
Objective
The real-life requirement
Disclaimer: I assume dear Reader, that you are more than familiar with the general concept of partitioning and star schema modeling. The intended audience is people who used to be called BI developers in the past (with a good amount of experience), but they have all sorts of different titles nowadays that I can’t keep up with… I won’t provide a full Visual Studio solution that you can download and just run without any changes or configuration, but I will give you code can be used after parameterizing according to your own environment.
So, with that out of the way, let’s start with some nostalgia: who wouldn’t remember all the nice and challenging partitioning exercises for OLAP cubes? 🙂 If you had a huge fact table with hundreds of millions of rows it was at least not an efficient option to do a full process on the measure group every time, but more often it was out of the question.
In this example, I have a fact table with 500M+ rows that is updated hourly and I created monthly partitions. It is a neat solution and the actual processing takes about 3-4 minutes every hour, mostly because some big degenerate dimensions I couldn’t push out of scope. The actual measure group processing is usually 1-2 minutes and mostly involves 1-3 partitions.
I know OLAP is not dead (so it is said) but not really alive either. One thing is for sure: it is not available as PaaS (Platform as a Service) in Azure. So, if you want SSAS in the Cloud, that’s tabular. I assume migration/redesign from on-premise OLAP Cubes to Azure Tabular models is not uncommon. In the case of a huge table with an implemented partitioning solution, that should be ported as well.
Where Visual Studio provided a decent GUI for partitioning in the OLAP world, it’s not the case for tabular. It feels like a beta development environment that has been mostly abandoned because the focus has been shifted to other products (guesses are welcome, I’d say it’s Power BI but I often find the Microsoft roadmap confusing especially with how intensely Azure is extending and gaining an ever growing chunk in Microsoft’s income).
In short: let’s move that dynamic partitioning solution from OLAP into Azure Tabular!
Goal
The partitioning solution should accommodate the following requirements:
- Based on a configuration table handle different granularity for partitions (monthly, annual, …)
- Identify currently existing partitions
- Create a list of required partitions (this is mostly used at initialization)
- Compare existing and required partitions: create / delete if needed
- Based on the new set of data (e.g. in a staging table) update/process the relevant partitions
- Keep logs of what should happen and what actually happens
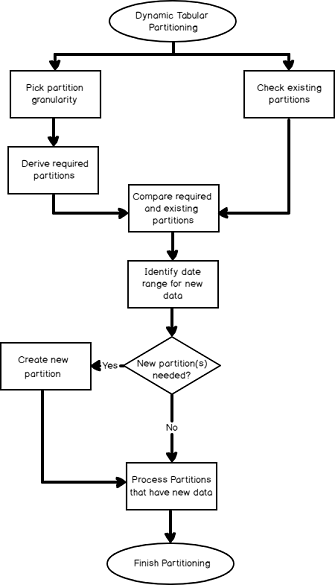
The process of Dynamic Partitioning

Used technology
My solution consists of the below components:
- SQL Server tables and stored procedures
- SSIS to orchestrate the process
-
Scripting (two options to choose from)
-
C# scripts inside SSIS utilizing TOM (Tabular Object Model) – used in this solution
No, the second one is not Jerry 🙂 I am not sure the two methods would get on well in that cat-mouse relationship…
- PowerShell using the Tabular Model Scripting Language (TMSL) where the objects are defined using JSON format
-
- Azure Analysis Services (secure connections to it)
Let’s get to it, going through the steps from the diagram one-by-one!
