

Common table expressions (CTEs) in SQL Server provide us with a tool that allows us to design and organize queries in ways that may allow faster development, troubleshooting, and improve performance. In the first part of this series, we’ll look at querying against these with a practice data set. From examples of wrapped query checks to organization of data to multiple structured queries, we’ll see how many options we have with this tool and where it may be useful when we query data.
Test Data Set
The data set in these examples I use queries 362 values of a date range between December 1988 to January 2019 of almond values measured by a unit of output. The “AlmondValue” is not important to this tip, while the dates are for the examples. Any monthly stored values will work for these exercises with table name and column name substitutions. For readers who may want to copy queries directly, I’ve provided the below loop which will create these values for you to run these examples – the AlmondValue and Base10AlmondValue will differ in the output when you run these query examples, but the logical design of each query in the examples won’t.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TABLE tbAlmondData (AlmondDate DATE, AlmondValue DECIMAL(13,2)) DECLARE @startdate DATE = '1988-12-01', @value DECIMAL(13,2) WHILE @startdate <= '2019-01-01' BEGIN SET @value = ((RAND()*100)) INSERT INTO tbAlmondData VALUES (@startdate,@value) SET @startdate = DATEADD(MM,1,@startdate) END SELECT MAX(AlmondDate) LatestDate, MIN(AlmondDate) EarliestDate, COUNT(AlmondDate) CountofValues FROM tbAlmondData |

The Basics of CTE and Select Statements
The basic part of a common table expression is that we can wrap a query and run CRUD operations with the wrapped query. Let’s look at a simple example of wrapping a query and changing column names, then selecting from these new columns. In the below image, we’ll see the highlighted CTE in SQL Server, even though we ran the full query and this shows a quick debugging option that we have – we can select the wrapped query to do a quick check before running the query and this is very useful with CRUD operations that require validation, or where we may be trying to debug a transaction and need to run the first part of a statement that our CRUD operation will run again. This is an important part a CTE in SQL Server: what we see in the wrapped query is what our operation is applied against; in this case, a select statement.
|
1 2 3 4 5 6 7 8 9 10 |
;WITH GroupAlmondDates AS( SELECT YEAR(AlmondDate) AlmondYear , AlmondDate , AlmondValue , (AlmondValue*10) Base10AlmondValue FROM tbAlmondData ) SELECT * FROM GroupAlmondDates |


One important point when creating these is that we will get an error if we don’t explicitly name our columns in the wrapped query. Let’s take the same above example and see the error when we remove the column name AlmondYear in the wrapped query:
|
1 2 3 4 5 6 7 8 9 10 |
;WITH GroupAlmondDates AS( SELECT YEAR(AlmondDate) , AlmondDate , AlmondValue , (AlmondValue*10) Base10AlmondValue FROM tbAlmondData ) SELECT * FROM GroupAlmondDates |

This is a derived column, meaning that it comes from the values within another column, but as we see, a name is required. We can alternatively create the names explicitly and ignore naming the columns in the wrapped query and the explicit names will override any column name in the query – though I prefer to name in the wrapped query for faster troubleshooting purposes. Notice what happens to the explicit name of Base10 versus Base10AlmondValue.
|
1 2 3 4 5 6 7 8 9 10 |
;WITH GroupAlmondDates (AlmondYear,AlmondDate,AlmondValue,Base10) AS( SELECT YEAR(AlmondDate) , AlmondDate , AlmondValue , (AlmondValue*10) Base10AlmondValue FROM tbAlmondData ) SELECT * FROM GroupAlmondDates |

We see the Base10 in the output, so if we have a mixture of explicit column names that differ from the column names within the wrapped query, we should remember to use the explicit column names in references.
Another technique we can use with common table expressions is creating multiple CTEs together, similar to creating multiple subqueries that reference other subqueries (a common query output from Entity Framework). Although we can do this, this does not mean these are the most optimal solution, relative to what we’re trying to query. In the below query, we use a combination of these to query our data like we’ve queried above this, and in the second CTE, we look at the average of the AlmondValue for the year. From there, we join the GroupAlmondDates with GetAverageByYear on the AlmondYear and compare the AlmondValue with the average of the year. Our join here allows us to avoid creating another independent common table expression and save to a table, or use a temp table through creating a table, saving data, then removing it later.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
;WITH GroupAlmondDates AS( SELECT YEAR(AlmondDate) AlmondYear , AlmondDate , AlmondValue , (AlmondValue*10) Base10AlmondValue FROM tbAlmondData ), GetAverageByYear AS( SELECT AlmondYear , AVG(AlmondValue) AvgAlmondValueForYear FROM GroupAlmondDates GROUP BY AlmondYear ) SELECT t.AlmondDate , (t.AlmondValue - tt.AvgAlmondValueForYear) ValueDiff FROM GroupAlmondDates t INNER JOIN GetAverageByYear tt ON t.AlmondYear = tt.AlmondYear |

