

The concept of data compression is not a new on for SQL Server Database Administrators , as it is was introduced the first time in SQL Server 2008. In that SQL Server version, you were able to configure the compression at the row and page levels on the table, index, indexed view or the partition. The row and page level compression is not the best choice in all cases, as it does not work well on the Binary Large Objects (BLOB) datatypes, such as the videos, images and text documents.
SQL Server 2016 version keeps with the tradition of surprising us with the new features, enhancements and built-in functions. Starting from SQL Server 2016, an evolution occurred on the data compression technique that were used in the previous versions, by introducing two new built-in functions for compressing and decompressing data, which also available in all SQL Server 2016 editions, opposite to the page and row level compression that is available only in the Enterprise edition.
The Compress and Decompress functions use the Standard GZIP compression algorithm to compress the data itself. In this way, you can easily decompress the data that is compressed at the application side in your SQL Server instance or decompress the data that is compressed at the SQL Server side in your application, as both are using the same standard algorithm.
The basic syntax for the COMPRESS built-in function is:
COMPRESS (Expression)
Where the Expressions can be any value with nvarchar(n), nvarchar(max), varchar(n), varchar(max), varbinary(n), varbinary(max), char(n), nchar(n), or binary(n) data types. The result of the Compression function is a byte array of varbinary(max) data type representing the compressed content of the input value using the GZIP compression algorithm.
Also, the basic syntax for the DECOMPRESS built-in function is:
DECOMPRESS (Expression)
Where the Expressions can be any value with varbinary(n), varbinary(max), or binary(n) data types. Decompress function returns a value with varbinary(max) data type, representing the decompressed value of the binary input argument using the GZIP algorithm. You should explicitly cast the Decompress function result to the required data type in order get a readable result.
You may ask yourself, where we can use these new built-in functions. You can benefit from the COMPRESS and DECOMPRESS functions in compressing big text columns, such as VARCHAR(MAX) or NVARCHAR(MAX) in addition to the large binary data, since the old compression technology at the page and row levels don’t work well with such data types. If you have an already compressed binary data such as jpeg and pdf, you will spend more CPU cycles without taking benefits from a good compression ratio. Moreover, you have the choice to compress it at SQL or the application side and decompress it at the second side, using the same GZIP compressing algorithm.
Worked example
Let us start our practical demo that describes how we can use these two new built-in functions and the performance gain from using it. No special preparation is required to use the COMPRESS and DECOMPRESS functions, just the SQL Server instance that you use should be SQL Server 2016 version.
If you try to run the below simple T-SQL statement that compresses the provided text using SQL Server 2014 version instance:
|
1 2 3 |
SELECT COMPRESS ('WELCOME FROM THE SQLSHACK COMMUNITY') AS Compressed_Value |
The query will fail, showing that the COMPRESS function is not a built-in function in this SQL Server version, which is prior to SQL Server 2016:

Trying the same T-SQL statement in SQL Server 2016 version, which only passes a text value to the COMPRESS function:
|
1 2 3 |
SELECT COMPRESS ('WELCOME FROM THE SQLSHACK COMMUNITY') AS Compressed_Value |
A byte array of VARBINARY(MAX) data type is returned from the previous query, showing a compressed representation of the provided text:

This is simply how the COMPRESS function works. If we take the byte array value generated from the COMPRESS function, and pass it to the DECOMPRESS function as follows:
|
1 2 3 |
SELECT DECOMPRESS (0x1F8B08000000000004000B77F571F6F77555700BF2F75508F17055080EF409F67074F656000AFB86FA7986440200ADAE249523000000) AS Decompressed_Value |
Another binary array of VARBINARY(MAX) data type will be returned from the DECOMPRESS function, showing the decompressed value of the compressed text. However, this does not represent the text that we have provided to the COMPRESS function:

To get a readable text representing the original value provided to the COMPRESS function, we need to explicitly cast the DECOMPRESS function result to a string data type as below:
|
1 2 3 |
SELECT CAST(DECOMPRESS (0x1F8B08000000000004000B77F571F6F77555700BF2F75508F17055080EF409F67074F656000AFB86FA7986440200ADAE249523000000) AS VARCHAR(MAX)) AS Decompressed_Value |
Now we get the original text successfully, after casting the DECOMPRESS function result to VARCHAR(MAX) data type as follows:

