
In this article, the latest in our series on Common table expressions, we’ll review CTE SQL Deletes including analyzing the operation before the delete, actually removing the data as well as organizing and ordering the deletes with CTEs.
Due to the possible complexity with delete transactions, SQL CTEs (common table expressions) may offer us a tool to help increase our thoroughness. Reversing an insert results in a delete, while reversing an update results in a counter-update, but reversing a delete statement requires that we have a copy of the records prior to removing them. We want to take extra care when running delete transactions, especially in environments where we cannot be offline to restore data. We’ll look at running delete transactions with SQL CTEs alongside considerations about where they can be useful in organization, performance and minimizing errors.
Before the delete
Before running any delete transaction, unless we have a specific process flow to follow, we should always save a copy of the data and, if unused, remove that copy of the data at a later time. One reason for this is that we may have a very large database, remove 150 records in that database, but without a copy of the data, be forced to restore a copy of the same database to get 150 records. Even with using a tool like common table expressions to minimize errors, we still want to develop for experiencing errors. I’ve seen restores for databases over a terabyte occur because fewer than 10,000 records were needed following a bad delete transaction.
In our below code for our pre-delete step, we first save a copy of the data we’ll be removing to a new table that has an extension that we’ll be dropping (in this specific example, _DropTable). Because we’ll be deleting the winter months of December, January and February, I’ve also added _Winter in the name. Next, we see the code and an image of our job step that goes through and removes tables with this extension after a week. This only shows an example of considering reversal steps with deletes, because reversing a delete is more complex than reversing an insert or update on the data retrieval side.
|
1 2 3 4 5 6 7 8 9 10 |
SELECT * INTO tbAlmondData_Winter_DropTable FROM tbAlmondData WHERE MONTH(AlmondDate) IN (12,1,2) SELECT [name] ,[create_date] FROM sys.tables ORDER BY [create_date] DESC |

We see in the sys.tables our new table name.
|
1 2 3 4 5 6 7 8 9 |
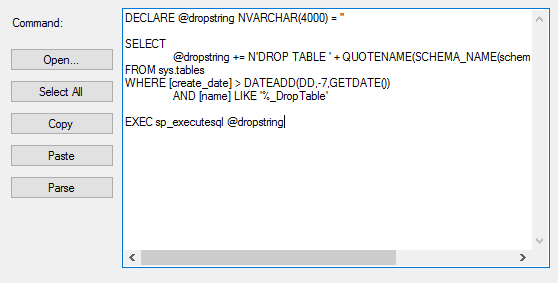
DECLARE @dropstring NVARCHAR(4000) = '' SELECT @dropstring += N'DROP TABLE ' + QUOTENAME(SCHEMA_NAME(schema_id)) + '.' + QUOTENAME([name]) + ' ' FROM sys.tables WHERE [create_date] > DATEADD(DD,-7,GETDATE()) AND [name] LIKE '%_DropTable' EXEC sp_executesql @dropstring |

Our job step removes all tables with the extension _DropTable after a week of their creation.
One important point here is that the extension _DropTable may be a legitimate extension in some environments, so for these environments, we would use other extensions like _ToBeDropped, _ToBeRemoved, etc.
Removing data with SQL CTEs
Once we have our data backed up, we can proceed to remove our data. We will wrap our delete with a begin and commit transaction to restrict access while the delete is performing and name our transaction. Following the format we’ve used with naming common table expressions, we’ll keep the name relative to what we’re doing – removing the winter months. In addition to querying the set of data before we run a delete, we can see how a fat finger mistake can be avoid here, like an accidental run of a delete statement without a where clause – the CTE in SQL Server inherently requires that we write the wrapped query first since the delete transaction is based off wrapped query.
|
1 2 3 4 5 6 7 8 9 10 11 |
BEGIN TRAN DeleteWinter ;WITH RemoveWinter AS( SELECT * FROM tbAlmondData WHERE MONTH(AlmondDate) IN (12,1,2) ) DELETE FROM RemoveWinter COMMIT TRAN DeleteWinter |


If we run the wrapped query following the delete, we’ll see no records return since the 92 winter months were removed.
Because deletes can be costly to restore, I suggest re-using the select query we used in the back-up select, as this in intuitive when the script is reviewed (if applicable). Also, with deletes I prefer to get as much information about what I’m removing to reduce the likelihood of an accidental removal.
If we discovered that we need to return our data back to our table, we could quickly reverse our removal using inverse logic:
|
1 2 3 |
INSERT INTO tbAlmondData SELECT * FROM tbAlmondData_Winter_DropTable |
Since we saved all the data we removed in full within this backup table, we can do a full insert to restore the data.
Ordered and organized deletes with SQL CTEs
Since common table expressions can assist us with organization of data, especially organizing data in groups within larger groups, we can apply this feature with removing duplicate values and removing values within smaller groups of data. For our starting example, we’ll re-insert the data we removed and we’ll do it twice – inserting duplicate winter records in our tbAlmondData.
|
1 2 3 4 5 6 7 8 |
---- Run this transaction twice INSERT INTO tbAlmondData SELECT * FROM tbAlmondData_Winter_DropTable SELECT * FROM tbAlmondData ORDER BY AlmondDate ASC |