Dynamic Tabular Partitioning
Overview
The below objects are used in the solution.
| Object name | Type | Functionality |
| ETL_Tabular_Partition_Config | Table | Stores metadata for partitions that are used when defining the new ones |
| ETL_Tabular_Partition_Grain_Mapping | Table | A simple mapping table between conceptual partition periods (e.g. Fiscal Month) and the corresponding Dim_Date column (e.g. Fiscal_Month_Code), this allows to tune partitioning periods dynamically |
| Dim_Date | Table | A fairly standard, pre-populated date table |
| ETL_Tabular_Partitions_Required | Table | The master list of changes for partitions, including all that needs to be created / deleted / processed (updated) |
| pr_InsertTabularPartitionsRequired | Stored procedure | That’s the heart of the SQL side of dynamic partitioning (details below) |
| ETL_Tabular_Partitions_Existing | Table | A simple list of partitions that currently exist in the deployed database |
| pr_InsertTabularPartitionsExisting | Stored procedure | A simple procedure that inserts a row into ETL_Tabular_Partitions_Existing and is called from a C# enumerator that loops through the existing partitions of the tabular database |
| Tabular_Partition.dtsx | SSIS package | This SSIS package is used as an orchestration of the different components of the project. In this 1st step the pr_InsertTabularPartitionsRequired stored procedure is called |
Date configuration
For the date configuration, I use the ETL_Tabular_Partition_Config, the ETL_Tabular_Partition_Grain_Mapping and the Dim_Date table. A simplified version for demo purposes:

-
ETL_Tabular_Partition_Config
- This contains one row for each table in a tabular database assuming that only partitioning period is required (e.g. monthly), this can be further enhanced if needed
- Tabular_Database_Name and Table_Name are used to identify the objects on the server
- Partition_Name_Prefix is used in the naming of the partitions (e.g. Internet Sales – FY)
- Source_Object – fact table/view (used as the source of the tabular table)
- Partitioning_Column – the column in the source object that is the basis of partitioning (e.g. Transaction_Date_SK)
- Stage_Table / Stage_Column– these are needed to identify the data range of the incremental dataset that is waiting to be pushed into the fact object from staging
- Partition_Grain – the key piece in this exercise to define the periodicity of the partitioning process (e.g. Fiscal Month)
- Partition_Start_Date_SK / Partition_End_Date_SK – used as parameters to calculate the boundary for the list of partitions
- Partition_Start_Date / Partition_End_Date – calculated columns in the table as when it comes to dates it often helps to have them in surrogate key and in date format, too (the SK integer values are always unambiguous whereas the date values can be used in T-SQL date functions (e.g. EOMONTH or DATEADD) if needed)
-
ETL_Tabular_Partition_Grain_Mapping
- To find out how your conceptual partition grain (e.g. Fiscal Month) can be mapped to Dim_Date, i.e. what column in Dim_Date means that
- Partition_Grain is often a user-friendly name where Partitioning_Dim_Date_Column is more technical
- E.g. Fiscal Month and Fiscal_Month_of_Year_Code
-
Dim_Date
- If you have a data warehouse of any type, most likely it already contains one so why not use what’s already there? Especially that it can contain a lot of logic around your own company’s fiscal structure.
- You can create a temp table on the fly or can use built-in T-SQL date functions but that adds an unnecessary complexity to the procedure without any benefit
- I included some sample values in the table diagram (usually such examples don’t belong to an entity-relationship diagram) to show what I mean by them
- The relationship to Dim_Date is defined using dynamic T-SQL in the stored procedure (see next section)
Check Existing Partitions – script task
TOM – Tabular Object Model
I chose C# for this script’s language and the TOM (Tabular Object Model) objects are required to interact with tabular servers and their objects. To use them some additional references are needed on the server (if you use ADF and SSIS IR in the cloud, these are available according to the Microsoft ADF team) that are part of the SQL Server 2016 Feature Pack. You can find more info about how to install it here:
Install, distribute, and reference the Tabular Object Model
And the official TOM Microsoft reference documentation can be very handy:
Understanding Tabular Object Model (TOM) in Analysis Services AMO
The part that is related specifically to the partitions:
Create Tables, Partitions, and Columns in a Tabular model
Variables
The below variables are needed to be passed from the package to the script:
- Audit_Key (I use this everywhere, so each execution is logged separately)
- Tabular_Database_Name
- Tabular_Table_Name
- ConnStr_Configuration_Database – needed for the stored procedure that writes the results of the TOM script into t SQL table
- ConnStr_Tabular_Server – in my case I connect to Azure Analysis Services (it should work with an on-prem tabular server as well), multiple forms of authentication can be used (service principal with username/password in the connection string that is obtained from a key vault during runtime, Managed Service Identity, …), this is a quickly evolving area of Azure
Make sure you include the above variables, so they can be used in the script later on:

The syntax for referencing them (as it’s not that obvious) is documented here:
Using Variables in the Script Task
Main functionality
The script itself does nothing else but loops through all existing partitions and calls a stored procedure row-by-row that inserts the details of that partition into a SQL table.
