
In this article, we will learn how to copy data from an external data source using the COPY command into a dedicated SQL pool of Azure Synapse Analytics.
Introduction
Azure Synapse Analytics is a data warehouse offering on Azure cloud that comes packed with three types of runtimes for processing data using serverless SQL pools, dedicated SQL pools and Spark pools. The dedicated SQL pool provides dedicated storage and processing framework, where one can host and process data in a massively distributed manner using the SQL runtime engine. To process the data on this runtime, data is imported or copied from a variety of data sources on the Azure data ecosystem using means like Azure Databricks, Data Pipelines and other means. Though these are some of the means to create and operate data pipelines, development teams often need the means to import data using the query language itself. Azure Synapse Analytics provides a COPY command which is a standard command offered by many industry leading cloud data warehouses. This command facilitates the copy of data into the local data objects in the dedicated SQL pool of Azure Synapse. In this article, we are going to understand the process to copy data into a dedicated SQL pool of Azure Synapse Analytics using the COPY command.
Pre-requisites
Data exists in file format on containers in the Azure Storage account. These files can be processed and analyzed using various mechanisms like Azure Data Lake Analytics. One of the latest means of analyzing this data is by using Azure Synapse Analytics. We need to copy data from the files hosted on this storage account to a table in the dedicated SQL pool of Synapse. We would need some setup in place, before we can start this exercise.
Firstly, we need a Gen 2 storage account in Azure, where we may host a sample data file in a container. For this create an account if you don’t have one already and host a file in a container and keep the path of the file handy. Then we need an Azure Synapse Analytics workspace with a dedicated SQL pool created in it. This is the repository where we would be copying the files from our storage account. It is assumed that this setup is in place before proceeding with the rest of the exercise.
COPY Command
Let’s look at the syntax of the COPY command which would provide a great deal of insight into the capabilities of this command. The syntax of the COPY command is as shown below:

We can make few observations just from the syntax of the COPY command itself as shown below:
- This command natively supports CSV, Parquet and ORC format files with Gzip or Snappy compression. We can register external file formats as well
- We can provide credentials like Shared Access Signature or the Storage Account Key to read data from the storage account
- We can store the error output in a separate file which would be directly saved on the storage account using the provided credentials for error logging
- We can specify to terminate copying of data is the maximum errors go beyond a defined threshold
- We get several options to specify the structure of the file like row terminator, field terminator, date format, encoding etc
Now that we understand the details of this command, we are ready to copy the data. As evident from the syntax of the command, it expects a database object in which it will copy the data. So first we need to create a table in the dedicated SQL pool where we would copy data. Open SSMS and connect to the Azure Synapse Analytics endpoint and create a new table that has a schema like a source file. Here we are creating a table called Trip which we would populate from the publicly available NYCTaxi dataset file.

Once the table is created, we can execute the COPY command as shown below. Here we are copying data from all the files stored in the location specified in the FROM clause, into the table named Trip. These files have data in pipe-delimited format with a new-line character as row terminator. We can provide a label to our query as shown below, so that we can track its progress using this label. Execute the query, as this is a long-running query and may take a few mins to complete as it is attempting to load approximately 170 million records.

Once the data load completes, we can query the volume of data copied in this table as shown below. This type of large volume copy will provide you an understanding of the time it takes to load such a volume with the capacity provisioned for your dedicated SQL pool. Increasing the capacity of the pool may improve the performance of the copy process as well.

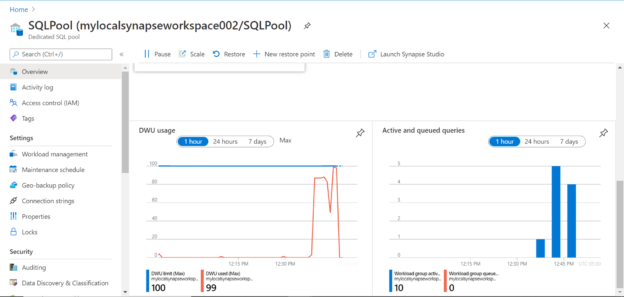
If we navigate to the dashboard page of the Azure Synapse Analytics SQL pool in the Azure portal, we can view the performance and metrics of the pool for the entire data load that was executed with the COPY command as shown below:

In the command that we executed, we did not specify any credentials at all as it’s a publicly available dataset that we can access anonymously. In real-life scenarios, we have a storage account in the private mode of access, so we would need to specify the credentials and other details as well. Now we can try to copy the data from the sample file that we have hosted on our own storage account. Before we do that, we again need a table that resembles the schema of the file. Here we are going to copy data from a Customers file in a CSV format, and the table that has a similar schema can be created by executing a CREATE TABLE command as shown below:

After the table is created, we can execute the copy command to copy data from the data file hosted in the storage account to this newly created table as shown below. Here we can see that the command resulted in errors. We provided the credential using the access key of the storage account. Alternatively, we can provide the Shared Access Signature of the container file as well. The reason this command failed is as we have specified to terminate the copy process if the total number of errors is more than ten. Here we have specified the field terminator as semi-comma, whereas the file we have is a comma- separated file, which resulted in the rejection of all the records and hence it crossed the threshold and the copy process failed.

We can modify the command now as shown below and re-execute this COPY command. This time the command would execute successfully and load the records in the table. The change that we did in the command is that we specified the correct field terminator and removed some optional parameters. As you can see from the output that one record was rejected. The reason for the same is that the file has column headers which were read as a record, and it conflicted with the schema and hence it was rejected.

If we specify the FIRSTROW option and direct the command to start reading from the second row instead of the first row, it would result in a perfectly smooth data copy as shown below:

Once the data is copied, we can query the table to ensure that all the fields were populated as desired by using a simple SELECT query as shown below:

In this way, we can use the COPY command to copy data from the Azure Storage account into Azure Synapse Analytics in a dedicated SQL pool table.
Conclusion
In this article, we learned about the syntax and usage of the COPY command which copies data from containers in Azure storage account to Azure Synapse Analytics SQL pool. We learned how to copy specific as well as multiple files, public and private files, as well as use different schema.
Table of contents
| Getting started with Azure Cosmos DB Serverless |
| Analyzing data hosted in Azure Cosmos DB with Notebooks |
| Analyze Azure Cosmos DB data using Azure Synapse Analytics |
| Restore dedicated SQL pools in Azure Synapse Analytics |
| Copy data into Azure Synapse Analytics using the COPY command |

He has worked internationally with Fortune 500 clients in various sectors and is a passionate author.
View all posts by Rahul Mehta
- Finding Duplicates in SQL - February 7, 2024
- MySQL substring uses with examples - October 14, 2023
- MySQL group_concat() function overview - March 28, 2023