
Introduction
Amazon offers managed database service for various database products such as Microsoft SQL Server, MySQL, PostgreSQL, Oracle. In these relational database services (RDS), AWS manages the operating system, networking components, backups, monitoring solutions. In the previous articles, we explored many useful RDS features under the AWS RDS category on SQLShack.
Amazon Aurora is a variant for MySQL and PostgreSQL RDS platforms. Few useful features of Aurora MySQL are as below:
- Performance:
- Up to 5 times throughput for MySQL
- Up to 3 times throughput for the PostgreSQL
- Availability and Durability
- It provides 99.99% availability of the database environment
- The Storage for Aurora replicates across 4 availability zones and provides 6 copies of data
- It continuously takes database backups and stores into the S3 bucket for data restoration requirements
- The cluster volume in the Aurora grows up to 128 tebibytes size
- You can get a point-in-time recovery for your databases
- Aurora allows configuring up to 15 read replicas with very low latency
- You can span an Aurora database across multiple AWS regions for higher availability
- Security
- Multi-layers of security. It encrypts the underlying storage as well as the Aurora instance
- It uses AWS key management services ( KMS) for data encryptions
- Compatibility
- Aurora is compatible with existing client tools, code and applications available for MySQL and PostgreSQL
- You can convert your existing AWS RDS for MySQL and PostgreSQL into Aurora
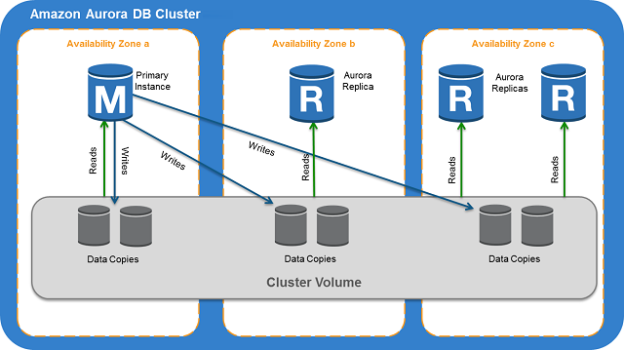
Amazon Aurora DB clusters components
Before we implement an Aurora cluster, let’s understand the high-level architecture and components of Aurora.
In the below image (Reference: AWS documentation), we can note down the following components.

- We have a primary instance and multiple Aurora replicas
- The primary instance serves the reads and writes requests, whereas the aurora replicas are for read-only purposes
- All the cluster replicas connect with the same storage volume. The storage volume uses solid-state drives (SSDs) for high performance and durability
- All the data copies across separate availability zones are fully synchronized with each other
- The read replicas are in separate availability zones; it provides high availability for your Aurora cluster
- These cluster volumes can grow up to 128 tebibytes however AWS charges you for your actual storage usage. It automatically expands or shrinks the volume size based on the activity. for example, if we delete a large table that frees much space, then Aurora shrinks the volume. It provides a cost-effective solution for you
Deploy your first AWS RDS Aurora database clusters for PostgreSQL
Log in to the AWS console with your AWS credentials and look for RDS under Services.

In the RDS dashboard, on the top, you see a link to Create database.

In the create database wizard, select the following options.
- Choose Standard create so that you can configure all required parameters for the Aurora cluster
- In the Engine option, choose Amazon Aurora

Edition
- For MySQL compatibility, use Amazon Aurora with MySQL compatibility
- For PostgreSQL compatibility, use Amazon Aurora with PostgreSQL compatibility

Capacity Type
To create the Amazon Aurora cluster, we can either use the Provisioned or Serverless configuration.
- Provisioned: Here, we specify the server instance sizes such as t2.medium. Based on the instance category, servers have the CPU, RAM allocations
- Serverless: In the Serverless capacity, we define the minimum and maximum resources. Aurora allocates and scales the resources automatically based on the workload

Replication features
Once you select the MySQL compatibility with Amazon Aurora, the console lists out the replication features.

