
This article will help you create database objects in Azure Data Lake Analytics using U-SQL.
Introduction
In the fourth part of this article series, Deploying U-SQL jobs to the Azure Data Analytics account, we learned how to deploy U-SQL jobs on Data Lake Analytics. So far, we learned the basics of how to query semi-structured or unstructured data using U-SQL as well as develop U-SQL jobs locally using Visual Studio. While processing large volumes of data stored in files is one way to process big data, there are use-cases where one may need to have structured views over semi-structured or structured data. This can be compared to query engines like Hive which provides SQL-like interface over unstructured data. Using constructs like Database, Tables, Views, etc. Azure Data Lake Analytics provides a mechanism to analyze files-based data hosted on Azure Data Lake Storage account using U-SQL as the Data Definition Language as well as the Data Manipulation Language. In this article, we will learn how to use U-SQL to analyze unstructured or semi-structured data.
U-SQL Data Definition Language
An easier way to understand structured constructs in Azure Data Lake Analytics is by comparing it to SQL Server database objects. U-SQL DDL supports database objects like schemas, tables, indexes, statistics, views, functions, packages, procedures, assemblies, credentials, functions, types, partitions and data sources. By default, Azure Data Lake Analytics comes with a master database. In the previous part of this Azure Data Lake Analytics series, we created a data lake analytics account, set up a visual studio and created a sample U-SQL application on sample data. It is assumed that this setup is already in place.
Let’s say that we intend to analyze file-based data hosted in the data lake storage account. The sample application that we setup comes with a sample file called SearchLog.tsv. This file can be opened from the Sample Data directory, and it would look as shown below in the File Explorer.

Open the script file titled CreatingTable.usql and you would find the script that creates database objects using U-SQL as shown below:
- Drop Database statement drops any existing database
- Create Database statement creates a new database
- Use the Database statement switches the context to the specified database
- U-SQL databases have built-in and default schema named dbo. Optionally one can create additional schemas as well
- Create Table statement creates a new table, which provides a database management system-level optimization in comparison to file-based data analytics. Behind the scenes, data in U-SQL Tables are stored in the form of files. There are two types of tables in U-SQL: Managed tables and External tables, which host data natively or externally in an external data repository respectively. The below example shows the DDL to create a managed table
- The INDEX keyword in the table definition is specified to create a new index
- CLUSTERED keyword specified the types of index and the fields on which the index should be created
- DISTRIBUTED BY specified the keys or values on which the data in the table should be distributed

Scroll down the script, and you would find the EXTRACT statement that reads this data from the file stored in the data lake storage account. After reading the data from the required fields, data is loaded into the newly created table using the INSERT command as shown below:

Start the job execution, and you would find the job graph as shown below. The different steps in which the table is created, data is extracted and then the same data is populated in the newly created tables is shown in three different steps in the job graph.

Once the job execution is completed, you would find the job graph status in green as shown below. If you navigate to the Azure Data Lake Analytics Explorer window and explore the account, under the U-SQL databases section, you would find the newly created table as shown below. If you expand the table, you would also be able to view the different fields.

To preview the data that we populated in this table, right-click the table and you would find the Preview menu option as shown below. Click on this option to preview the data.

A new window opens-up that would show the count of rows, columns and partitions, as well as actual data as well. As shown below, we can see that there are 23 rows and 7 columns in this table:

Now that the data is stored in a structured table format, if we intend to query this data, we do not need to use the Extract command and any extractor extensions to read this data. We can read this using the standard and simple U-SQL statement – SELECT. Open the script file named SearchLog – 5 – Query Table as shown below. It has the scripts that would read the data from the newly created table and write the output back to the Azure Data Lake Storage account. Let’s understand this script step by step:
- In the first SELECT statement, it reads data from the newly created table, groups it by Region field, sums the duration for each region using the Sum function, and populates the output in the table variable rs1
- In the second SELECT statement, it sorts the data by the TotalDuration field created in the previous step and select the top five rows using the FETCH statement, and populates the result in the variable @res
- In the last statement, using the OUTPUT command, it writes the data from the previous step to the Azure Data Lake storage account in CSV format using the CSV outputters extension (similar to CSV extractor extension), and ordered by TotalDuration field in descending order

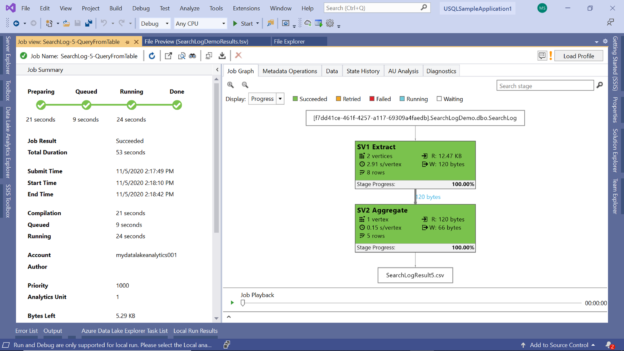
If you execute this job, the job graph would look as shown below. One step is for extracting and grouping the data and the other step is for fetching the five rows, which can be seen in the metrics of each step. Finally, the result is written to a file named SearchLogresult5.csv as shown towards the end of the job graph.

After the job completes, navigate again to the Azure Data Lake Analytics explorer, and preview the file. When you open the file, it would look as shown below. It has two fields and five rows as expected.

In this way, we can build structured objects and views in Azure Data Lake Analytics and populate it from the unstructured or semi-structured data stored in the Azure Data Lake Storage layer. Once the data is stored in these objects like tables or accessible through objects like views, we can use SQL like statements and functions over it. And whenever required, the required data can be written back to the Azure Data Lake Storage account.
Consider referring to the U-SQL language reference from here, to explore the syntax and details of how you can create database objects like Tables and Indexes using DML commands, and select as well as export data using DML commands using U-SQL in Azure Data Lake Analytics.
Conclusion
We learned the concept of structured database objects in Azure Data Lake Analytics. Then we briefly looked at a few DDL and DML commands and statements using which we created these objects. We read data from a file stored in data lake storage and populated these objects with this data. We also learn how to filter, group and sort the data stored in the tables, which are some of the most frequently used operations on a database object. We executed these scripts and learned the type of job graph and steps that get generated during script execution. And then we explored the file output using Azure Data Lake Explorer.
Table of contents

He has worked internationally with Fortune 500 clients in various sectors and is a passionate author.
View all posts by Rahul Mehta
- Finding Duplicates in SQL - February 7, 2024
- MySQL substring uses with examples - October 14, 2023
- MySQL group_concat() function overview - March 28, 2023