
This article will explore the Copy Data tool for importing data into Azure SQL Database from a web source.
Introduction
Suppose you need to import data into Azure database tables from a CSV file. The source of the CSV file is a Web URL. Usually, we download the file on a local directory and import data into a database table. In the article, Copy Data tool to export data from Azure SQL Database into Azure Storage, we use the Copy Data tool in Azure Data Factory that did the following tasks.
- Export data from Azure Database tables into CSV files
- Store the CSV files into the Azure blob storage container
The Copy Data tool contains 90+ built-in containers that allow you to configure a data loading task without expertise in Azure Data Factory entities (linked services, datasets, pipelines).
Pre-requisites
-
You require a URL of the CSV files for data import. For this article, we will refer sample data set from stats.govt.nz

-
Azure SQL Database Server: We will import the CSV file into a database table. Therefore, you need an Azure database. For this article, we will use the following SQL Database:
-
Azure Data Factory (ADF) V2 instance: We configured the ADF instance in the previous article, as shown below. You can use it or deploy a new ADF instance using Azure portal -> Data Factory



Azure Data Factory
Azure Data Factory is a cloud-based ETL (Extract-Transform-Load) that provides data-driven data transformation and movement pipelines. It contains interconnected systems for providing an end-to-end platform.
- Data Ingest: The Azure Data Factory (ADF) has 90+ standard connections for various data sources. It contains data collection at a centralized location for subsequent processing
- Mapping Data Flow: The ADF deploys data transformation using the graphical interface. It simplifies the configuration of source and destination tasks
- Azure Compute: The ADF can execute data-driven workflow without deploying the Azure resources. You can deploy an ADF service and start deploying various components and data integration
- Data Ops: The ADF can integrate with the GitHub and Azure DevOps to simplify managing data pipelines
- Monitoring: The ADF can integrate with the Azure Monitor, PowerShell, Azure portal health panel. This way, you can monitor execution progress with both scripts and the portal
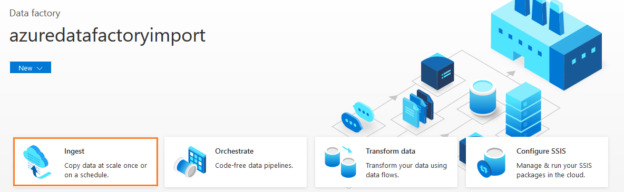
In the ADF dashboard, click on the Ingest to launch the copy data tool for data import and export.

For this article, we will use the Built-in copy task. In the task cadence, we use the default option – Run once now.

You can choose schedule or Tumbling window for additional scheduling configuration, as shown below.

Source Data Store configurations
In the source data store, choose the source type as HTTP. You can use this source for both HTTP and HTTPS URLs.

Click on New Connection. In the new connection (HTTP) window, specify a name, description (optional) and specify the CSV file Web URL in the Base URL section.

By default, it uses basic authentication that requires you to enter credentials for authentication to the data source.

For the Web URL, we do not require any credentials to access the CSV file. Before creating the connection, click on Test Connection to validate the connection to the Web URL.

Click on Create, and it returns to the source data store page with the base URL information.

Click on Next, and it launches the file format settings page.

You get an option – Detect text format. It automatically detects the file format, column delimiter, row delimiter. As shown below, it has automatically chosen option – First row as a header.

Click on the option – Preview Data. It opens a pop-up window and displays few data rows from the source. You can validate the data format. If it is not correct, you need to modify file format settings and preview data again.

In this preview data page, click on the schema to check the source data columns and their type. As shown below, it is using columns data type as a string.

Destination Data Source configuration
On the next page, choose the destination data source from the drop-down list. For this article, we choose Azure SQL Database.

Select the Azure SQL Database Server, database, authentication type, and enter the credentials for importing the data.

Once you create a destination datastore connection, it displays an additional configuration, as highlighted below.
- Source: HTTP file
- Target: Blank

This tool can automatically create the SQL table for you in Azure SQL Database. However, I recommend that you deploy the table based on source columns and their data types in advance. For this article, I have created a demo table with the varchar data type.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE DemoImport ( Variable varchar(2000), Breakdown varchar(1000), Breakdown_category varchar(2000), Year varchar(2000), RD_Value varchar(2000), Units varchar(2000), Footnotes varchar(2000) ) |
Create the table in your existing Azure SQL Database and click on the option – Use existing table. Instead of choosing the option – Auto-create a destination table with the source schema, choose the table from the drop-down list.

Here, we use the table [dbo].[DemoImport] for importing data from the CSV file stored in the Web URL.

On the next page, verify the column mapping between your source (CSV) and destination (SQL table). In the type column, it shows the source and destination columns data types.

If there are many mapping issues or columns left, click on the New mapping, and choose columns from source and destination. Enter the name of the configured copy tool task. The remaining options, such as Task description, fault tolerance, logging, are optional.

The summary page displays source and destination data source graphically. You can verify or modify the configurations if any.

Further step validates the copy runtime environment.

It does the following tasks.
- Create source and destination data sets
- Create pipelines
- Creates triggers
- Starts triggers
Click on finish and view pipelines runs. As shown below, its status is succeeded.

Hover your mouse over activity runs and click on details.
 It gives helpful information for monitoring the data flow. The information captured is as below.
It gives helpful information for monitoring the data flow. The information captured is as below.
- Data read: Total amount of data retrieved from the source data store, including data copied in this run and data, resumed from the last failed execution
- Files read: Total number of files copied from the source data store, including files copied in this run and files resumed from the last failed run
- Number of rows read
- Source peak connections: Peak number of concurrent connections established to the source data store during the Copy activity run
- Data written: The actual amount of data written/committed to the sink. The size may be different from data Read size, as it relates to how each data store stores the data
- Rows written: Number of rows copied to sink. This metric does not apply when copying files as-is without parsing them, for example, when the source and sink datasets are binary format type or other format types with identical settings
- Target Peak connections: Peak number of concurrent connections established to the sink data store during the Copy activity run
- Copy duration
- Throughput (KB per second)
- Used DIU – The effective Data Integration Units during the copy
- used parallel copies: The effective parallel Copies during copy
- Working duration in reading from the source – The amount of time spent retrieving data from the source data store
- Writing to sink – The amount of time spent on writing data to sink data store

You can connect to Azure SQL Database, validate the number of rows (14,946), and view the imported data.

Conclusion
This article explored the Copy Data tool of Azure Data Factory for importing data into Azure SQL Database using the Web source. ADS provides a quick solution for data import, export with various data sources and customizable pipelines. It eliminates the requirement of downloading files into the local directory and import them.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023