the default value, as shown in the result below:

Assume that we need to prevent the Name column on the previous table from accepting NULL values after creating the table, using the ALTER TABLE T-SQL statement below:
|
1 2 3 |
ALTER TABLE ConstraintDemo1 ALTER COLUMN [Name] VARCHAR(50) NOT NULL |
You will see that the command will fail, as it will check the existing values of the Name column for NULL values first before creating the constraint, as shown in the error message below:

To enforce the NOT NULL Constraints in SQL, we should remove all NULL values of the Name column from the table, using the UPDATE statement below, that replaces the NULL values with empty string:
|
1 2 3 |
UPDATE ConstraintDemo1 SET [Name]='' WHERE [Name] IS NULL |
If you try to create the Constraints in SQL again, it will be created successfully as shown below:

The SQL NOT NULL constraint can be also created using the SQL Server Management Studio, by right-clicking on the needed table and select the Design option. Beside each column, you will find a small checkbox that you can use to specify the null-ability of that column. Unchecking the checkbox beside the column, a SQL NOT NULL constraint will be created automatically, preventing any NULL value from being inserted to that column, as shown below:

UNIQUE Constraints in SQL
The UNIQUE constraint in SQL is used to ensure that no duplicate values will be inserted into a specific column or combination of columns that are participating in the UNIQUE constraint and not part of the PRIMARY KEY. In other words, the index that is automatically created when you define a UNIQUE constraint will guarantee that no two rows in that table can have the same value for the columns participating in that index, with the ability to insert only one unique NULL value to these columns, if the column allows NULL.
Let us create a small table with two columns, ID and Name. The ID column cannot hold duplicate values due to the UNIQUE constraint specified with the column definition. No restriction defined on the Name column, as in the CREATE TABLE T-SQL statement below:
|
1 2 3 4 5 6 7 8 9 |
USE SQLShackDemo GO CREATE TABLE ConstraintDemo2 ( ID INT UNIQUE, Name VARCHAR(50) NULL ) |
If we try to run the four INSERT statements below:
|
1 2 3 4 5 6 7 8 9 10 |
INSERT INTO ConstraintDemo2 ([ID],[NAME]) VALUES (1,'Ali') GO INSERT INTO ConstraintDemo2 ([ID],[NAME]) VALUES (2,'Ali') GO INSERT INTO ConstraintDemo2 ([ID],[NAME]) VALUES (NULL,'Adel') GO INSERT INTO ConstraintDemo2 ([ID],[NAME]) VALUES (1,'Faris') GO |
The first two records will be inserted successfully, with no constraint preventing duplicate values of the Name column. The third record will be inserted successfully too, as the unique ID column allows only one NULL value. The last INSERT statement will fail, as the ID column doesn’t allow duplicate values and the provided ID value is already inserted to that column, as shown in the error message below:

The three inserted rows will be as shown below:

The INFORMATION_SCHEMA.TABLE_CONSTRAINTS system object can be easily used to retrieve information about all defined constraints in a specific table using the T-SQL script below:
|
1 2 3 4 5 6 7 8 |
SELECT CONSTRAINT_NAME, TABLE_SCHEMA , TABLE_NAME, CONSTRAINT_TYPE FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS WHERE TABLE_NAME='ConstraintDemo2' |
The previous query result will show the defined UNIQUE constraint in SQL in the provided table, which will be like:

Using the constraint name retrieved from the INFORMATION_SCHEMA.TABLE_CONSTRAINTS system object, we can drop the UNIQUE constraint using the ALTER TABLE…DROP CONSTRAINT in SQL T-SQL command below:
|
1 2 3 |
ALTER TABLE ConstraintDemo2 DROP CONSTRAINT [UQ__Constrai__3214EC26B928E528] |
If you try to run the previously failed INSERT statement, the record with duplicate ID value will be inserted successfully:

Trying to add the UNIQUE constraint in SQL again using the ALTER TABLE…ADD CONSTRAINT T-SQL command below:
|
1 2 3 4 |
ALTER TABLE ConstraintDemo2 ADD CONSTRAINT UQ__Constrai UNIQUE (ID) GO |
The constraint in SQL creation will fail, due to having duplicate values of that column in the table, as shown in the error message below:

Checking the inserted data, the duplicate values will be clear as shown below:

In order to add the UNIQUE constraint, you have the choice of deleting or modifying the duplicate values. In our case, we will update the second duplicate ID value using the UPDATE statement below:
|
1 2 3 |
UPDATE [SQLShackDemo].[dbo].[ConstraintDemo2] SET ID =3 WHERE NAME='FARIS' |
Now, the UNIQUE constraint in SQL can be added to the ID column with no error as below:

The UNIQUE key can be viewed using SQL Server Management Studio, by expanding the Keys node under the selected table. You can also see the automatically created index that is used to guarantee the column values uniqueness. Note that you will not be able to drop that index without dropping the UNIQUE constraint first:

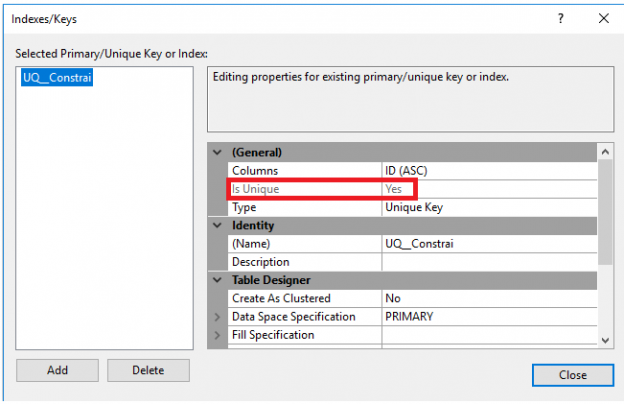
In addition to the previously shown T-SQL commands, the UNIQUE constraint can be also defined and modified using the SQL Server Management Studio. Right-click on the needed table and choose Design. From the Design window, right-click on that window and choose Indexes/Keys, from where you can mark the constraint as UNIQUE, as shown below:

