
Introduction
In this article, we will be looking at how to perform and access Dynamic Data Masking in SQL Server. Data Masking is the process of hiding data with different rules. One of the main reasons to apply data masking is to protect Personal Identifiable Information (PII) and sensitive data from unauthorized access. Even when unauthorized users access these data, they will not be able to view the actual values. This article will look at the possibilities of applying Dynamic Data Masking in SQL Server and we will look at how Dynamic Data masking can be applied to the Azure SQL Databases as well.
Implementation of Data Masking
There are four types of Dynamic Data Masking in SQL Server as given below.
Default Masking
Default masking will be applied depending on the data type. For the string data type, it will be masked to ‘XXXX’. This is valid for the char, nchar, varchar, nvarchar, text and ntext data types. The value of numeric data types will be masked as 0. This is will be valid for bigint, int, smallint, tinyint, bit, decimal, money, numeric, smallmoney, float, real. All the date time data types such as date, datetime2, datetime, datetimeoffset, smalldatetime, time will be masked at 1900/01/01 00:00:00 etc.
Partial Masking
Partial Masking is custom masking that can be applied. In this masking type, you can customize the masking to satisfy your requirement.
Random Masking
Random masking will be done for the numeric values with a given range. When the value is retrieved unmask value will be a random value depending on the range that you have provided.
Email Masking
Email masking can be used to mask email addresses. This email address will be exposed the first letter will be replaced with the suffix by .com.
The following table shows how the mask will happen for different masking types.
|
Masking Type |
Sample Data |
Masked Data |
|
Default Mask |
Dinesh |
XXXX |
|
Partial |
Dinesh |
DXXXh |
|
Random |
32 |
1 |
|
|
Implementation of Dynamic Data Masking in SQL Server
Let us create a table with relevant masking functions as shown in the below table script.
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE EmployeeData (MemberID INT IDENTITY PRIMARY KEY, FirstName varchar(100) MASKED WITH (Function = 'default()'), LastName varchar(100) MASKED WITH (Function = 'partial(1,"XXX",1)'), Email varchar(100) MASKED WITH (function = 'email()'), Age int MASKED WITH (Function = 'default()'), JoinDate date MASKED WITH (Function = 'default()'), LeaveDays int MASKED WITH (FUNCTION = 'random(1,5)') ) |
Let us insert a few records into the table from the following script.
|
1 2 3 4 5 6 7 |
INSERT INTO EmployeeData (FirstName, LastName, Email,Age,JoinDate,LeaveDays) VALUES ('Dinesh','Asanka','Dineshasanka@gmail.com',35,'2020-01-01',12), ('Saman','Perera','saman@somewhere.lk',45,'2020-01-01',1), ('Julian','Soman','j.soman@uniersity.edu.org',37,'2019-11-01',1), ('Telishia','Mathewsa','tm1@rose.lk',51,'2018-01-01',6) |
Following is the dataset that was inserted from the above script.

Let us create a user to demonstrate data masking which has the SELECT permissions to the created data.
|
1 2 |
CREATE USER MaskUser WITHOUT Login; GRANT SELECT ON EmployeeData TO MaskUser |
Please note that the above user is created in order to demonstrate the masking feature.
Let us query the data with the above user.
|
1 2 3 |
EXECUTE AS User= 'MaskUser'; SELECT * FROM EmployeeData REVERT |
The following is the output as you can see that data is masked.

When you need to provide the UNMASK permissions to the above user.
|
1 |
GRANT UNMASK TO MaskUser |
Then the user will be able to view the data. You cannot grant column level UNMASK permissions to the users. If you want to hide the data, then you can grant DENY permissions for the relevant column for the user. However, there are no special permissions needed to create masked columns. You only need the CREATE TABLE permissions and ALTER column permission to create or alter mask column.
Further, if you want to find out what are the masked columns in the database, you can use the following script.
|
1 2 3 4 5 |
SELECT OBJECT_NAME(OBJECT_ID) TableName, Name , is_masked, masking_function FROM sys.masked_columns |
It will have the following output.

Implementing Dynamic Data Masking in Azure SQL
Like Dynamic Data Masking in SQL Server that was discussed before, Data Masking can be extended to Azure SQL Databases as well.
First of all, you need to have a subscription to Azure. Then let us create a database with a minimum DTU. In this database, we have used the Sample option so that we will have some sample data with AdventureWorksLT as shown in the below screenshot.

Following are the sample tables and views that are available with the created database.

