
In this article, we will learn how to develop ETL templates for data warehousing using Azure Data Factory.
Introduction
Azure cloud platform offers a variety of data services that include different types of data repositories ranging from relational databases, NoSQL databases as well as data warehouses. As the data ecosystem grows organically from transactional databases, there comes a need for data warehousing or building data lakes to consolidate data of different types for analytics and reporting. A natural approach to solve this scenario is to start building ETL pipelines that move data from source systems i.e. typically transactional databases like Azure SQL Database, Azure Database for PostgreSQL, Azure Database for MySQL, CosmosDB and others to data warehousing services like Azure Synapse Analytics which hosts serverless SQL pool, dedicated SQL pool as well as spark pools.
The Azure service that facilitates developing data pipelines to perform Extract-Transform-Load (ETL) or Extract-Load-Transform (ELT) functions is typically developed using Azure Data Factory as the first approach option. The type of transform for different ETL pipelines may differ depending on what type of data comes from the source system and the nature of destination fact or dimension in a data warehouse, but the overall data flow of reading data from multiple sources, joining and/or merging and/or transforming this data and loading it in the data warehouse repository remains the same. An ETL pipeline template or data flow template that provides the most basic or most frequently used functions in this style of pipelines can become a reusable asset for an ETL team where developers can just clone the template of the data flow or data pipeline and start customizing it instead of starting from scratch. In this article, we will learn how to develop such data flows and use the same in a data pipeline using Azure Data Factory.
Pre-Requisites
It is assumed that one has sufficient privileges on Azure Data Services on their Azure account. In this exercise, we are going to use Azure SQL Database and Azure Database for PostgreSQL as the source systems. So, the first thing we need is an instance of both database types with at least one table that hosts some sample data in it. These tables also need to have at least one attribute in common (for example an ID field) that can be used in our data flow to join these tables.
We need an instance of Azure Synapse Analytics with SQL pool and a destination table that has the same fields as source systems would be required as this would act as our destination. It is assumed that such an instance is in place as well.
Once source and destination are in place, we need an Azure Data Factory workspace instance created as that would enable us to use the Azure Data Factory portal where we would create our data pipelines and data flows to move and transform data from source systems to our data warehouse in Azure Synapse. Once the instance is created, the first thing we need to do is register the source systems and destination data warehouse in the Linked Services section of the Azure Data Factory portal as shown below. Creating a linked service to our data repositories means we are creating connections to data sources. Ensure that Azure SQL Database, Azure Database for PostgreSQL, and Azure Synapse are registered using the linked services option.

Developing a Data Flow to move data using Azure Data Factory
Navigate to the Author tab, click on the Data flows, and select the New data flow menu option as shown below.

This will open a new layout to develop the data flow as shown below. By default, the data flow debug option is switched off. Turn it on as shown below. It will require selecting the Auto Resolving Integration Runtime. Once you switch it on, it may take a few minutes to get activated. Meanwhile, provide a relevant name for the data flow in the properties section.

To publish a data flow successfully, we need a source and a destination typically in a data flow. We will start by clicking on Add Source button to add a new data source as shown below. We can specify the data source inline as well as we can select a dataset if one exists already. In this case, we have a dataset available that has been used in a different pipeline or data flow. We can select the same from the dataset dropdown. Provide a relevant name for this data source as well to make it explicit that the source system here is Azure SQL Database.

Click again on the Add Data Source button to add a new data source. This time we can use the inline option and select Azure Database for PostgreSQL. Shown below are the supported types of inline data source options.

Follow the same steps that we followed for Azure SQL Database. Azure Data Factory provides several settings and options to configure and investigate the data source. Click on the Projection option to view the schema of the data source as shown below.

In Azure Data Factory, we have options to preview data in almost every type of object that we create to build a data pipeline as well as a data flow. Click on the Preview tab to see the data as shown below.

Once we have defined the source systems and tested that the connectivity is successful, we are ready to proceed to the next logical step in the data flow. Your layout should look like the one shown below once both data sources are configured in the data flow.

Click on the + sign and we should be able to view the different options that we can use to add to the data flow. Let’s say that we intend to merge or join the data from the two data sources. In that case, we will use the Join transform as shown below. Click on the same and it would get added to the data flow.

Now that we intend to join the two data sources in question, select one of the data sources in the left stream, the other in the right stream, and specify the join condition that suits your data model and destination data object schema. We can also preview the data to check how the data will look like once the join transformation is applied to the data from the two data sources.

The last logical step in the data flow is to add a new destination. In Azure Data Factory terminology, it is known as Sink. Add this to the layout as shown below.

We registered the Azure Synapse instance using the linked service earlier. We can use the same and configure the sink properties to point to the Azure Synapse instance and test the connectivity as shown below.
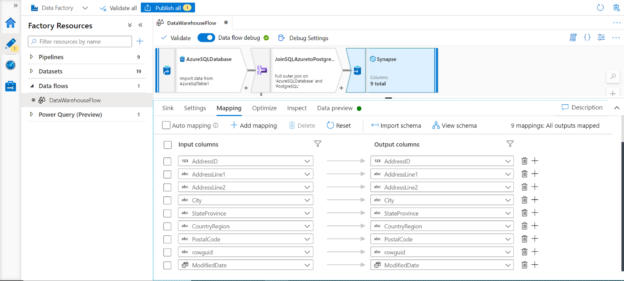
We can configure the mappings which would be mapped automatically if column names match. If you want to modify or view the mappings, uncheck the Auto mapping option and you would be able to see the mappings as shown below. We can also preview the data to ensure that the intended data would be loaded in the data warehouse.

Publish the changes and save this data flow. We can then create a new data pipeline, add a data flow component to the pipeline. The name should be something appropriate. We can save this data pipeline either as a template and then the future data pipeline can use this data pipeline that contains the flow related to a data warehouse, or alternatively, one can clone the data flow and use it as a template to create different data flows having common functions but different transforms for different dimensions or facts.

Point the data flow component to the data flow that we just created as shown below, and then the data pipeline is ready to be executed as required to perform the actual ETL operations on the data.

In this way, we can create a data flow and data pipeline that can be used as a template to move and transform data from source systems to data warehouses on the Azure cloud.
Conclusion
In this article, we sourced the data from two transactional databases, merged the same, and loaded it into Azure Synapse using data flow and data pipeline developed using Azure Data Factory.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023