- C# script – Identify existing partitions.TOM.cs (I removed all comments that SSIS puts there by default and please make sure you don’t just copy&paste it as the namespace ST_… (line 12) is different for your script task!)
- Stored procedure – pr_InsertTabularPartitionsExisting.sql
- Tables
SQL to sort out what to do with partitions
All this logic is coded into pr_InsertTabularPartitionsRequired (feel free to use a better name if you dislike this one) and in high level it does the following:

Gray means T-SQL, white is C# (see the previous section), dark grey is putting everything together.
Here is the code of my procedure, it works assuming you have the three tables defined previously and you configured the values according to your databases / tables / columns.
pr_InsertTabularPartitionsRequired.sql
It is mostly self-explanatory, and the inline comments can guide you as well. Some additional comments:
- Dynamic SQL must be used because the column that is used from Dim_Date cannot be hardcoded and that is part of the query that extracts the list of date periods from there
- The CREATE TABLE is defined outside the dynamic SQL otherwise the scope of it is limited to the execution of that dynamic code and then the temp table is cleaned out of memory thus not usable later in the procedure’s session
- I use EXECUTE sp_executesql @sql_string instead of EXEC (@sql_string) as best practice though in this case due to the low volume of data both perform satisfactorily but while there are good reasons to use EXECUTE sp_executesql instead of EXEC, the latter doesn’t really have any advantage apart from being quicker to type
- cte_partition_config – simply extracts the config data for the required tabular database and table
- cte_partition_required – the cross join is used to create as many rows with the config values as many partitions are needed, using the actual date-related information in the partition names. With a simple example: for monthly partitions in 2018 all the metadata for the tabular table needs to be read only once but the month values / descriptions are needed 12 times
-
Populate ETL_Tabular_Partitions_Required – a straightforward comparison between existing (see section 2) and required (or planned) partitions using some set theory
- If a partition doesn’t exist but is required => CREATE it
- If it is not required but exists => DELETE it
- If it’s both then (guess what?) it EXISTS 🙂 so at this point it can be left alone
Additionally, a WHERE clause for each partition is defined which can be used later when it is time to actually create them.
- List_Staging_Periods – this last step uses the config data to check what dates (usually that is the lowest level) exists in the data that is staged and was loaded into the final fact table/view to know which partitions need an update. E.g. if your incremental dataset has data only for the last 2 days and you are in the middle of the month, you only need to process the partition for the current month and leave the others as they are
Create new partitions / drop the ones not needed / Process
Again, back to the C# realm.
Code Confusion
One particular inconsistency caught me as I had to spend half an hour to figure out why removing a partition has a different syntax then processing. It might be totally straightforward with people having a .NET background but different than how T-SQL conceptually work.