Duplicate winter month data.
When we run a count of dates and group by the date, we see that our winter months have two records in them. For this example, we’ll assert that our AlmondDate is a primary key (though we are allowing duplicates for an example removal) in that only one unique record should exist in the table.
|
1 2 3 4 5 |
SELECT AlmondDate , COUNT(AlmondDate) CountDates FROM tbAlmondData GROUP BY AlmondDate |

The AlmondDate records with their count totals.
Next, we’ll order our data using a select query inside a common table expression that we won’t finish yet to see what our output will look like. Since we want to removed the ordered data that show a duplicate id (in this case, 2), we’ll create a query with the ROW_NUMBER function that divides and orders our data by the AlmondDate column. Because we’re dividing this column into partitions based on the value, we will see an Id of two if there is another identical record in the table. This is key because it applies to multiple columns, if the duplicate record has multiple values duplicated.
|
1 2 3 4 5 6 7 |
;WITH RemoveDupes AS( SELECT ROW_NUMBER() OVER (PARTITION BY AlmondDate ORDER BY AlmondDate) Id , * FROM tbAlmondData ) ---Unfinished: use the inner select statement |

We see a value of 2 for records that appear again.
Since we don’t want to remove original records as that would remove values with only one record (records with only an ID of 1), we will remove the rows that have a ID value of 2.
|
1 2 3 4 5 6 7 |
;WITH RemoveDupes AS( SELECT ROW_NUMBER() OVER (PARTITION BY AlmondDate ORDER BY AlmondDate) Id , * FROM tbAlmondData ) DELETE FROM RemoveDupes WHERE Id = 2 |
When we run the transaction, we see that 92 records were removed and if we run the select statement again from inside the wrapped query, we see only values of 1 for the Id.

All values with an Id of 2 have been removed.
We see with the common table expression that values have been removed from the underlying table – like we’ve seen with updates. We run a delete against a CTE in SQL Server and the table’s values are affected – this differs from taking data from a table to a temp table and removing data from the temp table. The source table still has the records. This logic does not carry over to using these with joined delete statements. In the below code, we run two delete statements that we rollback – one uses a join that selects one table’s data within a SQL CTE while the other performs a delete operation with the same join on the one table. The delete with the common table expression throws an error that communicates to us about underlying tables being affected, even though we see only tbAlmondData is affected by the delete. By contrast, we can run a delete with the same join without the SQL CTE that also deletes only from tbAlmondData. The second transaction is a direct delete against tbAlmondData based on the join statement.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
BEGIN TRAN ;WITH CauseError AS( SELECT t.* FROM tbAlmondData t INNER JOIN QuarterTable tt ON tt.QuarterId = DATEPART(QUARTER,t.AlmondDate) ) DELETE FROM CauseError DELETE FROM tbAlmondData FROM tbAlmondData t INNER JOIN QuarterTable tt ON tt.QuarterId = DATEPART(QUARTER,t.AlmondDate) ROLLBACK TRAN |

Even with one table’s data in the delete statements, this will not remove data.

The latter delete statement runs (rolled back).
While we can use SQL CTEs to minimize errors in situations where an error causes significant cost, like in the case of deletes, we still may not be able to use them in some circumstances. In these situations, we may prefer to design for automatic removal using cascades where referenced rows are removed automatically.
Conclusion
Deletes can be a costly operation as they can take more effort to reverse. Using caution by saving the data we plan to remove conveniently (and having automation in place to remove these backups automatically if they remain unused) along with carefully crafting a delete statement will ensure that we avoid situations where we have to spend resources on undoing a delete. As we see, SQL CTEs can offer us an intuitive tool to run delete statements and considering the ease of ordering data with them, they may be a tool that helps us smoothly remove records. Like with inserts and updates, if the performance is the same or better than alternatives, we may choose to use this route.
Table of contents
| CTEs in SQL Server; Querying Common Table Expressions |
| Inserts and Updates with CTEs in SQL Server (Common Table Expressions) |
| CTE SQL Deletes; Considerations when Deleting Data with Common Table Expressions in SQL Server |
| CTEs in SQL Server; Using Common Table Expressions To Solve Rebasing an Identifier Column |

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020