SQL PRIMARY KEY Constraint
The PRIMARY KEY constraint consists of one column or multiple columns with values that uniquely identify each row in the table.
The SQL PRIMARY KEY constraint combines between the UNIQUE and SQL NOT NULL constraints, where the column or set of columns that are participating in the PRIMARY KEY cannot accept a NULL value. If the PRIMARY KEY is defined in multiple columns, you can insert duplicate values on each column individually, but the combination values of all PRIMARY KEY columns must be unique. Take into consideration that you can define only one PRIMARY KEY per each table, and it is recommended to use small or INT columns in the PRIMARY KEY.
In addition to providing fast access to the table data, the index that is automatically created, when defining the SQL PRIMARY KEY, will enforce the data uniqueness. The PRIMARY KEY is used mainly to enforce the entity integrity of the table. Entity integrity ensures that each row in the table is a uniquely identifiable entity.
PRIMARY KEY constraint differs from the UNIQUE constraint in that; you can create multiple UNIQUE constraints in a table, with the ability to define only one SQL PRIMARY KEY per each table. Another difference is that the UNIQUE constraint allows for one NULL value, but the PRIMARY KEY does not allow NULL values.
Assume that we have the below simple table with two columns; the ID and Name. The ID column is defined as a PRIMARY KEY for that table, that is used to identify each row on that table by ensuring that no NULL or duplicate values will be inserted to that ID column. The table is defined using the CREATE TABLE T-SQL script below:
|
1 2 3 4 5 6 7 8 9 |
USE SQLShackDemo GO CREATE TABLE ConstraintDemo3 ( ID INT PRIMARY KEY, Name VARCHAR(50) NULL ) |
If you try to run the three INSERT statements below:
|
1 2 3 4 5 6 7 8 |
INSERT INTO ConstraintDemo3 ([ID],[NAME]) VALUES (1,'John') GO INSERT INTO ConstraintDemo3 ([NAME]) VALUES ('Fadi') GO INSERT INTO ConstraintDemo3 ([ID],[NAME]) VALUES (1,'Saeed') GO |
You will see that the first record will be inserted successfully as both the ID and Name values are valid. The second insert operation will fail, as the ID column is mandatory and cannot be NULL, as the ID column is the SQL PRIMARY KEY. The last INSERT statement will fail too as the provided ID value already exists and the duplicate values are not allowed in the PRIMARY KEY, as shown in the error message below:

Checking the inserted values, you will see that only the first record is inserted successfully as below:

If you do not provide the SQL PRIMARY KEY constraint with a name during the table definition, the SQL Server Engine will provide it with a unique name as you can see from querying the INFORMATION_SCHEMA.TABLE_CONSTRAINTS system object below:
|
1 2 3 4 5 6 7 8 |
SELECT CONSTRAINT_NAME, TABLE_SCHEMA , TABLE_NAME, CONSTRAINT_TYPE FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS WHERE TABLE_NAME='ConstraintDemo3' |
With the below result in our example:

The ALTER TABLE…DROP CONSTRAINT T-SQL statement can be used easily to drop the previously defined PRIMARY KEY using the name derived from the previous result:
|
1 2 3 4 |
ALTER TABLE ConstraintDemo3 DROP CONSTRAINT PK__Constrai__3214EC27E0BEB1C4; |
If you try to execute the previously failed two INSERT statements, you will see that the first record will not be inserted as the ID column does not allow NULL values. The second record will be inserted successfully as these is nothing prevent the duplicate values from being inserted after dropping the SQL PRIMARY KEY, as shown below:

Trying to add the SQL PRIMARY KEY constraint again using the ALTER TABLE T-SQL query below:
|
1 2 3 4 |
ALTER TABLE ConstraintDemo3 ADD PRIMARY KEY (ID); |
The operation will fail, as while checking the existing ID values first for any NULL or duplicate values, SQL Server finds a duplicate ID value of 1 as shown in the error message below:

Checking the table’s data will show you also the duplicate value:

In order to add the PRIMARY KEY constraint, we should clear the data first, by deleting or modifying the duplicate record. Here we will change the second record ID value using the UPDATE statement below:
|
1 2 3 |
UPDATE ConstraintDemo3 SET ID =2 WHERE NAME ='Saeed' |
Then trying to add the SQL PRIMARY KEY, which will be created successfully now:

The SQL PRIMARY KEY constraint can be also defined and modified using SQL Server Management Studio. Right-click on your table and choose Design. From the Design window, right-click on the column or set of columns that will participate in the PRIMARY KEY constraint and Set PRIMARY KEY option, that will automatically uncheck the Allow NULLs checkbox, as shown below:

Please check the next article in the series Commonly used SQL Server Constraints: FOREIGN KEY, CHECK and DEFAULT that describes other three SQL Server constraints.
Useful links
- Constraints
- UNIQUE Constraints
- PRIMARY KEY Constraints
- The benefits, costs, and documentation of database constraints

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021