The string to be compressed can be also passed to the COMPRESS function as a parameter, and the result of the COMPRESS function can be passed too to the DECOMPRESS function as below:
|
1 2 3 4 5 6 7 |
DECLARE @NormalString VARCHAR(MAX) = 'WELCOME FROM THE SQLSHACK COMMUNITY' SELECT @NormalString As StringtoBeCompressed, COMPRESS(@NormalString) AS AfterCompression , DECOMPRESS(COMPRESS(@NormalString)) AfterDecompression, CAST(DECOMPRESS(COMPRESS(@NormalString)) AS VARCHAR(MAX)) AS AfterCastingDecompression |
The result of the previous query shows the original string to be compressed, the COMPRESS function result, the DECOMPRESS function result and the casted result of the DECOMPRESS function that represents the original text too:

Suppose that we need to compress the below two strings, that have the same value but different data types using the COMPRESS function:
|
1 2 3 4 5 6 |
DECLARE @NormalStringVarchar VARCHAR(MAX) = 'WELCOME FROM THE SQLSHACK COMMUNITY' DECLARE @NormalStringNVarchar NVARCHAR(MAX) = 'WELCOME FROM THE SQLSHACK COMMUNITY' SELECT COMPRESS(@NormalStringVarchar) AS AfterCompressionVarchar ,COMPRESS(@NormalStringNVarchar) AS AfterCompressionNVarchar |
The result will show us that, although these two strings have the same value, it will be compressed to different values, as they have different data types, one with VARCHAR data type and the second one with NVARCHAR data type, as follows:

The question now is, will the string length affect the compression effectiveness? To answer this question, let us take three strings with different lengths and compare the data length of the original string and the compression result as follows:
|
1 2 3 4 5 6 7 8 9 |
DECLARE @NormalString1 VARCHAR(MAX) = 'WELCOME FROM THE SQLSHACK COMMUNITY' DECLARE @NormalString2 VARCHAR(MAX) = 'WELCOME FROM THE SQLSHACK COMMUNITY, WE ARE HAPPY THAT YOU VISITING US, READING AND ENJOYING THE SITE CONTENT' DECLARE @NormalString3 VARCHAR(MAX) = 'WELCOME FROM THE SQLSHACK COMMUNITY, WE ARE HAPPY THAT YOU VISITING US, READING AND ENJOYING THE SITE CONTENT, WHERE YOU CAN FIND ALL USEFUL SQL SERVER DEVELOPMENT AND ADMINISTRATION ARTICLES WRITTEN BY OUR PROFESSIONALS FROM ALL OVER THE WORLD ' SELECT DATALENGTH(@NormalString1) String1Length, DATALENGTH(COMPRESS(@NormalString1)) String1CompressedLength, DATALENGTH(@NormalString2) String1Length, DATALENGTH(COMPRESS(@NormalString2)) String1CompressedLength, DATALENGTH(@NormalString3) String1Length, DATALENGTH(COMPRESS(@NormalString3)) String1CompressedLength |
The result will clearly show us that, as the length of the original string increases, the compression effectiveness increases. The compression is not useful in the case of the small string, where the length of the compressed string is larger than the original one. The compression effectiveness of the string with 109 length is 0.046, where we gain 0.28 when compressing a larger string with 245 length:

The data type of the string to be compressed affects also the compression effectiveness. Assume that we have the same previous large string to be compressed, but this time with XML type, taking into consideration that we should cast it to pass it to the COMPRESS function:
|
1 2 3 4 5 |
DECLARE @xml XML; SET @xml = '<message>WELCOME FROM THE SQLSHACK COMMUNITY, WE ARE HAPPY THAT YOU VISITING US, READING AND ENJOYING THE SITE CONTENT, WHERE YOU CAN FIND ALL USEFUL SQL SERVER DEVELOPMENT AND ADMINISTRATION ARTICLES WRITTEN BY OUR PROFESSIONALS FROM ALL OVER THE WORLD </message>'; SELECT datalength(@xml) AS StringLength,datalength(COMPRESS (cast (@xml as nvarchar(max)))) AS CompreesedStringLength |
The result will show that, with the XML data type, the compression is more efficient, as we gain with the same string about 0.5 compression effectiveness, compared to the previous result of 0.28 when having the VARCHAR data type:

Until this step, we are familiar with how we can use the COMPRESS and DECOMPRESS functions by providing it with the text to be compressed directly or as parameters. Suppose that we need to compress already existing data from one of our tables. Moreover, check if we will take benefits from compressing this data or not. We will start by creating the source table as follows:
|
1 2 3 4 5 6 7 8 9 10 11 |
USE SQLShackDemo GO CREATE TABLE Products_Normal ( ProdID int PRIMARY KEY, ProdName nvarchar(50), ProdDescription nvarchar(MAX) ) GO ) |
Then, filling it with 1,000 records of test data using the ApexSQL Generate test data generation tool:
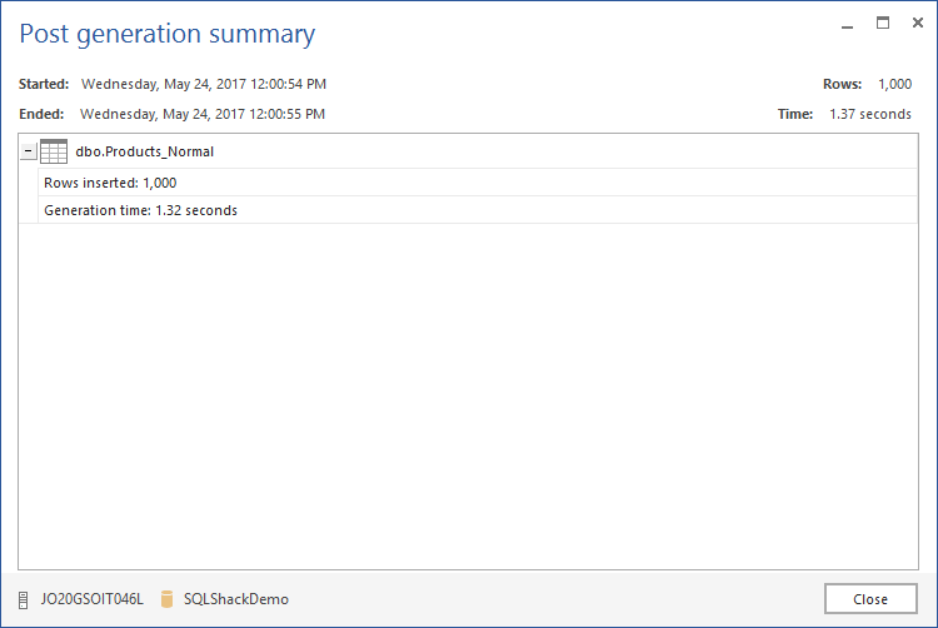
The source table is ready now. We will create a new table with the same data as the Product_Normal table, except for the ProdDescription column that will be compressed in that table easily using the COMPRESS function:
|
1 2 3 4 5 6 7 8 |
SELECT [ProdID] ,[ProdName] ,COMPRESS([ProdDescription]) AS ProdDescription INTO [Products_Compressed] FROM [Products_Normal] GO |
Finally, we will create a new table that contains the same data as the Product_Compressed table except for the ProdDescription column that will be decompressed in that table using the DECOMPRESS function:
|
1 2 3 4 5 6 7 8 |
SELECT [ProdID] ,[ProdName] ,DECOMPRESS([ProdDescription]) AS ProdDescription INTO [Products_DECompressed] FROM [Products_Compressed] GO |
For now, we have three tables; the Product_Normal table that contains the original data with no changes, the Product_Compressed table that contains the compressed values of the ProdDescription column, and the Product_DECompressed table that contains the decompressed values of the ProdDescription column. Let us query the ProdDescription column values from the three tables by joining the three tables together depending on the ProdID values:
|
1 2 3 4 5 6 7 8 |
SELECT TOP 5 N.ProdDescription, COM.ProdDescription, DECOM.ProdDescription FROM [Products_Normal] N JOIN [Products_Compressed] COM ON N.ProdID = COM.ProdID JOIN [Products_DECompressed] DECOM ON DECOM.ProdID = COM.ProdID |
You can see from the result the original values, the compressed values and the decompressed values of the ProdDescription column:

Again, the decompressed values of the ProdDescription column from the DECOMPRESS function do not match the actual string values. So that, we need to cast the decompressed values using the correct data type as follows:
|
1 2 3 4 5 6 7 8 9 |
SELECT TOP 5 N.ProdDescription, COM.ProdDescription, DECOM.ProdDescription , CAST(DECOM.ProdDescription AS VARCHAR(MAX)) AS Decompressed_Data FROM [Products_Normal] N JOIN [Products_Compressed] COM ON N.ProdID = COM.ProdID JOIN [Products_DECompressed] DECOM ON DECOM.ProdID = COM.ProdID |
However, the decompressed value still does not match the original string value. As we mentioned previously, we should cast the DECOMPRESS result using the correct data type, which is the data type of the original string that is NVARCHAR in our case, not VARCHAR as in the previous query:

Casting the decompressed result using the correct data type:
|
1 2 3 4 5 6 7 8 9 |
SELECT TOP 5 N.ProdDescription, COM.ProdDescription, DECOM.ProdDescription , CAST(DECOM.ProdDescription AS NVARCHAR(MAX)) AS Decompressed_Data FROM [Products_Normal] N JOIN [Products_Compressed] COM ON N.ProdID = COM.ProdID JOIN [Products_DECompressed] DECOM ON DECOM.ProdID = COM.ProdID |
We will get the desired output now. The same result as the original string:

For now, we understand how to use the COMPRESS and DECOMPRESS functions to deal with the existing data.
Demonstrating the value
OK. What may encourage us to use it is the benefits that we will take from using it. Let us compare the space consumed by storing the original data and the compressed data using the SP_Spaceused system object:
|
1 2 3 4 5 6 |
SP_Spaceused 'Products_Normal' GO SP_Spaceused 'Products_Compressed' GO |
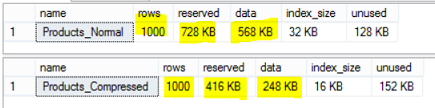
It is clear from the result that storing the same 1,000 records, as compressed values will save 320 KB in our case, which is about 56% of the total space. You can imagine the space that you will save by compressing large tables:
Not yet convinced? Let us compare internally the number of pages that will be consumed by storing the original data and the compressed data:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT OBJECT_NAME(IDX.object_id) [TableName], ptx.rows [RowNum], SUM(ptxS.used_page_count) [PageCount] FROM sys.indexes IDX INNER JOIN sys.partitions ptx ON ptx.object_id = IDX.object_id AND ptx.index_id = IDX.index_id INNER JOIN sys.dm_db_partition_stats ptxS ON ptxS.partition_id = ptx.partition_id WHERE IDX.object_id IN (OBJECT_ID('Products_Normal'), OBJECT_ID('Products_Compressed')) GROUP BY IDX.object_id, ptx.rows |
Again, compressing the data using the COMPRESS function saved about 42 pages, which is 56% of the total number of pages required to store the data:

What about the performance gain that we may take from using the compressed data?
Let us compare between reading from the original table and the compressed table by enabling the TIME and IO statistics, in addition to enabling the actual execution plan, using the below script:
|
1 2 3 4 5 6 7 8 9 10 11 |
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT TOP 100 * FROM Products_Normal WHERE ProdID >554 GO SELECT TOP 100 * FROM Products_Compressed WHERE ProdID >554 SET STATISTICS TIME OFF SET STATISTICS IO OFF |
Wow! The time required to retrieve the data from the compressed table is about 32% of the time required to retrieve the data from the original table:

The IO statistics show us that the logical reads required to read the data from the compressed table is about 0.3 of the logical reads required to read from the original table:

You can derive from the execution plans below that the weight of reading the compressed data is 38%, although it performed a table scan, compared to reading from the original table that consumes 62% of the overall load:

Reading the compressed data and displaying it for the end users has no practical purposes, as this binary data is unintelligible for them. However, we can save the compressed data for the application that will read it, decompress it and display the result for the end users.
In addition, you can save it as compressed data in your table and decompress it in the fly before displaying it to the end users. However, nothing cheap anymore. If we compare between reading the original data and reading the casted decompress data, which will return the same result:
|
1 2 3 4 5 6 7 8 9 10 11 |
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT TOP 100 ProdDescription FROM Products_Normal WHERE ProdDescription like '%AMM%' GO SELECT TOP 100 CAST (decompress(ProdDescription) AS NVARCHAR(MAX)) FROM Products_Compressed WHERE CAST (ProdDescription AS NVARCHAR(MAX)) like '%AMM%' SET STATISTICS TIME OFF SET STATISTICS IO OFF |
You will see that, reading the casted decompressed data will take about 3 times, the time required to retrieve the same data from the original table, with extra CPU time cycles required to read that data:

Although the logical reads required to retrieve the casted decompressed data is about 67% the logical reads required to read the original data, reading the casted decompressed data required 49 read-ahead reads which is not consumed while reading the original data. This means that there is an extra process of reading the data from the disk and placing it to the data cache:

Conclusion:
SQL Server 2016 introduces two new built-in functions that ease and expand the SQL data compression world. The COMPRESS function that is used to compress the text data into a smaller binary data, and the DECOMPRESS function that works opposite to the COMPRESS function by decompressing the compressed binary data and return a meaningless binary data, that you should cast to correct data type to get the original text that is compressed.
We saw clearly during the demo the different way of using these functions and the benefits from using it. We saw how the compressed data takes less space when keeping it in the tables compared to the original data, and that it requires less time to retrieve it from the table. We saw also the other side of the sword, while decompressing and casting the data before displaying it to the users will consume more time and space. You can benefit from these functions by saving the decompressed data on your table and decompress it at the application side to work on it. These new functions are available now, it is yours to start testing and checking if they will rescue you in one of your scenarios.
Useful Links:
- Built-in functions for compression/decompression in SQL Server 2016
- COMPRESS (Transact-SQL)
- DECOMPRESS (Transact-SQL)

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021