|
1 2 3 |
Tabular_Table.Partitions.Remove(Convert.ToString(Partition["Partition_Name"])); Tabular_Table.Partitions[Convert.ToString(Partition["Partition_Name"])].RequestRefresh(RefreshType.Full); |
Conceptually
- Deletion – Collection.Action(Member of Collection)
- Process – Collection(Member of Collection).Action(ActionType)
Source query for new partitions
How to assign the right query for each partition? Yes, we have the WHERE conditions in the ETL_Tabular_Partitions_Required table but the other part of the query is missing which has the date filtering to ensure there are no overlapping partitions. For that I use a trick (I am sure you can think of other ways, but I found this next one easy to implement and maintain): I have a pattern partition in the solution itself under source control. It has to be in line with the up-to-date view/table definitions otherwise the solution can’t be deployed as the query would be incorrect. I just need to make sure it always stays empty. For that a WHERE condition like 1=2 is sufficient enough (as long as the basic arithmetic laws don’t change). Its naming is “table name – pattern”
Then I look for that partition (see the details in the code at the end of the section), extract its source query, strip off the WHERE condition and then when looping through the new partitions, I just append the WHERE clause from the ETL_Tabular_Partitions_Required table.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
string Tabular_Table_Name = "your table name"; string Tabular_Partition_Pattern_Name = Tabular_Table_Name + " - pattern"; //connect to tabular model var Tabular_Server = new Server(); string Tabular_ConnStr = "your connection string"; Tabular_Server.Connect(Tabular_ConnStr); Database Tabular_Db = Tabular_Server.Databases[Tabular_Database_Name]; Model Tabular_Model = Tabular_Db.Model; Table Tabular_Table = Tabular_Model.Tables[Tabular_Table_Name]; Partition Patter_Partition = Tabular_Table.Partitions.Find(Tabular_Partition_Pattern_Name); |
Note: I use SQL queries not M ones in my source but here’s the code that helps you get both types from the tabular database’s partition using .NET once you have identified the proper partition that contains the pattern:
For SQL
|
1 2 3 |
string Partition_Pattern_Query_SQL= ((Microsoft.AnalysisServices.Tabular.QueryPartitionSource) (Pattern_Partition.Source.Partition).Source).Query.ToString(); |
For M
|
1 2 3 |
string Partition_Pattern_Query_M = ((Microsoft.AnalysisServices.Tabular.CalculatedPartitionSource) (Pattern_Partition.Source.Partition).Source).Query.ToString(); |
Script steps
Now I have the first half of the SQL query, I have the building blocks for this last step of the partitioning process:
- Extract the information about all the partitions for which changes are required based on the content of the previously populated ETL_Tabular_Partitions_Required table. It stores the action flag that identifies what needs to be done with each of the partitions, too.
-
Connect to the tabular server in Azure and start looping through all the partitions and based on the action flag switch between these three options:
- Create AND process any partition (with the proper SQL query behind it) that’s needed but does not exist yet
- Delete partitions that are not needed anymore
- Process the ones that already exist but has incoming new data
Don’t forget that after the loop the tabular model must be saved and that is when all the previously issued commands are actually executed at the same time:
|
1 |
Tabular_Model.SaveChanges(); |
The code bits that you can customize to use in your own environment:
Wrap up
So, by now you should have an understanding of how partitioning works in tabular Azure Analysis Services and not just how the processing can be automated but the creation / removal of the partitions based on configuration data (instead of just defining all the partitions beforehand until e.g. 2030 for all months).
The scripts – as I said at the beginning – cannot be used just as they are due to the complexity of the Azure environment and that the solution includes more than just a bunch of SQL tables and queries: .NET scripts and Azure Analysis Services.
I aimed to use generic and descriptive variable and column names, but it could easily happen that I missed the explanation of something that became obvious to me during the development of this solution. In that case please feel free to get in touch with me using the comments section or sending an email to mi_technical@vivaldi.net
Thanks for reading!

Since then he has dealt with every component of the Microsoft BI stack (all the S-es) and now he's finding his way into the clouds, without being clouded by its marketed potential and staying realistic.
He has spent 9 years consulting for various clients in many different industries and he still enjoys dealing with the nitty-gritty troubleshooting (such as "Why doesn't this Azure DB connection manager work?"), modelling data warehouse / data marts and anything in between: requirements gathering/analysis, development, implementation, …
The experience he gathered throughout the years helped him becoming a Microsoft Certified Solutions Expert in the field of Business Intelligence.
He currently works for Farmlands, one of the largest agricultural cooperatives in New Zealand, developing and extending their data warehousing solutions.
View all posts by Istvan Martinka
- CDS for apps in the [POWER WORLD] - November 19, 2018
- Dynamic Partitioning in Azure Analysis Services (tabular) - August 6, 2018
- Connecting to Azure SQL Database - May 23, 2018