- Single Master: In the high-level architecture of Aurora, we look at a single master ( for read and write) and multiple aurora replicas
- Multi-Master: Aurora also supports multiple writes instances. These multiple writes are connected to the same storage and servers both read, write requests
In this article, we go with the Single Master configuration for the Aurora cluster.
Engine Version
In the engine version, you select the Aurora version. We go with the default version however if you are looking for a specific feature, you should check its compatible version and select it from the drop-down.

Templates
Choose the template from the production or Dev/Test. By choosing a template, it prefills the curtains parameters automatically for you.

DB Cluster Settings
- DB Instance identifier: Specify a name for your Amazon Aurora cluster. In this article, I specify [MyAuroraCluster] identifier
- Master user name and password: By default, Aurora creates the master user with the specified password

DB Instance Size
Previously, we use the previsioned capacity for Aurora clusters, therefore choose the DB instance class. The AWS console shows the CPU, Memory and network speed with each instance class in the drop-down menu.

Availability & durability
As highlighted earlier, Aurora supports up to 15 replicas in the separate availability zones. Currently, we do not configure a read replica. Therefore, it creates the aurora cluster with a primary instance and without any read replicas.

Connectivity
In the connectivity section, we can create a new or choose an existing VPC, Subnets, security groups. We go with default options in this article.
If you want to have public accessibility for your Aurora cluster, you choose Public access as Yes.
By default, Amazon aurora works on port 3306, as shown below.

Database authentication
For the database authentication, we can use Password authentication or Password and AWS IAM database authentication. In the IAM authentication, you can allow your IAM users to connect with the Aurora instance for your database queries.

Additional Configuration
Here, we can specify a few additional configurations for your Amazon Aurora cluster.
- Initial database name: You can specify a database name to create with the Aurora cluster creation
- DB cluster parameter group and options group: AWS RDS uses options and parameter groups for Aurora configurations
- Failover priority: By default, Aurora does not set any preference for automatic failover. Suppose you have 4 replica clusters, you can set a failover preference for any specific replica

Backup
Amazon Aurora also takes regular database backups similar to the RDS instances. Its maximum backup retention period is 35 days.
Encryption
As specified earlier, Amazon Aurora is a secure database, and it uses encryption using the AWS key management keys.

Monitoring
By default, AWS enables the enhanced monitoring for the Aurora cluster and databases with a Granularity of 60 seconds.

Maintenance
- Enable auto minor version upgrade: If this option is checked, AWS automatically upgrades the minor during the maintenance window
- Deletion protection: It prevents your database from accidental drops. If you enable the option, you cannot delete the aurora cluster and replica

Now, click on Create database and shows you the progress in the RDS dashboard. At the top, you get the option to view the credentials. If you use automatic passwords for the master user, you can click on it and copy the password.
- Note: It is the only time you can view the credentials for the master user. If you forgot the credentials, you require to reset it.

It takes some time for the Aurora cluster to be in the available state. In the below image, we see an aurora cluster with the primary replica.

Click on the cluster name [MyAuroraCluster], and you get endpoints for reader and writer.

You also get an endpoint for the primary replica. We use the endpoint to connect with the Aurora cluster database.

Add a reader replica in the existing aurora cluster
In the AWS Aurora cluster configured above, we have a single replica that servers the role of reader and writer. We can configure up to 15 readers in Aurora. Select the cluster and go to Actions. In the actions menu, click on Add reader.

In the reader configuration page, specify the following inputs.
- Aurora replica source: The AWS console automatically fills the cluster information in the aurora replica source
- DB instance identifier: It is the name of your aurora reader instance
- DB instance size: Select the DB instance size for your aurora reader replica. For production instance, you should use Memory-optimized class

The remaining configurations are the same as deploying an RDS instance. Review the information and click on Add Reader.

It starts the Aurora reader configuration for your cluster.

You can note the availability zone of your reader and write aurora instance.

You can add multiple aurora readers (up to 15) similarly. In the below image, note the availability zones
- Writer: us-east-1d
- Reader: us-east-1a & us-east-1b

Conclusion
In this article, we deployed the AWS Aurora cluster with a single writer instance. Later, we added another replica for the reader role in the different availability zone. In the next article, we will explore a few useful features of aurora clusters.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023