This can be a useful technique provided that we consider we can’t troubleshoot the GetAverageByYear in the way that we can with GroupAlmondDates – meaning that we can’t highlight the wrapped query in the second CTE since it requires the first to exist. Should we use combinations? Sometimes, provided that debugging is either not required (intuitive design) or it’s the only option we have that performs the best.
In our next few queries, we’ll apply two SQL Server functions – ROW_NUMBER() and DENSE_RANK() – to view how we can extend analysis in our select statement. Both of these functions involve ordering data, one which orders rows of data by the row number of the data demarcated with the order by clause and the other which ranks data delineated with the order by clause. In the below code, I order five date combinations using descending and ascending with some of these – the row number of the date, the row number of the date specified by the year of the date, and the rank of the year.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
;WITH GroupAlmondDates AS( SELECT ROW_NUMBER() OVER (ORDER BY AlmondDate DESC) DateDescId , ROW_NUMBER() OVER (ORDER BY AlmondDate ASC) DateAscId , ROW_NUMBER() OVER (PARTITION BY YEAR(AlmondDate) ORDER BY YEAR(AlmondDate) ASC) YearAscId , DENSE_RANK() OVER (ORDER BY YEAR(AlmondDate) DESC) YearOrderedDescId , DENSE_RANK() OVER (ORDER BY YEAR(AlmondDate) ASC) YearOrderedAscId , YEAR(AlmondDate) AlmondYear , AlmondDate , AlmondValue , (AlmondValue*10) Base10AlmondValue FROM tbAlmondData ) SELECT AlmondYear , AlmondDate , DateDescId , DateAscId , YearAscId , YearOrderedDescId , YearOrderedAscId FROM GroupAlmondDates |

An overview of what we’re seeing in the above output:
- DateDescId/DataAscId: we see that we have 362 records because we’re getting the row number by the AlmondDate column. The DateAscId orders the date from 1 to 362, while the DateDescId orders the date from 362 to 1
- YearAscId: these fields are ordering the rows by date of the year. Because these are monthly values, starting in 1989, we see the order matching the months for the. Since there is only one month in 1988, we see the YearAscId of 1 before it starts over at the beginning of 1989
- YearOrderedDescId/YearOrderedAscId: this orders the years by their group – for an example, 1988 and 1989 are in different groups (ranks) – rank 32 and 31. We can see that we have a total number of 32 years
Ordering and partitioning values like this can provide us with tools to organize our data to apply mathematical functions, get values of data from sets within sets, etc. Using the same data set, suppose that we wanted to know what the median almond value of the first four years 1988, 1989, 1990, 1991 was. Since we know that we have 1 value in 1988 and 12 values in each of the other years, we’d need to find the 19th value. Using a derivative of the above common table expression (removing unnecessary columns and adding the value), we can get this value:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
;WITH GroupAlmondDates AS( SELECT ROW_NUMBER() OVER (ORDER BY AlmondDate ASC) DateAscId , YEAR(AlmondDate) AlmondYear , AlmondDate , AlmondValue , (AlmondValue*10) Base10AlmondValue FROM tbAlmondData ) SELECT * FROM GroupAlmondDates WHERE DateAscId = 19 |

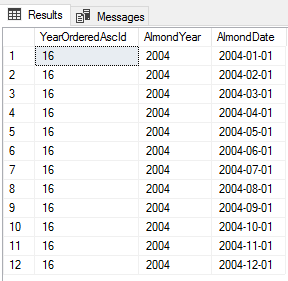
Using the order of our years from the previous query, we could get the average almond value of the median year from our years. In the below query, we filter out the 1988 date and get the median of the other 31 values, seeing that the year 2004 returns.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
;WITH GroupAlmondDates AS( SELECT DENSE_RANK() OVER (ORDER BY YEAR(AlmondDate) ASC) YearOrderedAscId , YEAR(AlmondDate) AlmondYear , AlmondDate , AlmondValue , (AlmondValue*10) Base10AlmondValue FROM tbAlmondData WHERE AlmondDate > '1988-12-31' ) SELECT YearOrderedAscId , AlmondYear , AlmondDate --AVG(AlmondValue) AvgAlmondValue FROM GroupAlmondDates WHERE YearOrderedAscId = 16 |

I’ve left the average value commented out so that we see the data set that we would be running our average value. We can use this same logic for other aggregates where we may want an aggregate for a specific year based out of the data set, like median is the middle of a data set.
Conclusion
As we see, common table expressions (CTE in SQL Server) can provide us with a convenient way to query data similar to using tools like temp tables and subqueries. We have quick troubleshooting options with these where we can run select statements inside the wrapping of the CTE and we can create multiple statements to join together. Are these faster? In some cases, they may be, or they may be faster to troubleshoot – which could be important. Still, we should always test our queries to ensure that the way we’re running our query is the most optimal route.
Table of contents
See more
To boost SQL coding productivity, check out these SQL tools for SSMS and Visual Studio including T-SQL formatting, refactoring, auto-complete, text and data search, snippets and auto-replacements, SQL code and object comparison, multi-db script comparison, object decryption and more


He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020