Let us start with data masking in Azure SQL. Unlike Dynamic Data Masking in SQL Server, there is a user interface available in Azure SQL.
Dynamic Data Masking option available in Microsoft Azure Dashboards as shown below.

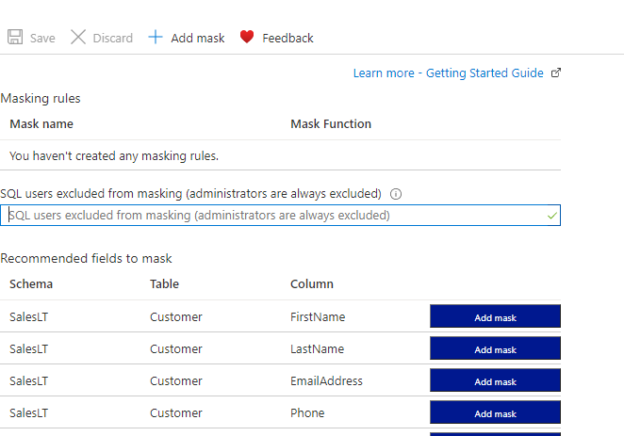
When you select the Dynamic Data Masking option, you will be taken to the following screen.

As you can see, there are recommended fields for masks. These columns are potential columns that are most suited for data masking. For example, Names, Addresses, Emails, Phone, Credit card columns are detected as potential data masking columns. This is again an important feature that will not be available in Dynamic Data Masking in SQL Server. You can add a mask from the provided blue colored button. This will add a default mask as we discussed before. With that, you will see following masking rules are updated as shown in the below screenshot.

Sometimes, default masking will not be possible to mask all the columns. You can add any other masking rules by clicking the add mask option.

In this screen, you can choose the schema, table and column in a filtering list as shown in the above screen. Next, you can choose the masking format.

As we experienced in Dynamic Data Masking in SQL Server, there is an additional data masking option named Credit card values. In this data masking option, credit card numbers will be replaced with XXXX and leave the suffix values. However, Credit card data masking is using partial data masking which is partial (0, “xxxx-xxxx-xxxx-“, 4).
In the provided options for Dynamic Data Masking, Default Value, Credit Card value and Email masking do not have any options. However, in Number (random number range) and custom string data masking options, you need to provide additional parameters.
When the Custom String data masking is selected, you need to provide three parameters as shown in the following screenshot.

In the above configuration, you need to provide, how many letters are exposed in prefix and suffix along with the padding string.
In the numeric column data masking option, you need to provide the range values that should be masked. This configuration is shown in the below screenshot.

Further, you can modify the existing Data Masking by changing the Masking type but you cannot modify other details such as Column name etc. As we did in Dynamic Data Masking in SQL Server, let us query the database to verify the masked data.
|
1 2 3 4 5 6 7 |
SELECT TOP 10 CustomerID, FirstName, LastName, EmailAddress, Phone, ModifiedDate FROM [SalesLT].[Customer] |

You can see that data is masked. However, it is important to note that, masking is not valid for WHERE or ORDER BY or GROUP BY clauses.
|
1 2 3 4 5 |
SELECT FirstName, COUNT(*) Number_of_Employees FROM [SalesLT].[Customer] GROUP BY FirstName ORDER BY FirstName |
Following is the output of the above query that shows that you can still process and only the output is masked.

This means that by doing multiple quires, there is a possibility of retrieving the original data.
Similar to Dynamic Data Masking in SQL Server, we can verify the columns that are masked by running the same query as before and the output is as follows.

This can be incorporated into all the columns by using the following query.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT OBJECT_NAME(c.OBJECT_ID) TableName, c.Name , c.is_masked, mc.masking_function FROM sys.masked_columns mc RIGHT OUTER JOIN sys.columns c ON mc.column_id = c.column_id AND mc.OBJECT_ID = c.OBJECT_ID INNER JOIN sys.objects O ON o.object_id = c.object_id WHERE o.type='U' |
The following is the output of the above query.

Conclusion
Dynamic Data Masking in SQL Server is a masking technique that can be used to hide data. This feature is available in SQL Server as well as in SQL Azure. There are four types of masking and UNMASK permission should be provided to the users in order to view the data. In Azure SQL, there is a user interface but you do not the user interface in SQL Server. In Azure SQL, there are five data masking types where there are four masking types in SQL Server. In Azure SQL, it will provide a list of recommended columns for masking.
References
- https://docs.microsoft.com/en-us/sql/relational-databases/security/dynamic-data-masking
- https://docs.microsoft.com/en-us/azure/azure-sql/database/dynamic-data-masking-overview

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021